|
•
|
|
•
|
|
•
|
|
•
|
|
•
|
|
•
|
|
•
|
|
•
|
|
•
|
|
1.
|
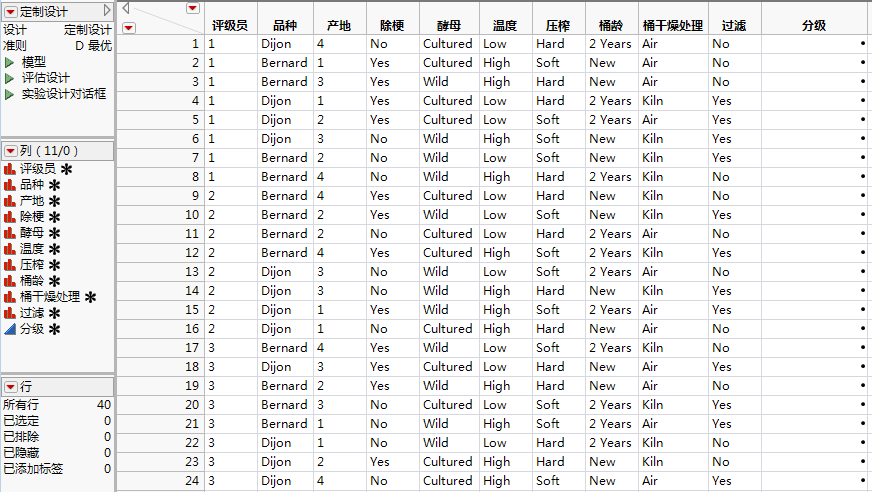
选择实验设计 > 定制设计。
|
|
2.
|
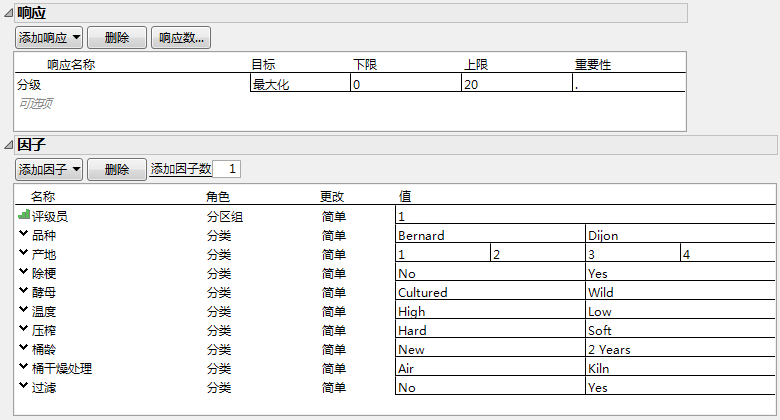
已完成的“响应”和“因子”分级显示项显示完成的“响应”分级显示项。
|
1.
|
|
2.
|
请注意,“角色”设置为“分区组”。还请注意,只为“值”显示了一个设置。这是因为在尚未指定所需的试验次数之前无法确定区组数。一旦在“生成设计”分级显示项中指定了“试验次数”,评级员水平数即更新为所需数目。
|
3.
|
|
4.
|
|
6.
|
点击添加因子 > 分类 > 4 水平。
|
|
7.
|
|
9.
|
|
10.
|
|
12.
|
|
13.
|
|
‒
|
酵母(Cultured 和 Wild)
|
|
‒
|
温度(High 和 Low)
|
|
‒
|
压榨(Hard 和 Soft)
|
|
‒
|
桶龄(New 和 Two Years)
|
|
‒
|
桶干燥处理(Air 和 Kiln)
|
|
‒
|
过滤(No 和 Yes)
|
|
14.
|
点击继续。
|
|
•
|
|
•
|
|
•
|
|
1.
|
|
2.
|
从“定制设计”红色小三角菜单中,选择加载因子。
|
|
•
|
|
•
|
|
•
|
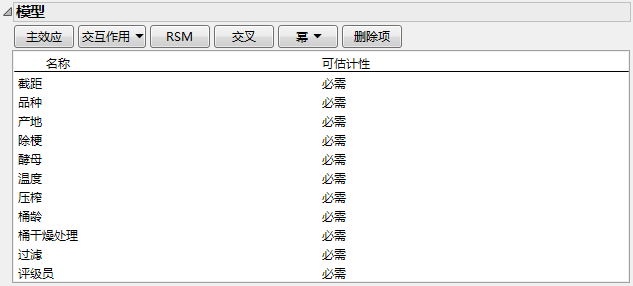
“别名项”分级显示项指定要显示在之后出现的“别名矩阵”中的效应。请参见别名矩阵。“别名矩阵”显示模型项与“别名项”分级显示项所列的效应之间的别名关系。打开“别名项”分级显示节点以验证是否已列出所有双因子交互作用。
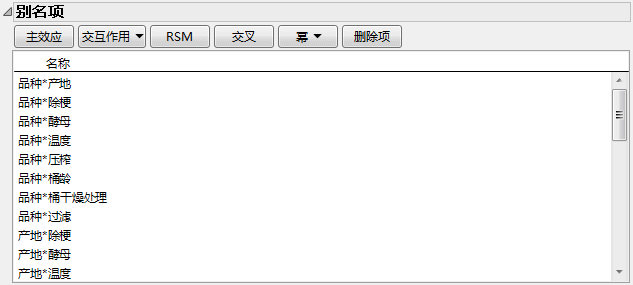
在下一步中,您需要生成设计。由于“定制设计”算法是从随机起始设计开始的,所以您的设计可能与葡萄酒实验设计中显示的设计有所不同。 若要获得具有完全相同的试验和试验顺序的设计,请执行以下步骤:
|
1.
|
从“定制设计”红色小三角菜单中,选择设置随机种子。
|
|
3.
|
点击确定。
|
|
4.
|
|
5.
|
|
6.
|
点击确定。
|
|
1.
|
|
2.
|
点击制作设计。
|
相关性色图显示“模型”或“别名项”分级显示项中显示的任意两个效应之间的相关性绝对值。(相关性色图中显示的颜色为 JMP 默认颜色。)
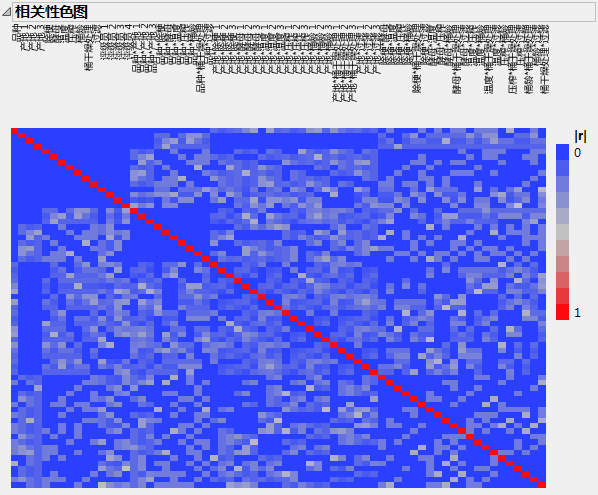
相关性色图中唯一的红色位于主对角线上。红色指示绝对相关性为 1,它反映出每个项都与其自身完全相关。由此断定没有任何主效应与任何双因子交互作用完全混杂。事实上,主效应与双因子交互作用相关性的绝对值相当低。这意味着主效应估计值因为存在活跃的双因子交互作用而只产生轻微的偏倚。
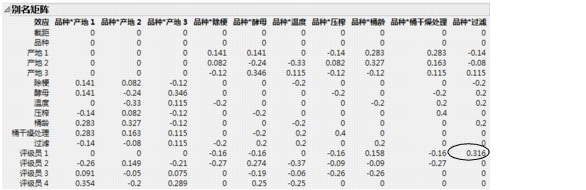
例如,考虑模型效应桶干燥处理。若品种*压榨活跃,则桶干燥处理效应的期望估计值不同于该效应的无偏估计值。其差值是品种*压榨效应的 0.4 倍。因此,看起来显著的桶干燥处理估计效应实际上可能是显著的品种*压榨效应。
“设计诊断”分级显示项提供有关设计效率的信息。效率测度将您的设计与可能并不存在的理论最优设计加以对比。效率值是您设计的效率与该最优设计的效率之比,表示为百分比。有关效率测度的详细信息,请参见估计效率。
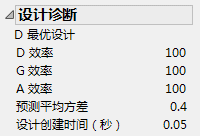
“设计诊断”分级显示项的第一行指示构造设计是为优化 D 效率准则。有关更多详细信息,请参见定制设计选项中的“最优性准则”说明。 在这种情况下,您的设计具有 100% 的 D 效率。