 Launch the K Nearest Neighbors Platform
Launch the K Nearest Neighbors Platform
Launch the K Nearest Neighbors platform by selecting Analyze > Predictive Modeling > K Nearest Neighbors.
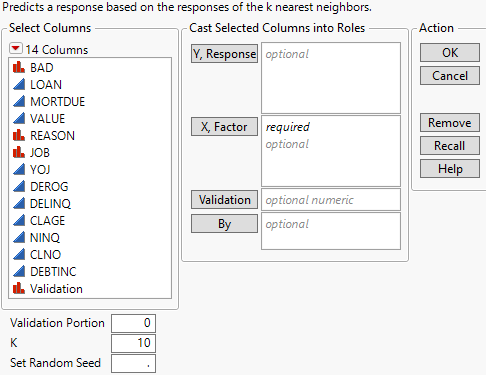
Figure 7.4 K Nearest Neighbors Launch Window
For more information about the options in the Select Columns red triangle menu, see Column Filter Menu in Using JMP.
The K Nearest Neighbors launch window provides the following options:
Y, Response
The response variable or variables that you want to analyze.
Note: The K Nearest Neighbors platform can be used as a utility to determine the distances between neighboring observations, even without the presence of a response variable. If you do not specify a response variable, a blank report appears. However, the red triangle menu options Save Near Neighbor Rows and Save Near Neighbor Distances are available.
X, Factor
The predictor variables.
Validation
A numeric column that contains at most three distinct values. See Validation in the Partition Models section.
By
A column or columns whose levels define separate analyses. For each level of the specified column, the corresponding rows are analyzed using the other variables that you have specified. The results are presented in separate reports. If more than one By variable is assigned, a separate report is produced for each possible combination of the levels of the By variables.
Validation Portion
The portion of the data to be used as the validation set. See Validation in the Partition Models section.
Number of Neighbors, K
Maximum number of nearest neighbors to analyze. Models are fit for one nearest neighbor up to the value that you specify for K.
Note: The maximum number of neighbors, K, must be no larger than one less than the number of rows in the training data table. If you specify a K that is larger than the maximum allowable K, a warning appears.
Set Random Seed
Sets the seed for the randomization process used in tie-breaking for nominal and ordinal responses. If you specify a Validation Portion, this option also sets the seed for the rows used for validation. Set Random Seed is useful if you want to reproduce an analysis. If you set a random seed and save the script, the seed is automatically saved in the script.