编码示例
Reactor 20 Custom.jmp 样本数据表包含来自 20 次试验设计的数据,该设计是使用“定制设计”平台构造的。实验针对某化学过程调查五个因子对产量响应(反应百分比)的影响。
1. 选择帮助 > 样本数据库,然后打开 Design Experiment/Reactor 20 Custom.jmp。
2. 在“表”面板中,点击实验设计对话框脚本旁边的绿色小三角。
3. 打开因子分级显示项。
Reactor 20 Custom.jmp 中使用的设计的“因子”分级显示项
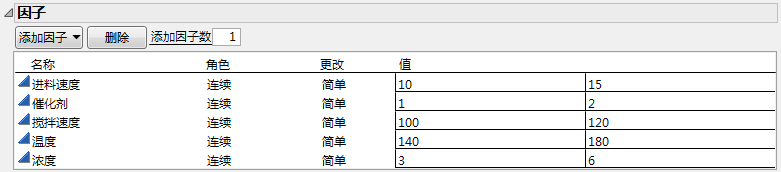
请注意温度的设置范围从 140 到 180。生成设计时,已将“编码”列属性分配给温度。“低值”设置为 140,“高值”设置为 180。
4. 关闭“定制设计”窗口。
5. 在 Reactor 20 Custom.jmp 样本数据表中,点击列面板中温度旁边的星号,然后选择编码。
随即显示“列信息”窗口并显示“编码”列属性面板。您可以看到 JMP 构造设计表时添加了列属性,指定了“低值”和“高值”。事实上,通过重复该步骤,您可以验证 JMP 为全部五个因子添加了“编码”属性。
“温度”的“编码”面板
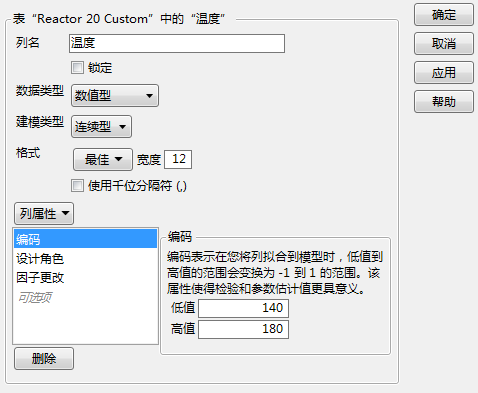
6. 点击取消以关闭“列信息”窗口。
7. 在 Reactor 20 Custom.jmp 样本数据表中,点击简化模型脚本旁边的绿色小三角。
该脚本拟合仅包含五个效应的模型,基于完整模型的分析这些效应被确定为显著。
8. 点击运行。
简化模型的“效应汇总”报表
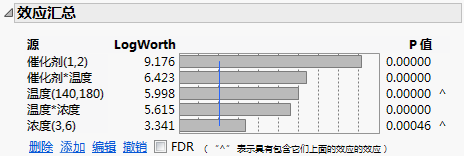
在“源”列表中,“编码”列属性中使用的高值和低值显示在主效应(催化剂、温度和浓度)右侧的括号中。没有为交互作用效应显示“编码”属性应用的范围。
提示:请注意温度和浓度对应 P 值右侧的“^”符号。这些符号指示这些主效应是具有更小 p 值的交互作用效应的分量效应。若模型中包含交互作用效应,则效应遗传原则要求所有分量效应也包括在模型中。请参见效应遗传。
9. 点击“响应‘反应百分比’”红色小三角并选择估计值 > 显示预测表达式。
查看“预测表达式”分级显示项以了解编码如何影响预测公式。
简化模型的预测表达式

每个因子按“编码”列属性的指定进行变换。例如,对于温度,注意以下事项:
‒ “编码”属性中的“低值”设置为 140。温度值 140 会变换为 -1。
‒ “编码”属性中的“高值”设置为 180。温度值 180 会变换为 +1。
‒ 低值和高值的中点值是 160。温度值 160 会变换为 0。
变换后的值可帮助您比较效应。催化剂的估计系数为 9.942,浓度的估计系数为 -3.077。由此得出结论:催化剂对反应百分比的预测效应是浓度对反应百分比的效应的三倍多。此外,这些系数指示预测的反应百分比随着催化剂的增加而增加,随着浓度的增加而降低。
变换后的值可帮助您解释系数:
• 所有因子处于中点值时,变换后的值为 0。预测的反应百分比是截距,即 65.465。
• 催化剂和浓度处于中点值时,温度增加 20 个单位导致反应百分比增加 5.558 个单位。
• 假定浓度位于其中点值,因此变换后的值为 0:
‒ 催化剂位于中点值时,温度增加 20 个单位导致反应百分比增加 5.558 个单位。
‒ 催化剂采用高值设置时,温度增加 20 个单位导致反应百分比增加 5.558 + 6.035 = 11.593 个单位。
由此得出结论:交互作用项的系数 6.035 是对应催化剂变化 0.5 个单位,预测的反应百分比模型的斜率增量。