Build the SQL Query
After selecting database tables, you either import the data or build a query. Query Builder enables you to interactively create the database query rather than write SQL expressions.
After selecting database tables (and joining them if necessary), click Build Query to open the Query Builder window. You can continue to refine the query by selecting which columns to include and specifying criteria for sampling and filtering. You can also save the query to edit and run again later.
The columns from all database tables appear in the Available Columns list. Prefixes such as t1 and t2 (also called aliases) associate each column with the corresponding database table.
To skip the Query Builder step and import all data, click Import Now instead.
Note: The JMP Query Builder in the Tables menu provides many of the same options but lets you query and join JMP data tables. See Query and Join Data Tables with JMP Query Builder in the Reshape Data section.
Select Columns from the Database Table
Suppose that you want to view movie rentals by movie genre, rating, and demographic data such as marital status and age.
Note: The Query Builder examples are based on a database that is not installed with JMP.
1. Select File > New > Database Query, connect to the database, and select the SQBTest schema. See Connect to a Database.
2. In the Select Tables for Query window, select g6_Customers and click Primary.
3. Select g6_Movies and g6_Rentals and click Secondary.
4. Click Build Query to show the Query Builder window.
5. In the Available Columns box, select t1.Gender, t1.Age, t1.Married, t1.KidsUnder12, t2.Rating, and t2.Genre.
6. Click Add on the Included Columns tab.
Figure 3.38 Selected Columns
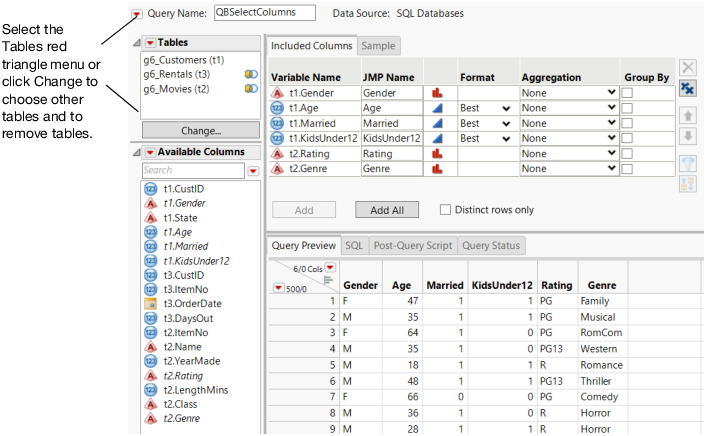
Notes:
– When a query contains eight tables or more, a search box appears above the table names near the upper left corner. To find a column in a long list, enter the name in the search box below Available Columns. The red triangle menu provides options for matching case and searching with regular expressions. To hide the search box, deselect Show Search Box from the Available Columns red triangle menu.
– Reference columns no longer appear in the Available Columns list because they are not supported in queries.
– You can change the width of the column by selecting an option from the Format list in the Included Columns list.
7. Select the SQL tab below the columns to view the SQL statements for your query. This code is saved as a data table property after you run the query.
8. Click Save in the lower right corner.
Your work is saved as g6_Customers.jmpquery, which you can open later to return to this point or to run the query.
9. Click Run Query to import the data.
The data table includes the following scripts:
– Run the Source script to reconnect to the database and import the data.
– Run the Modify Query script to open the query in Query Builder.
– Run the Update From Database script to re-import and refresh the data.
Tips:
• To rename a column, double-click the JMP Name in the Included Columns tab and enter a new name.
• To rename an alias, right-click the table in the Select Tables for Query window and select Change Alias. Aliases are not case sensitive.
• The query runs in the background unless you deselect Run queries in the background when possible from the Query Builder ODBC preferences. You can also check the progress of all ODBC queries by selecting View > Running Queries.
Note: For SAS Query Builder, all queries run in the foreground.
• Deselect Update preview automatically if the preview loads too slowly. Click Update below the Query Preview tab to update the data view. Consider changing the Preview options in the JMP Query Builder preferences if you frequently work with large databases. Consider limiting the maximum number of rows that can be previewed. In the JMP Query Builder preferences, change the value of Maximum number of rows for previews.
• To omit duplicate rows from the database, select Distinct rows only on the Included Columns tab.
Maintain Compatibility with JMP 12
If you add a JMP 13 feature to a query, that query will no longer load in JMP 12. If you are using JMP 13, but you need to create queries that will still run in JMP 12, select Keep this query compatible with JMP 12 in the Query Builder Preferences. After you select the option, features that create compatibility problems are hidden in Query Builder.
When you are ready to move JMP 12 queries to JMP 13 or 14, deselect this preference.
Create a Computed Column
You can create a new column from existing columns. You might calculate the mean for two columns and store the mean in a new column. Date-time values might be in the wrong format. Click the Available Columns red triangle, select Add Computed Column, and create the new column in the formula editor.
Suppose that you want to calculate the maximum number of times you can watch a movie during the rental period. You are querying a database that contains the length of each movie and number of days the movie was checked out. This example shows how to create a new computed column from these data.
Note: The Query Builder examples are based on a database that is not installed with JMP.
1. Select File > New > Database Query, connect to the database, and select the SQBTest schema. See Connect to a Database.
2. In the Select Tables for Query window, select g6_Rentals as the Primary table and g6_Movies as the Secondary table.
3. Click Build Query to show the Query Builder window.
4. Click the Available Columns red triangle and select Add Computed Column.
The Computed Column window appears. The window contains the JMP Formula Editor.
Figure 3.39 Computed Column Window with Formula Editor
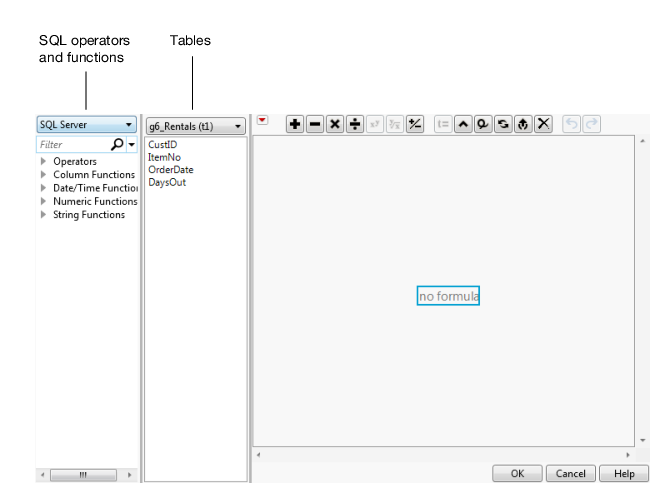
Notes:
– Operators and functions are provided in the list on the left side of the Formula Editor (Figure 3.39). In some instances, you might need to change the server type based on your database.
– The Operators list does not provide a Concatenate (||) operator. You must type the formula in the Formula Editor box.
5. From the g6_Rentals list on the left, select Days Out and click the multiplication  button.
button.
Figure 3.40 Computed Column

6. Select the blank box, type (24 * 60, and press Enter.
This formula multiplies the number of minutes in an hour by the number of minutes in day. Notice that when you type the first parenthesis, then second one is automatically inserted.
Figure 3.41 First Portion of the Formula
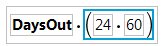
7. Click the outer box to select the entire equation and click the division  button.
button.
8. Select g6_Movies from the list on the left and then select LengthMins.
Figure 3.42 Second Portion of the Formula
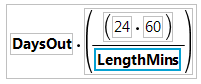
9. Click OK.
A new column named Calc1 is created.
10. Right-click the column and select Rename Column.
11. Type MaximumTimesWatched and click OK.
12. In the Available Columns list, select MaximumTimesWatched and click Add.
13. Select t2.Name and click Add.
On the Query Preview tab, notice that Nanny McPhee can be watched 160 times while the movie is rented.
Group the Common Values
You can combine (or group) common values in a column before importing the data into JMP. To group common values, select an Aggregation function to determine how the common values are calculated.
Note: Aggregation support is based on your database. See the database documentation.
Suppose that you are interested in the number of times a specific movie was rented. In this example, the count for each item number is calculated, and common movie values are grouped into single rows.
Note: The Query Builder examples are based on a database that is not installed with JMP.
1. Select File > New > Database Query, connect to the database, and select the SQBTest schema. See Connect to a Database for.
2. In the Select Tables for Query window, select g6_Movies as the Primary table and g6_Rentals as the Secondary table.
3. Click Build Query to show the Query Builder window.
4. In the Available Columns box, select t1.Name and t2.ItemNo and click Add.
5. Select t2.ItemNo and select Count from the Aggregation list.
The Group By check box is selected for t1.Name. All instances of a specific movie name will be grouped into one row.
Figure 3.43 Grouped Columns
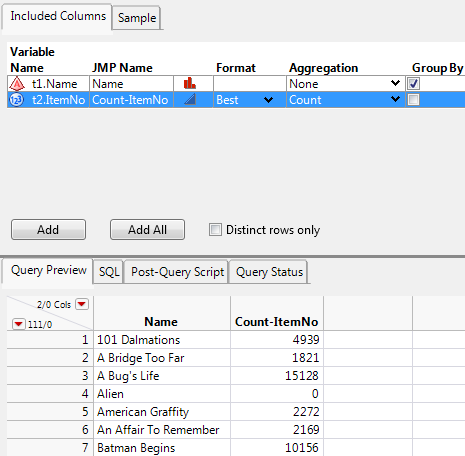
6. Click Run Query to import the data.
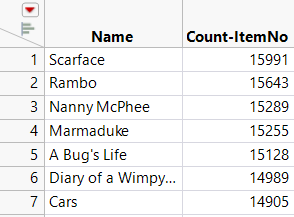
7. In the data table, right-click the Count-ItemNo column and select Sort > Descending.
Scarface was rented most frequently.
Figure 3.44 Partial View of the Sorted Count-ItemNo Column
Tips:
• To clear the grouped rows, select None from the column’s Aggregation list.
• The DISTINCT Aggregation functions show only rows that contain distinct values. Rows with duplicate values are omitted. These functions are useful when a database contains many duplicate values.
Import a Sample of the Data
With large databases, consider sampling the data. Sampling returns a subset of rows and decreases the query time. The database query runs, and a smaller portion of data are imported based on options that you select on the Sample tab.
Sampling methods differ based on the database vendor.
• SQL Server supports block sampling by default. A block sample takes an entire page of rows (such as all rows on pages 1 and 5). If you select 1,000 rows, approximately 1,000 rows are imported.
• Oracle and other databases support row sampling. If you select 5,000 rows, between 4,800 and 5,200 rows per sample are typically imported, based on how Oracle cycles through the data.
For major database vendors, JMP detects the capabilities and provides vendor-specific options when possible. Features that are unsupported by the vendor are unavailable on the Sample tab.
Suppose that you want to import a sample of the data. In this example, you select 5,000 random rows.
Note: The Query Builder examples are based on a database that is not installed with JMP.
1. Select File > New > Database Query, connect to the database, and select the SQBTest schema. See Connect to a Database for.
2. In the Select Tables for Query window, select g6_Rentals as the Primary table and g6_Movies as the Secondary table.
3. Click Build Query to show the Query Builder window.
4. Click the Add All button on the Included Columns tab.
5. Click the Sample tab and select Sample this result set.
6. Select Random N Rows and type 5,000.
In the Sample By area, Blocks or Pages is the only option based on which type of sampling the database supports.
7. Click Run Query to import the data.
The new data table consists of approximately 5,000 rows. With block or page sampling, you might get a sample of 4,900 rows one time and 5,600 rows the next time.
Tips:
• To re-create the same sample set each time you run a query, set the Seed value to any positive integer up to 64,000. Suppose that you want to query movie rentals by gender. Type 1 as the Seed value and run the query. The distribution of male customers in the results is low. Type 2 as the Seed value and run the query again. Repeat this process to find the Seed value that results in a similar distribution of males and females.
• To add individual columns to the Included Columns tab, right-click the column and select Include Column or click the Add button.
Select Filters to Import a Subset of the Data
Add filters to import a subset of values from the selected filters into the data table. Some filters are not available if the query is compatible with JMP 12. See Maintain Compatibility with JMP 12.
Filters for Both Continuous and Categorical Columns
Simple Comparison
Matches values using the specified operator.
Age > 14 matches ages that are greater than 14.
Range
Matches a range of values using the specified operator.
12 ≤ Age ≤ 17 matches ages that are between 12 and 17.
Is NULL or Is Not NULL
Matches missing values.
Either NULL or not NULL matches missing values and non-missing values.
Custom Expression
Enables you to write your own SQL expression.
( ( ( t2.Gender IN ( 'F' ) ) AND ( (t2.Age >= 20) AND (t2.Age <= 50) ) ) )
matches the F Gender. It also matches Age between 20 and 50.
Filters that are Only for Categorical Columns
List Box
Displays a list box from which you select one or more values. List Box is the default filter for categorical columns based on the Query Builder preferences.
Manual List
Enables you to enter the column values.
Check Box List
Displays a check box list.
Note: List Box, Manual List, and Check Box List include a Not in list option that enables you to retrieve rows that do not match the selected values.
Contains
Matches a string that contains or does not contain the specified value. Contains Comedy OR Romance matches Comedy and Romance.
For most categorical columns, the filter is a List Box by default. For columns that contain over 1,000 levels, the Contains filter is automatically selected. You can change the number of levels in the Query Builder preferences.
Like or Not Like
Matches a string that is similar to or not similar to the specified value. Supports the % wildcard (zero or more characters) and _ wildcard (exactly one character).
Genre Like %com matches any number of characters before “com”, as in “RomCom”. To also match “Comedy”, use %com% or Contains com.
Match Column Values
Matches the specified column value. Select the table and then select the columns. The Select non-matching option enables you to filter all rows except for the selected rows. See Import Matching Data from an Existing Data Table for an example.
This example shows how to import data for age 30 and over customers, and movies in the RomCom and Comedy genres.
Note: The Query Builder examples are based on a database that is not installed with JMP.
1. Select File > New > Database Query, connect to the database, and select the SQBTest schema. See Connect to a Database.
2. In the Select Tables for Query window, select g6_Rentals from the Available Tables list, and then click Primary.
3. Select g6_Customers and g6_Movies and then click Secondary.
4. Click Build Query to show the Query Builder window.
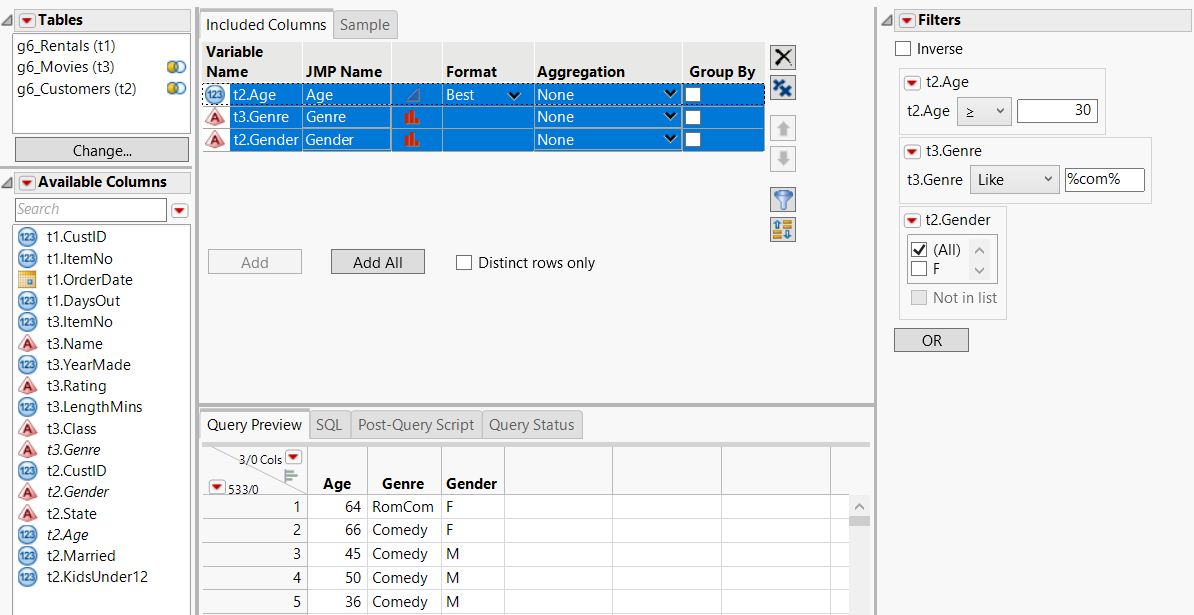
5. In the Available Columns box, select t2.Gender, t2.Age, and t3.Genre, and then click Add on the Included Columns tab.
6. Select all columns on the Included Columns tab and click Add Selected Items to Filters  .
.
Filters for the columns appear in the Filters outline.
7. Set the t2.Age filter to ≥ 30.
8. Click the t3.Genre red triangle and select Like, type %com%, and press Enter.
The % wildcards match any number of characters before and after “com”. On the Query Preview tab, notice that movies in both the RomCom and Comedy genres are shown.
Figure 3.45 Selecting Filters
9. Click the Filters red triangle and select All Prompt on Run.
Users who run the query can customize the filters.
10. Click Run Query.
11. In the Query Prompts window, click OK to apply the preselected filters and import the data.
Notes:
• For most categorical columns, the filter is a list box by default. For columns that contain over 1,000 levels, the Contains filter is automatically selected. You can change the number of levels in the Query Builder preferences.
• The Conditional option in a filter’s red triangle menu enables you to filter data within hierarchical categories. For example, suppose that you have a State filter and a City filter. To select a state and then display only cities that are in that state, click the City red triangle and select Conditional.
• The Inverse option at the top of the Filters list enables you to select all but the specified rows for all filters. The option is unavailable for filters that select all rows.
• “<Blank>” in the filter list indicates that the database contains a missing value for that column.
• To create a filter for large columns of categorical data, JMP attempts to determine the number of rows in the table.
– The Query Builder preference called Retrieve category levels for tables whose size cannot be determined is selected by default so that JMP automatically retrieves the levels. If you deselect the preference, the Contains fallback filter type in the Query Builder preferences is selected.
– If the categorical column has more than 1 million rows, JMP does not automatically retrieve the unique category levels for the filtered column. The Query Builder preference called Maximum rows in table for which category levels will be automatically retrieved supports a minimum of -1 (no limit) and a maximum value of 1 billion rows.
• The default filter for categorical columns is a list box unless the Keep this query compatible with JMP 12 Query Builder preference is selected.
Import Matching Data from an Existing Data Table
You can also select rows from an open data table that match a column in your query. Consider a database of airline data. The database includes data such as flight duration and tail number. You also have a data table that includes tail number data. Use the Match Column Values filter to import only data for matching tail numbers.
Note: The Query Builder examples are based on a database that is not installed with JMP.
1. Select Help > Sample Data Library and open Air Traffic.jmp.
2. Select File > New > Database Query, connect to the database, and select the SQBTest schema. See Connect to a Database.
3. In the Select Tables for Query window, select g5_AIRLINE_ONTIMEPERF from the Available Tables list, and then click Primary.
4. Click Build Query to show the Query Builder window.
5. Click Add All on the Included Columns tab.
6. Select t1.TailNum on the Included Columns tab and click Add Selected Items to Filters .
7. Click the t1.TailNum red triangle in the Filters column, select Filter Type, and then select Match Column Values.
8. Select Air Traffic below Match values from table.
9. Select the Tail Number column and then select All rows (38,118) from the list.
The data view on the Query Preview tab updates to show the filtered values.
10. Click Run Query to import the data.
The data table includes only data for rows that are in the Tail Number column.
Write a Custom Expression to Import a Subset of the Data
In addition to selecting filters to subset the data, you can write custom SQL expressions if you do not want to use the filters that are provided.
Note: The Query Builder examples are based on a database that is not installed with JMP.
1. Select the columns that you want to filter (described in Select Filters to Import a Subset of the Data).
2. Click the Filters red triangle and select Add Custom Expression.
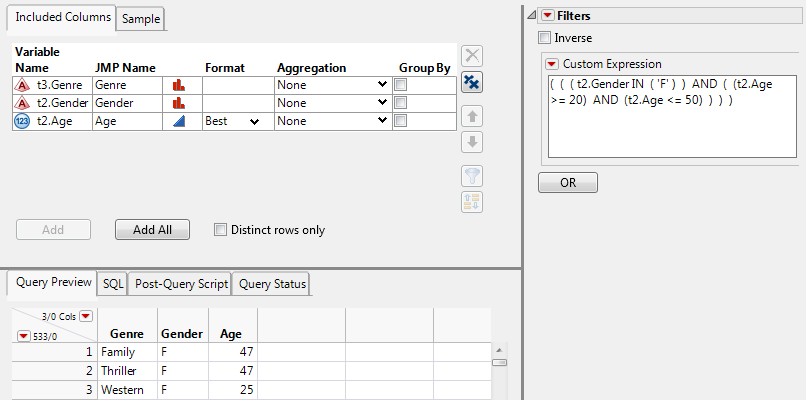
3. Type the following text in the Custom Expression box:
( ( ( t2.Gender IN ( 'F' ) ) AND ( (t2.Age >= 20) AND (t2.Age <= 50) ) ) )
4. Click outside the Custom Expression box to update the Query Preview tab.
This expression matches the F Gender. It also matches Age between 20 and 50.
Figure 3.46 Writing a Custom Filter Expression
Sort the Selected Data
You can sort the rows in specific columns by values to control how the data appear in the data table. In this example, you sort the Married column in descending order and sort the data by age and then height.
Note: The Query Builder examples are based on a database that is not installed with JMP.
1. Select File > New > Database Query, connect to the database, and select the SQBTest schema. See Connect to a Database for.
2. In the Select Tables for Query window, select g4_bigclass as the Primary table.
3. Click Build Query to show the Query Builder window.
4. On the Included Columns tab, click Add All.
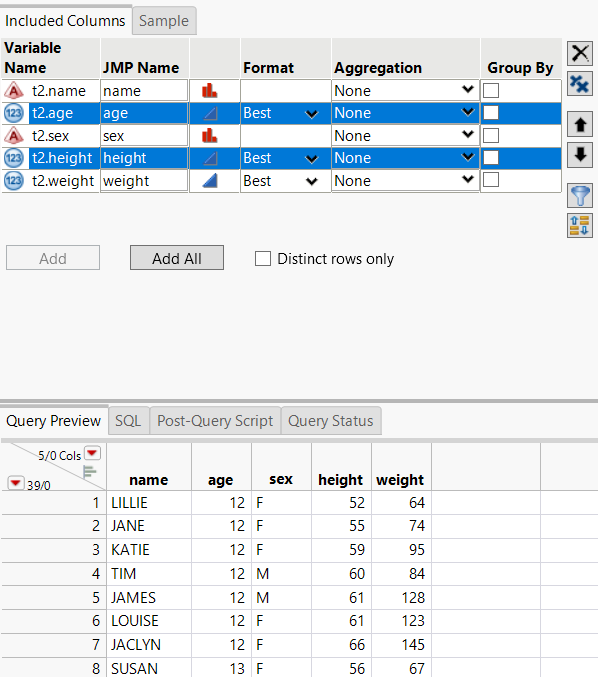
5. Select t1.age and t1.height and click Order by the Selected Items  .
.
The columns appear in the Order By outline in the right column.
The columns are sorted by age first (youngest to oldest) and then height (shortest to tallest).
Figure 3.47 Selecting the Order By Columns
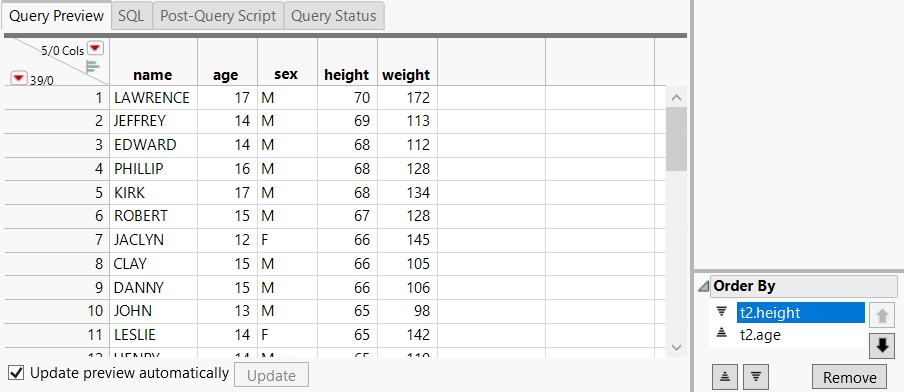
6. In the Order By outline, select t2 .height and then click Sort the values in descending order  below the columns.
below the columns.
The height column is sorted from tallest to shortest.
7. Select t2.height and click Move the Selected Items Up in the List  .
.
The height column is sorted first. Values in the age column are sorted within each level of height. For a height of 68, age is sorted from 14 to 17.
Figure 3.48 Result of Reordering Columns
View the Query Status
On the Query Status tab, view the status of a query as it runs in the background. The query name, SQL statements, and number of processed records appear. You can stop a query at any time and view only the processed records. To view background queries from other JMP windows, select View > Running Queries. The status details are unavailable if you deselect Run queries in the background when possible from the Query Builder preferences.
Note: For SAS connections in Query Builder, all queries and query previews run in the foreground.
Write a Post-Query Script
On the Post-Query Script tab, write a JSL script that runs after you run the query. For example, you might want to import the data and then create a distribution.
Distribution( Column( :age, :gender ) );
This script is part of the Source script in the final data table.