发布日期: 04/13/2021
在“拟合模型”中启动“响应筛选”
选择分析 > 拟合模型。输入您的 Y 变量和模型效应。从“特质”列表中选择响应筛选。
图 21.10 “拟合模型”窗口中的“响应筛选”
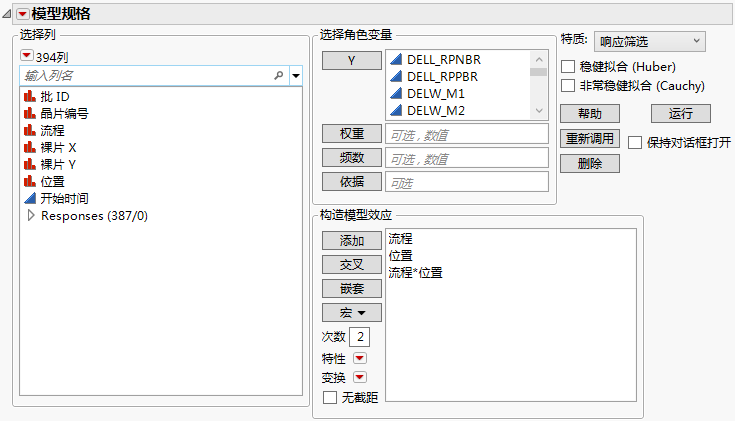
有关“选择列”红色小三角菜单中选项的详细信息,请参见《使用 JMP》中的“列过滤器”菜单。
有两个选项可用于稳健估计:
稳健拟合 (Huber)
使用稳健 (Huber) 估计来减小连续响应离群值的权重。若无离群值,这些估计值接近最小二乘估计值。请注意该选项会增加处理时间。
非常稳健拟合 (Cauchy)
指定非常稳健 (Cauchy) 估计来减小连续响应离群值的权重。假定误差服从 Cauchy 分布。Cauchy 分布具有比正态分布更肥大的尾部,从而弱化了对离群值的强调。若您的数据中有较大比例的离群值,该选项会很有用。不过,若您的数据接近正态,只含有少数离群值,该选项会导致不正确的推断。Cauchy 选项使用最大似然和 Cauchy 连结函数估计参数。
提示:若同时选择了两个稳健选项,则平台仅使用 Cauchy 估计。
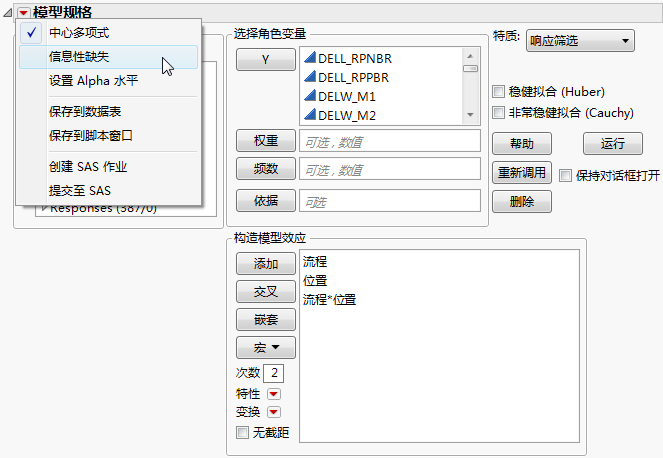
信息性缺失选项提供缺失值的编码系统。尽管存在缺失值,“信息性缺失”编码允许预测模型的估计。这在缺失数据可提供信息的情形中很有用。从“模型规格”红色小三角菜单中选择该选项。
图 21.11 “信息性缺失”选项
有关“拟合模型”窗口的详细信息,请参见《拟合线性模型》中的启动“拟合模型”平台。
需要更多信息?有问题?从 JMP 用户社区得到解答 (community.jmp.com).