发布日期: 08/07/2020
 支持向量机示例
支持向量机示例
您有 442 名糖尿病患者的基准医疗数据,还有在每名患者首次就诊一年后得到的糖尿病疾病发展的二值型测度。该测度将疾病发展量化为“Low”或“High”。您想构造一个分类模型以便预测未来患者的疾病发展为“High”还是“Low”。您想要探索核函数选项。
1. 选择帮助 > 样本数据库,然后打开 Diabetes.jmp。
2. 选择分析 > 预测建模 > 支持向量机。
3. 选择 Y 二值型并点击 Y,响应。
4. 从年龄一直选到葡萄糖,然后点击 X,因子。
5. 选择验证并点击验证。
6. 点击确定。
7. 在“模型启动”控制面板中,检查核函数是否为成本参数为 1 且 Gamma 参数为 0.1 的“径向基函数”。
8. 点击执行。
9. 点击“模型启动”旁边的灰色小三角以打开“模型启动”控制面板。
10. 将核函数改为成本参数为 1 的线性函数。
11. 点击执行。
“模型比较”报表
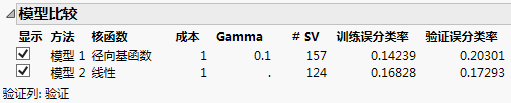
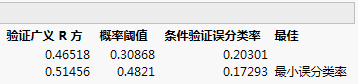
“模型比较”报表显示:在误分类率方面,最佳模型是具有线性核函数且成本参数为 1 的模型。这是要进一步分析的模型。
12. 滚动至“支持向量机模型 2”报表。
“最佳拟合模型”的模型报表
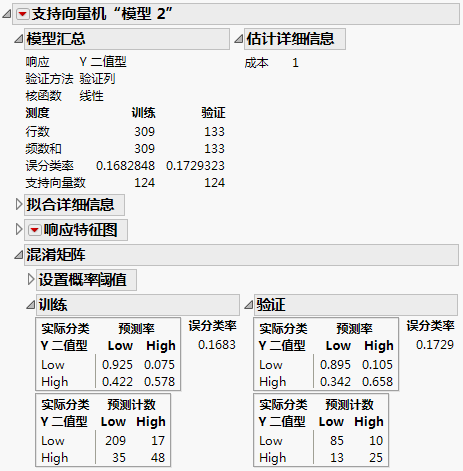
“模型汇总”报表显示,训练集和验证集的误分类率非常相似。这是一个很好的迹象,表明模型并没有过度拟合数据。混淆矩阵提供了关于模型误分类的观测类型的详细信息。在混淆矩阵中,左上角显示:该模型在大多数情况下正确分类了 Low 响应(训练集中为 92%,验证集中为 89.5%)。然而,正确分类的“High”响应较少(训练集中为 57.8%,验证集中为 65.8%)。因此,大多数误分类是被误分类为 Low 的 High 响应。
需要更多信息?有问题?从 JMP 用户社区得到解答 (community.jmp.com).