 “支持向量机模型”报表
“支持向量机模型”报表
响应特征图
给出分类模型的可视化表示。图上的点是实际的数据观测。对于绘制的两个变量,阴影轮廓表示由其余模型因子的固定值确定的预测空间的平面。预测基于平台计算的分类决策规则。固定值控件位于图上方。使用滑块或数字框更改因子的固定值时,绘制的变量的预测空间将自动更新。也可以使用每个轴上的红色小三角更改绘图轴以显示任何连续因子。
“响应特征图”红色小三角菜单包含一个用于更改图的网格密度的选项。该选项确定阴影轮廓下预测网格的精细度。较高的网格密度提供较平滑的决策线。
模型汇总
给出响应列的名称、验证方法以及模型拟合中使用的核函数的类型。“模型汇总”表还包含有关训练集、验证集和测试集的模型拟合的信息。报告每个集的观测数、误分类率和支持向量数。误分类率是模型误分类的观测比例。该比率通过用误分类数除以观测总数计算得出。
估计详细信息
给出模型中使用的参数值。
拟合详细信息
提供训练集以及验证集和测试集(若已指定)的以下统计量:
熵 R 方
比较拟合模型和恒定概率模型的对数似然的一种拟合测度。熵 R 方的范围介于 0 到 1 之间,其中接近 1 的值指示拟合更佳。请参见熵 R 方。
广义 R 方
可以应用到一般回归模型的测度。它基于似然函数 L,并且统一尺度后最大值为 1。对于标准最小二乘设置中的连续正态响应,“广义 R 方”测度简化为传统 R 方。“广义 R 方”亦称 Nagelkerke/Craig and Uhler R2,它是 Cox and Snell 伪 R2 的标准化版本。请参见 Nagelkerke (1991)。值越接近 1 指示拟合效果越好。
-Log p 均值
-log(p) 的平均值,其中 p 是与发生的事件有关的拟合概率。值越小指示拟合效果越好。
RASE
均方预测误差的平方根(平均平方根误差)。RASE 计算如下,其中源指示训练集、验证集或测试集。
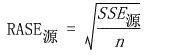
绝对偏差的均值
响应的真实值与预测值的差值绝对值的平均值。差值介于 1 和 p(实际发生的响应水平的拟合概率)之间。值越小指示拟合效果越好。
误分类率
具有最高拟合概率的响应类别不是观测到的类别的比率。
“拟合详细信息”报表中的误分类率可能与“混淆矩阵”报表中的误分类率不一致。当响应为二值响应时,“拟合详细信息”报表中的比率使用概率截止值 0.5,但是“混淆矩阵”报表中的比率使用概率阈值作为截止值。
数目
观测数。
混淆矩阵
为模型中指定的每个集(训练集、验证集和测试集)显示一个混淆矩阵。混淆矩阵是实际响应和预测响应的双向分类。使用混淆矩阵和误分类率来评估您的模型。
混淆矩阵和误分类率使用概率阈值框中的值作为截止值。默认情况下,该值基于平台计算的分类决策规则。可以通过拖动滑块或在“概率阈值”旁边的框中输入新值来更改截止值。若更改概率阈值,混淆矩阵和误分类率将自动更新。“模型比较”报表中的概率阈值和条件验证误分类率列也随之更新。