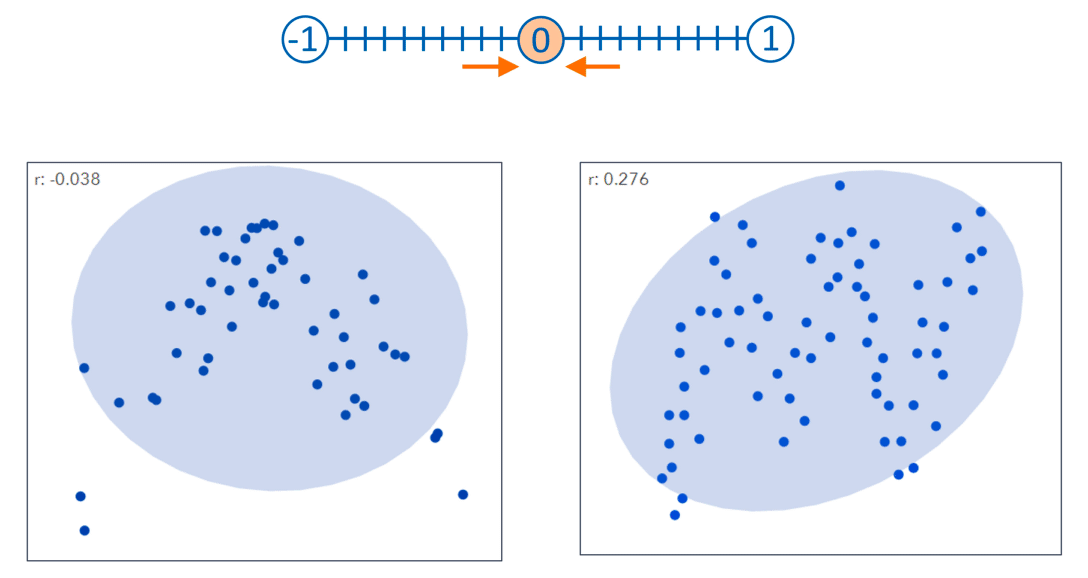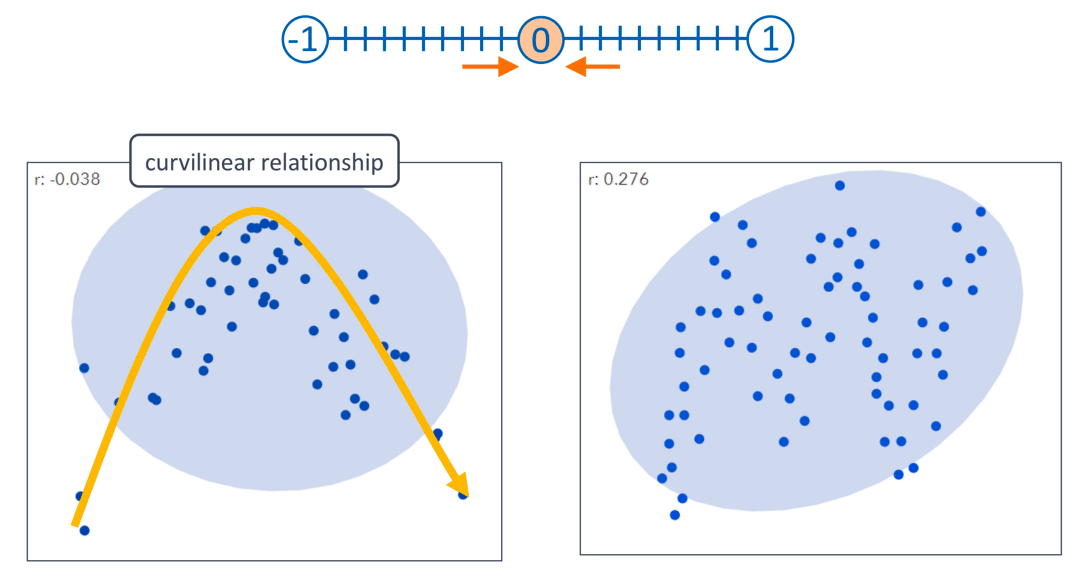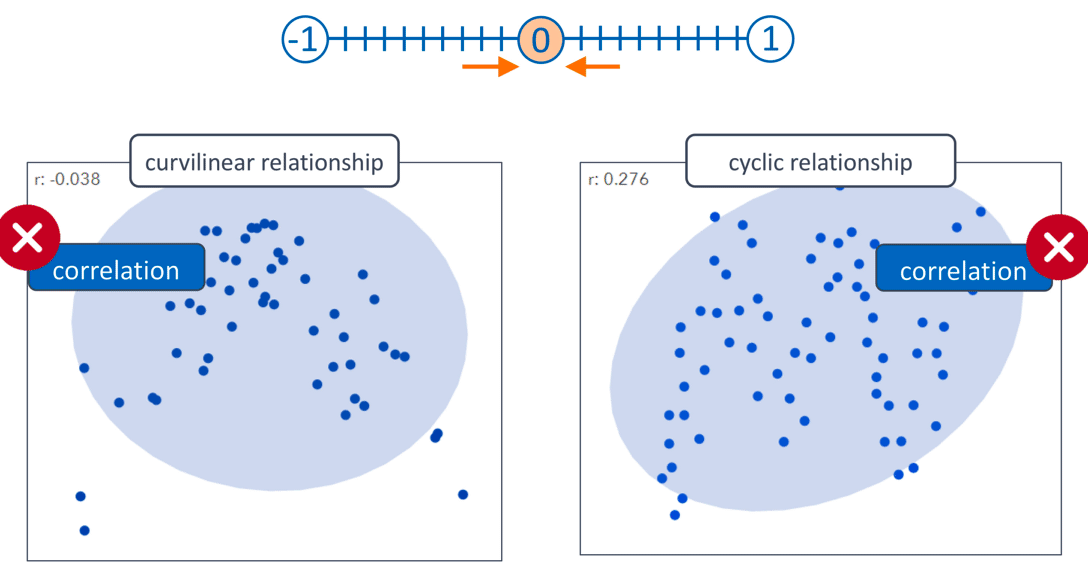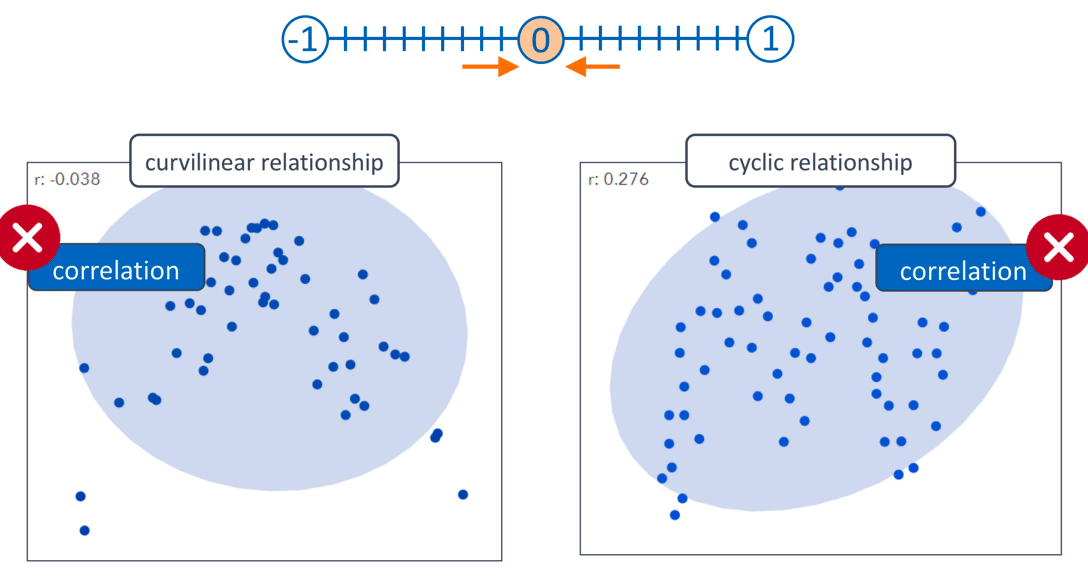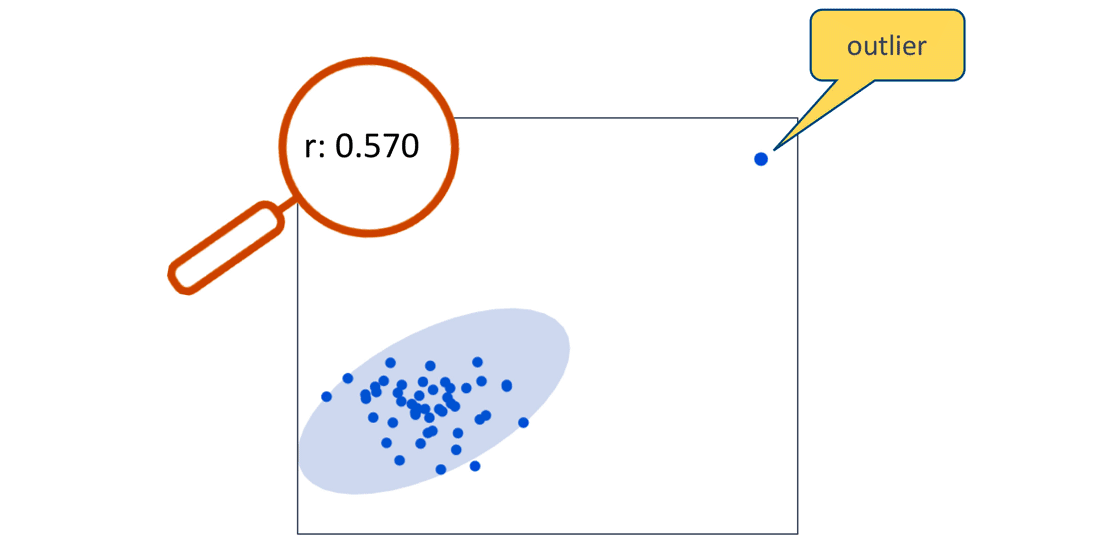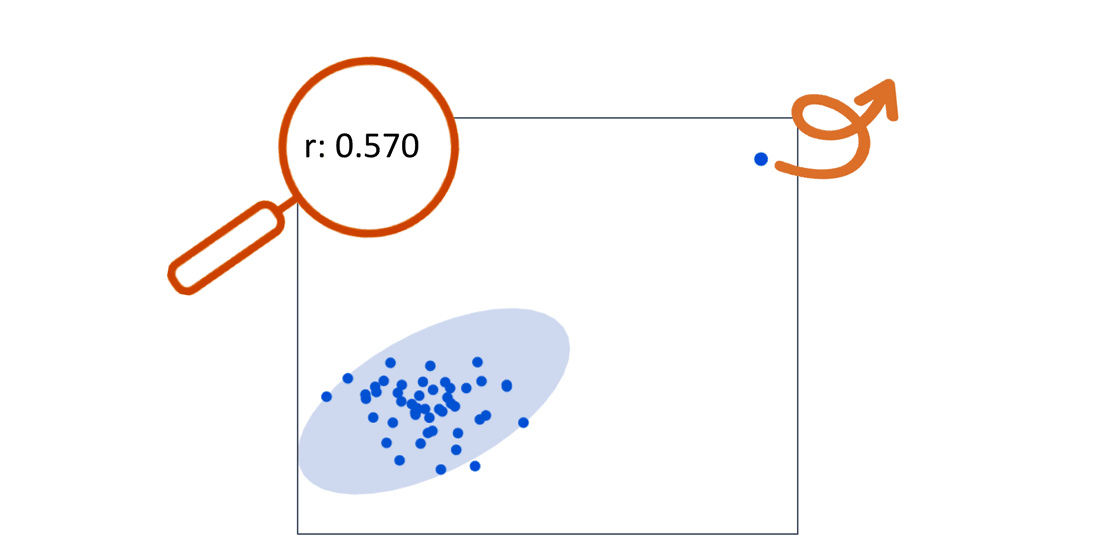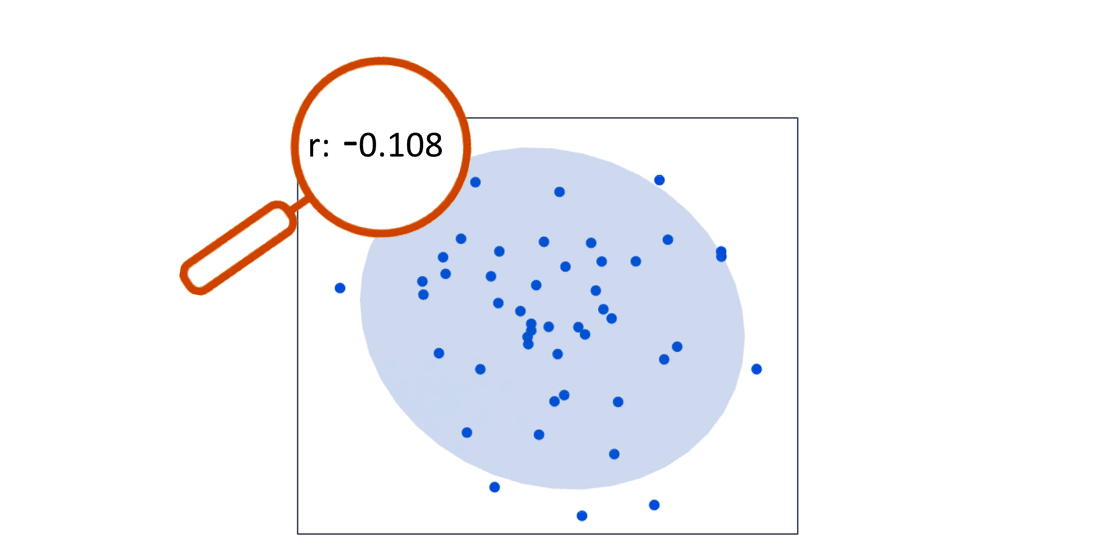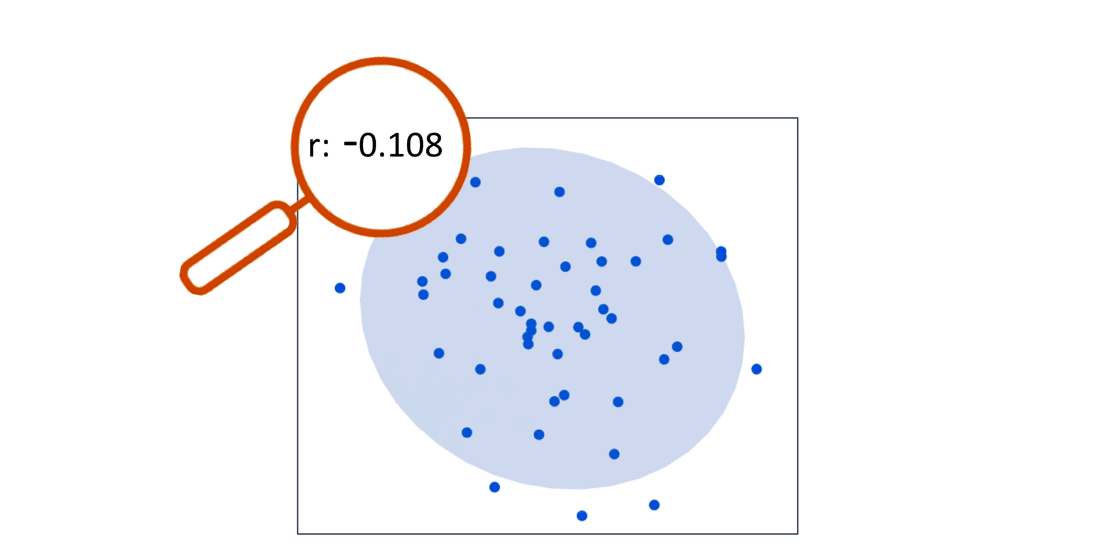

The Sum of Products calculation and the location of the data points in our scatterplot are intrinsically related.
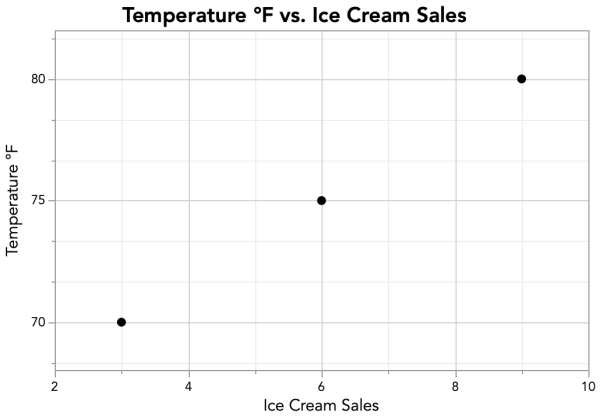
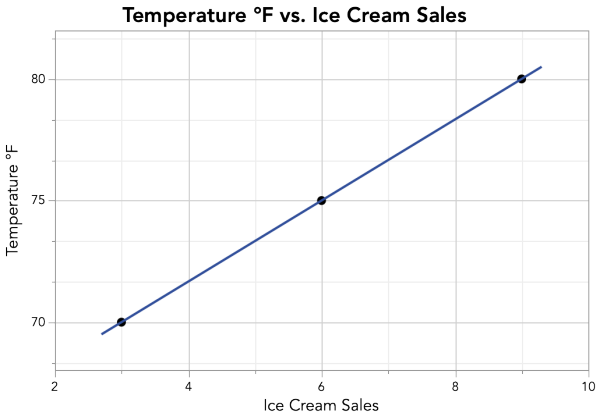
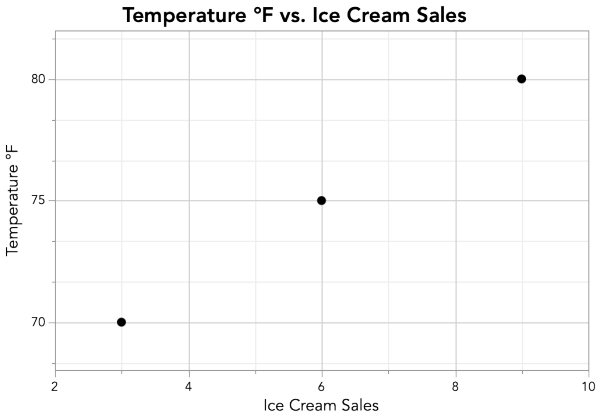
Notice that the Sum of Products is positive for our data. When the Sum of Products (the numerator of our correlation coefficient equation) is positive, the correlation coefficient r will be positive, since the denominator—a square root—will always be positive. We know that a positive correlation means that increases in one variable are associated with increases in the other (like our Ice Cream Sales and Temperature example), and on a scatterplot, the data points angle upwards from left to right. But how does the Sum of Products capture this?
- The only way we will get a positive value for the Sum of Products is if the products we are summing tend to be positive.
- The only way to get a positive value for each of the products is if both values are negative or both values are positive.
- The only way to get a pair of two negative numbers is if both values are below their means (on the bottom left side of the scatter plot), and the only way to get a pair of two positive numbers is if both values are above their means (on the top right side of the scatter plot).
So, the Sum of Products tells us whether data tend to appear in the bottom left and top right of the scatter plot (a positive correlation), or alternatively, if the data tend to appear in the top left and bottom right of the scatter plot (a negative correlation).