响应筛选的示例
Probe.jmp 样本数据表包含对 5800 个晶片测量的 387 个特征(响应列组)。批 ID 和晶片编号列唯一标识晶片。您关注在流程更改(流程)时哪些特征会显示不同的值。
1. 选择帮助 > 样本数据库,然后打开 Probe.jmp。
2. 选择分析 > 筛选 > 响应筛选。
将显示“响应筛选”启动窗口。
3. 选择 Responses 列组并点击 Y,响应。
4. 选择流程并点击 X。
5. 在 LogWorth 最大值框中输入 100。
Log worth 为 100 或更大值对应于极小的 p 值。设置“LogWorth 最大值”的值帮助控制图的尺度。
6. 点击确定。
将显示“响应筛选”报表以及包含支持信息的数据表。报表显示“FDR p 值图”,而且还包含两个其他的图报表。数据表包含 387 行,每一行分别对应您在 Y,响应所输入的 387 列。
“FDR p 值图”对于 387 个检验的每个检验显示两种 p 值:“FDR p 值”和“p 值”。这两种值是针对秩分数标绘的。“p 值”是流程-Y 检验的常规 p 值。“FDR p 值”是经过调整的 p 值,以确保伪发现率 (FDR) 不超过指定值(本例为 0.05)。FDR p 值用蓝色标绘,p 值用红色标绘。“秩分数”将 FDR p 值按从小到大(显著性降低)的顺序排名。
图上的水平蓝线和倾斜的红线是 FDR 显著性的阈值。针对假发现率进行调整后,FDR p 值位于蓝线下的检验在 0.05 水平下是显著的。针对假发现率进行调整后,普通 p 值位于红线下的检验在 0.05 水平下是显著的。这样,在图中可以通过任意一组 p 值了解 FDR 显著性。
图 21.2 针对流程执行的 387 个检验的“响应筛选”报表
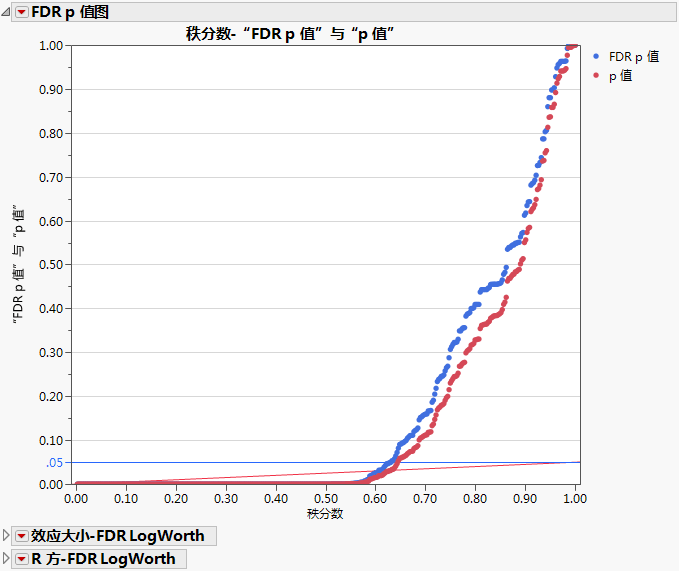
“FDR p 值图”显示 60% 以上的检验是显著的。少量检验从常规 p 值来看是显著的,但是从 FDR p 值来看它们不是显著的。这些检验对应于在红线上方和蓝线下方的红点。
为了识别在不同流程之间存在显著差异的特征,您可以在图中合适的点周围拖曳出一个矩形。这样会选中“PValues”表中对应于这些点的行,表中的第一列给出了特征的名称。您也可以在“PValues”表中选择相应的行。
“PValues”数据表包含 387 行,每一行分别对应于响应组中的每个响应测量指标。响应名称在名为 Y 的第一列中给出。每个响应都针对 X 列(即流程)中的效应进行检验。
图 21.3 “PValues”数据表,部分视图
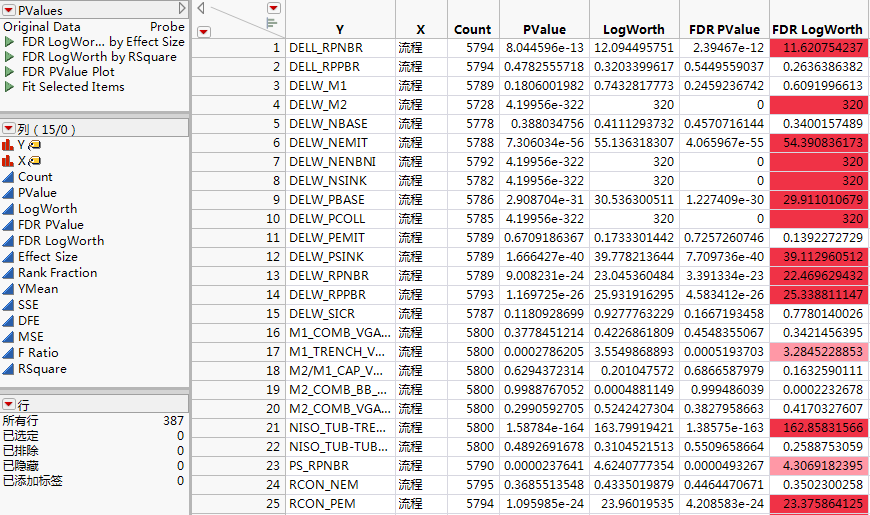
其余列给出有关 X-Y 检验的信息。在此处检验是单因子方差分析。除了其他信息外,该表还给出检验的 p 值、LogWorth、FDR(假发现率)p 值和 FDR LogWorth。使用该表可按各种统计量排序、选择行或针对感兴趣的变量进行作图。
请注意,对应于 p 值 1e-100 或更小的 LogWorth 和 FDR LogWorth 值报告为 100,因为您在启动窗口中将“LogWorth 最大值”设置为 100。此外,对应于大于 2 的 FDR LogWorth 值的单元格采用强度梯度着色。
有关报表和 PValues 表的详细信息,请参见“响应筛选”报表。