发布日期: 08/07/2020
“响应筛选”平台的统计详细信息
假发现率
所有“响应筛选”图涉及使用 Benjamini and Hochberg (1995) 中所述 FDR 方法执行的检验的 p 值。另见 Westfall et al. (2011)。该方法假定 p 值是独立的,且均匀分布。
JMP 使用以下步骤控制 α 水平上的假发现率:
1. 执行 m 个相关假设检验以获取 p 值 p1, p2,..., pm。
2. 按从小到大的顺序将 p 值排名。用 p(1) ≤ p(2) ≤ ... ≤ p(m) 表示这些值。
3. 找到 p(i) ≤ (i/m)α 最大的 p 值。假定这第一个 p 值是第 k 个最大 p(k)。
4. 拒绝与 p 值小于等于 p(k)) 关联的 k 个假设。
该过程确保假发现率不超过 α。
针对假发现率调整的 p 值(表示为 p(i), FDR),按以下方式计算:
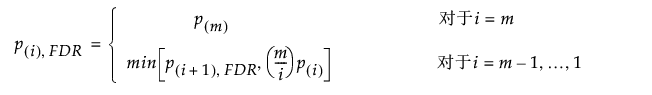
若某个假设具有小于 α 的 FDR 调整的 p 值,则过程拒绝该假设。
需要更多信息?有问题?从 JMP 用户社区得到解答 (community.jmp.com).