All tests compare the fit of the specified model with subset or superset models, as illustrated in Relationship of Statistical Tables. If a test shows significance, then the higher order model is justified.

Shows an interactive report that allows you to add or remove effects from the model. See Effect Summary Report.
If your model contains a single continuous effect, then a logistic report similar to the one in Fit Y By X appears. See the Basic Analysis book for an interpretation of these plots.

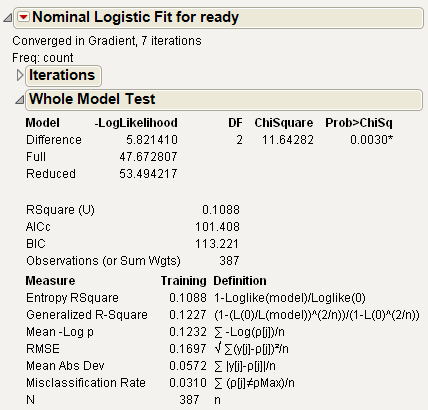
Lists the model labels called Difference (difference between the Full model and the Reduced model), Full (model that includes the intercepts and all effects), and Reduced (the model that includes only the intercepts).
Difference is the difference between the Reduced and Full models. It measures the significance of the regressors as a whole to the fit.
Full describes the negative log-likelihood for the complete model.
Reduced describes the negative log-likelihood that results from a model with only intercept parameters. For the ingot experiment, the –LogLikelihood for the reduced model that includes only the intercepts is 53.49.
Shows the R2, which is the ratio of the Difference to the Reduced negative log-likelihood values. It is sometimes referred to as U, the uncertainty coefficient, or as McFadden’s pseudo R2. RSquare ranges from zero for no improvement to 1 for a perfect fit. A Nominal model rarely has a high RSquare, and it has a RSquare of 1 only when all the probabilities of the events that occur are 1.
Corrected Akaike Information Criterion. For more details, see Likelihood, AICc, and BIC in Statistical Details.
Bayesian Information Criterion. For more details, see Likelihood, AICc, and BIC in Statistical Details.
(or Sum Wgts) Total number of observations in the sample.
Entropy RSquare is the same as RSquare (U) explained above.
Generalized RSquare is a measure that can be applied to general regression models. It is based on the likelihood function L and is scaled to have a maximum value of 1. The Generalized RSquare measure simplifies to the traditional RSquare for continuous normal responses in the standard least squares setting. Generalized RSquare is also known as the Nagelkerke or Craig and Uhler R2, which is a normalized version of Cox and Snell’s pseudo R2. See Nagelkerke (1991).
Mean -Log p is the average of -log(p), where p is the fitted probability associated with the event that occurred.
RMSE is the root mean square error, where the differences are between the response and p (the fitted probability for the event that actually occurred).
Mean Abs Dev is the average of the absolute values of the differences between the response and p (the fitted probability for the event that actually occurred).
Misclassification Rate is the rate for which the response category with the highest fitted probability is not the observed category.
After fitting the full model with two regressors in the ingots example, the –LogLikelihood on the Difference line shows a reduction to 5.82 from the Reduced –LogLikelihood of 53.49. The ratio of Difference to Reduced (the proportion of the uncertainty attributed to the fit) is 10.9% and is reported as the Rsquare (U).
The next questions that JMP addresses are whether there is enough information using the variables in the current model or whether more complex terms need to be added. The Lack of Fit test, sometimes called a Goodness of Fit test, provides this information. It calculates a pure-error negative log-likelihood by constructing categories for every combination of the regressor values in the data (Saturated line in the Lack Of Fit table), and it tests whether this log-likelihood is significantly better than the Fitted model.

The Saturated degrees of freedom is m–1, where m is the number of unique populations. The Fitted degrees of freedom is the number of parameters not including the intercept. For the Ingots example, these are 18 and 2 DF, respectively. The Lack of Fit DF is the difference between the Saturated and Fitted models, in this case 18–2=16.
The Lack of Fit table lists the negative log-likelihood for error due to Lack of Fit, error in a Saturated model (pure error), and the total error in the Fitted model. Chi-square statistics test for lack of fit.
In this example, the lack of fit Chi-square is not significant (Prob>ChiSq = 0.617) and supports the conclusion that there is little to be gained by introducing additional variables, such as using polynomials or crossed terms.

The Likelihood Ratio Tests command produces a table like the one shown here. The Likelihood-ratio Chi-square tests are calculated as twice the difference of the log-likelihoods between the full model and the model constrained by the hypothesis to be tested (the model without the effect). These tests can take time to do because each test requires a separate set of iterations.
