发布日期: 08/07/2020
估计方法
REML
当数据包含缺失值时,与 ML(最大似然)估计方法相比,REML(限制最大似然)估计值的偏倚更小。REML 方法基于误差对比将边缘似然最大化。REML 方法经常用于估计方差和协方差。“主成分”平台中的 REML 方法与针对重复测量数据(具有非结构化协方差矩阵)使用的混合模型的 REML 估计相同。有关混合模型的 REML 估计的信息,请参见 SAS Institute Inc. (2018e) 中的“MIXED 过程”一章。
稳健
该方法实际上通过极大地降低所有离群值的权重来忽略它们。使用以下权重执行一系列迭代再加权数据拟合:
若 Q < K,则 wi = 1.0;其他情况下 wi = K/Q
在此,K 是一个等于卡方分布的 0.75 分位数的常数,该分布的自由度等于数据表中的列数。Q 定义如下:
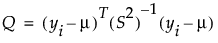
在该等式中,yi = 第 i 个观测的响应,μ = 均值向量的当前估计值,S2 = 协方差矩阵的当前估计值,T = 转置矩阵运算。最后一步是减小方差矩阵的偏倚。
这是一个折衷方法:当数据中的离群值不多时,您可以得到较高的方差估计值;但当数据确实包含离群值时,您可以得到准确得多的方差估计值。
需要更多信息?有问题?从 JMP 用户社区得到解答 (community.jmp.com).