 “结构化方程模型”平台的统计详细信息
“结构化方程模型”平台的统计详细信息
 拟合汇总测度的统计详细信息
拟合汇总测度的统计详细信息
 AICc 和 BIC
AICc 和 BIC
AICc 和 BIC 的公式如下:
AICc = 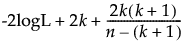
BIC = 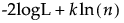
其中:
‒ -2logL 是负对数似然的两倍。
‒ n 是样本大小。
‒ K 是参数个数。
有关“模型比较”报表中基于似然的测度的详细信息,请参见《拟合线性模型》中的似然、AICc 和 BIC。
 CFI
CFI
比较拟合指数 (CFI) 计算如下:
CFI = 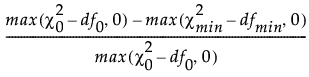
其中:
‒ 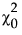 是独立模型的卡方统计量。
是独立模型的卡方统计量。
‒ df0 是独立模型的自由度。
‒ 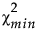 是拟合模型的卡方统计量。
是拟合模型的卡方统计量。
‒ dfmin 是拟合模型的自由度。
有关 CFI 的详细信息,请参见 Bentler (1990)。
 TLI
TLI
Tucker-Lewis 指数 (TLI) 定义如下:
TLI = 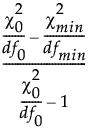
其中:
‒ 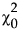 是独立模型的卡方统计量。
是独立模型的卡方统计量。
‒ df0 是独立模型的自由度。
‒  是拟合模型的卡方统计量。
是拟合模型的卡方统计量。
‒ dfmin 是拟合模型的自由度。
详细信息,请参见 West et al. (2012)。
 NFI
NFI
Bentler-Bonett 规范拟合指数 (NFI) 定义如下:
NFI = 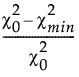
其中:
‒ 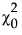 是独立模型的卡方统计量。
是独立模型的卡方统计量。
‒  是拟合模型的卡方统计量。
是拟合模型的卡方统计量。
详细信息,请参见 West et al. (2012)。
 修正的 GFI 和修正的 AGFI
修正的 GFI 和修正的 AGFI
修正的拟合优度指数(修正的 GFI)定义如下:
修正的 GFI = 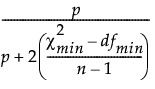
其中:
‒ 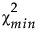 是拟合模型的卡方统计量。
是拟合模型的卡方统计量。
‒ dfmin 是拟合模型的自由度。
‒ p 是拟合模型的观测变量数。
‒ n 是样本大小。
修正的拟合优度指数(修正的 AGFI)定义如下:
修正的 AGFI = 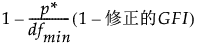
其中:
‒ p* 是协方差矩阵中唯一条目数和观测变量的均值向量。
‒ dfmin 是拟合模型的自由度。
详细信息,请参见 West et al. (2012)。
 RMSEA
RMSEA
近似的均方根误差 (RMSEA) 计算如下:
RMSEA = 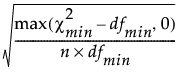
其中:
‒ n 是样本大小。
‒ dfmin 是拟合模型的自由度。
‒ 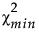 是拟合模型的卡方统计量。
是拟合模型的卡方统计量。
利用非中心卡方分布的累积分布函数 Φ(x|λ, d) 计算 RMSEA 的置信限。90% 置信限计算如下:
下限 = 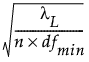
上限 = 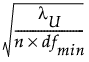
其中:
‒ λL 满足 Φ(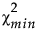 |λL, dfmin) = 0.95。
|λL, dfmin) = 0.95。
‒ λU 满足 Φ(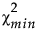 |λU, dfmin) = 0.05。
|λU, dfmin) = 0.05。
详细信息,请参见 Maydeu-Olivares et al. (2017)。
 RMR 和 SRMR
RMR 和 SRMR
RMR 和 SRMR 的公式如下:
RMR = 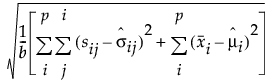
SRMR = 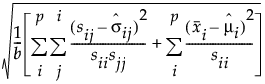
其中:
‒ p 是显变量数。
‒ b 是观测变量的协方差矩阵和均值向量中的唯一条目数:
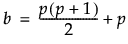
‒ sij 是输入协方差矩阵的第 (i, j) 个元素。
‒ 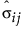 是预测协方差矩阵的第 (i, j) 个元素。
是预测协方差矩阵的第 (i, j) 个元素。
‒ 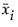 是样本均值向量的第 i 个元素。
是样本均值向量的第 i 个元素。
‒ 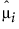 是向量预测均值的第 i 个元素。
是向量预测均值的第 i 个元素。
有关详细信息,请参见 SAS Institute Inc. (2018a) 中的“CALIS 过程”一章。