发布日期: 08/07/2020
 包含分类响应的 K 最近邻的示例
包含分类响应的 K 最近邻的示例
您有关于已申请房屋净值贷款的 5,960 个客户的历史财务数据。每个客户都被归入“良性风险”或“不良风险”两类。很多预测变量有缺失值。您想要构造模型,用于对将来客户的信用风险分类。
1. 选择帮助 > 样本数据库,然后打开 Equity.jmp。
2. 选择分析 > 预测建模 > K 最近邻。
3. 选择不良并点击 Y,响应。
4. 从贷款一直选到交易记录数,然后点击 X,因子。
由于其中一个潜在预测变量负债收入比有很多缺失值,所以您没有将其包含在模型内。连续预测变量的缺失值用该预测变量的平均值替代。该过程有时对于随机缺失的值很有效。尽管负债收入比的高缺失率指示缺失可能是信息性的,但是我们在本例中不调查它。
5. 选择验证并点击验证。
6. 点击确定。
“K 最近邻”报表
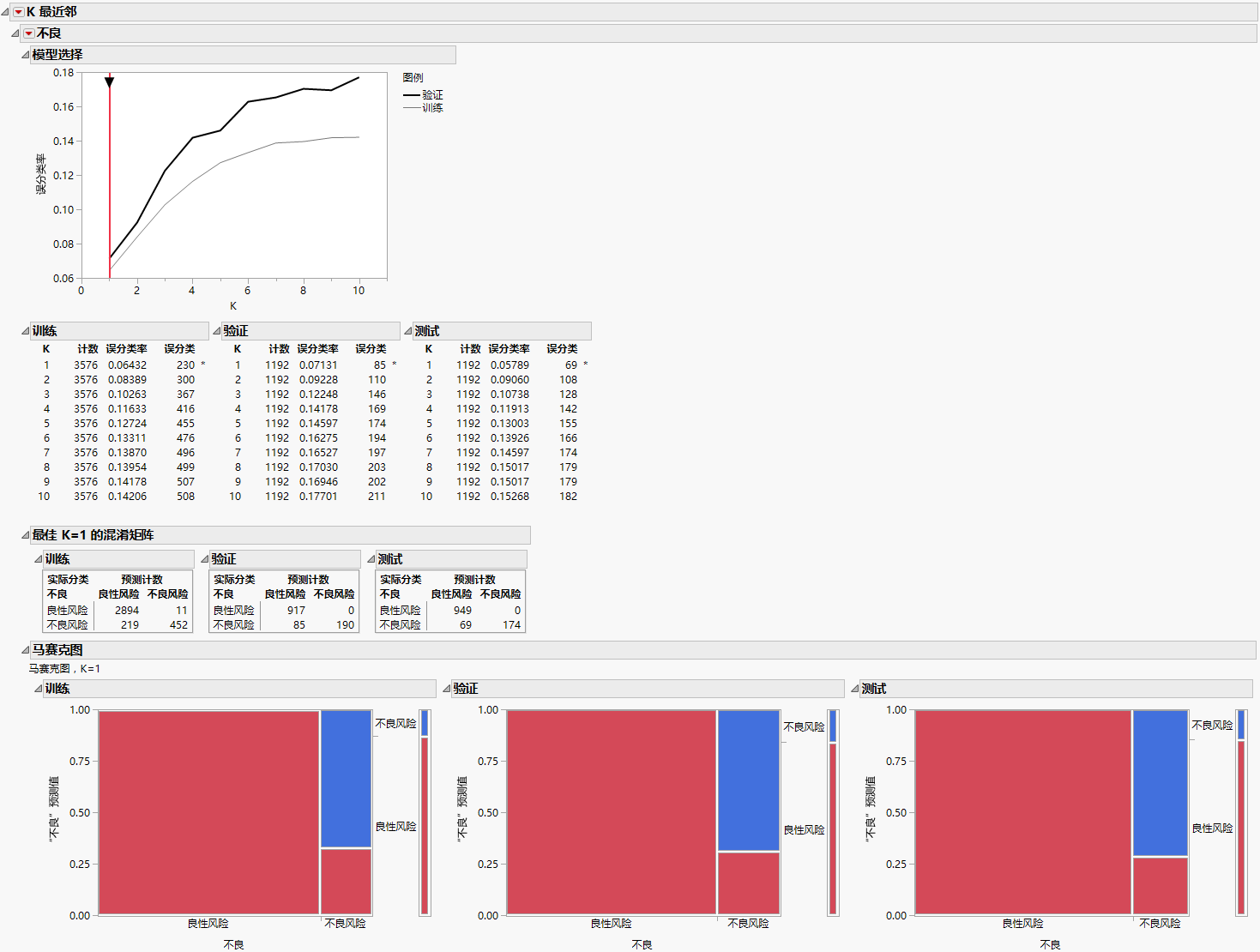
对于 K 的每个值,JMP 仅使用训练集观测构造模型。这些模型均用于对验证集观测分类。使用验证集结果来选择最佳模型。在本例中,基于单个最近邻 (K = 1) 的模型的误分类率最小。测试集确认这一单个最近邻模型对于独立数据的效果最佳。
7. 点击不良红色小三角并选择发布预测公式。
8. 在近邻数,K 旁边,保留默认值 1。
9. 点击确定。
预测方程保存在“公式存储库”中。您可以使用“公式存储库”中的“模型比较”选项比较发布到“公式存储库”中的备择模型和 K = 1 最近邻模型的效果。请参见公式存储库。
需要更多信息?有问题?从 JMP 用户社区得到解答 (community.jmp.com).