Factors
Add factors in the Factors outline.
Tip: When you have completed the Factors outline, consider selecting Save Factors from the red triangle menu. This saves the factor names, roles, changes, and values in a data table that you can later reload.
Figure 4.18 Factors Outline
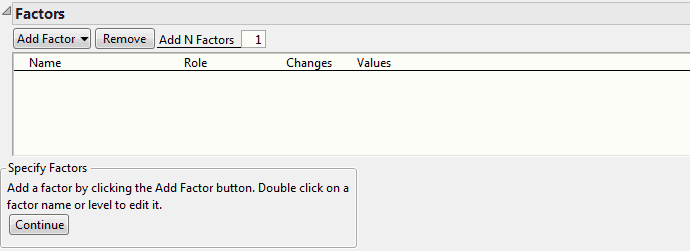
Add Factor
Select the factor type. See Factor Types.
Remove
Removes the selected factors.
Note: If you attempt to remove all factors after clicking the Continue or Back button, one continuous factor remains. You can delete it after you add new factors.
Add N Factors
Adds multiple factors. Enter the number of factors to add, click Add Factor, and then select the factor type. Repeat Add N Factors to add multiple factors of different types.
Factors Outline
The Factors outline contains the following columns:
Name
The name of the factor. When added, a factor is given a default name of X1, X2, and so on. To change this name, double-click it and enter the desired name.
Role
Specifies the Design Role of the factor. The Design Role column property for the factor is saved to the data table. This property ensures that the factor type is modeled appropriately.
Changes
Indicates whether the factor levels are Easy, Hard, or Very Hard to change. Click the default value of Easy to change it. When you specify factors as Hard or Very Hard to change, your design reflects these restrictions on randomization. A factor cannot be designated as Very Hard unless the Factors list contains a factor designated as Hard. The Factor Changes column property is saved to the data table. See Changes and Random Blocks.
Values
The experimental settings for the factors. To insert Values, click the default values and enter the desired values.
Editing the Factors Outline
In the Factors outline, note the following:
• To edit a factor name, double-click the factor name.
• Categorical factors have a down arrow to the left of the factor name. Click the arrow to add a level.
• To remove a factor level, click the value, click Delete, and click outside the text box.
• To modify the entry under Changes, click the value in the Changes column and select the appropriate entry.
• To edit a value, click the value in the Values column.
Factor Types
To choose a factor type, click Add Factor in Custom Design.
Note: A Design Role column property containing each factor’s role is added to that factor’s column in the design table that is generated. The Design Role column property ensures that the factor is modeled correctly.
Continuous
Numeric data types only. A continuous factor is a factor that you can conceptually set to any value between the lower and upper limits you supply, given the limitations of your process and measurement system.
Discrete Numeric
Numeric data types only. A discrete numeric factor can assume only a discrete number of values. These values have an implied order.
The default values for a discrete numeric factor with k levels, where k > 2, are the integers 1, 2, ..., k. The default values for a discrete numeric factor with k = 2 levels are -1 and 1. Replace the default values with the settings that you plan to use in your experiment.
Note: Not all levels of a discrete numeric factor appear in the design. The levels that appear are determined by your specifications in the Model outline. If you need all levels to appear in your design, consider using the Screening Design platform.
In the assumed model, the effects for a discrete numeric factor with k levels include polynomial terms in that effect through order k-1. For k greater than 6, powers up to the 5th level are included. The Estimability for polynomial effects (powers of two or higher) is set to If Possible. This allows the algorithm to use the multiple levels as permitted by the run size. If the polynomial terms are not included, then a main effects only design is created. For more information about how discrete numeric factors are treated in the assumed model, see Model.
Fit Model treats a discrete numeric factor as a continuous predictor. The Model script that is saved to the design table does not contain any polynomial terms of order greater than two.
Categorical
Either numeric or character data types. The data type in the resulting data table is categorical. The value order of the levels is the order of the values, as entered from left to right. This ordering is saved in the Value Order column property after the design data table is created.
Blocking
Either numeric or character data types. A blocking factor is a special type of categorical factor that can enter the model only as a main effect. When you define a blocking factor, you specify the number of runs per block. The RunsPerBlock column property is saved to the design table. The Default run size always assumes that there are at least two blocks. If you specify a run size that is not an integer multiple of the number of runs per block, JMP tries to balance the design to the extent possible. In balancing the design, JMP ensures that there are at least two runs per block.
Covariate
Either numeric or character data types. The values of a covariate factor are measurements on experimental units that are known in advance of an experiment. Covariate values are selected to ensure the optimality of the resulting design relative to the optimality criterion. See Changes and Random Blocks and Covariates with Hard-to-Change Levels.
JMP obtains the covariate factors and their values from a data table that contains the measured covariates for the available experimental units. Make this data table your current data table. When you select Covariate, a list of columns in the current data table opens, and you select the columns containing covariates from this list. Your design must have no more runs than the number of rows in the covariate table. If the design has fewer runs than the number of covariate rows then the design table includes a Covariate Row Index column. This column indicates the row from the covariate table that corresponds to each experimental run.
In some situations, you might want to select a small set of design points from a larger set of candidate settings. For example, you might have multiple measurement columns (factors) for a large batch of units. You want to treat the measurements for each unit as a candidate run. From these candidate runs, you want to select a small but optimal collection for which you measure a response. In this case, make the data table of all candidate runs the active table, select Add Factor > Covariate, and enter all of your measurement columns as covariates. Specify your desired run size. The Custom Design platform identifies an optimal collection of design settings.
Note: You cannot specify a Number of Runs or Number of Whole Plots that exceeds the number of rows in the covariate’s data table.
Mixture
Continuous factors that represent ingredients in a mixture. The values for a mixture factor must sum to a constant. By default, the values for all mixture factors sum to one. To set the sum of the mixture components to some other positive value, select Advanced Options > Mixture Sum from the red triangle menu. The Mixture column property is saved to the data table.
Constant
Either numeric or character data types. A constant factor is a factor whose values are fixed during an experiment. Constant factors are not included in the Model outline or in the Model script that is saved to the data table.
Uncontrolled
Either numeric or character data types. An uncontrolled factor is one whose values cannot be controlled during production, but it is a factor that you want to include in the model. It is assumed that you can record the factor's value for each experimental run.
An empty column with a Continuous Modeling Type is created in the design table. You can change the column’s Data Type and Modeling Type in the Column Info window if required. Enter your data in this column. Uncontrolled factors are included in the Model outline and the Model script that is saved to the data table.
Changes and Random Blocks
Specifying the relative difficulty of changing a factor from run to run is useful in industrial experimentation. It is often convenient to make several runs while keeping factors that are hard-to-change fixed at some setting. A Changes value of Hard results in a split-plot design. A Changes value of Very Hard results in a split-split-plot design or a two-way split-plot design.
You can set Changes for Continuous, Discrete Numeric, Categorical, and Mixture factors to Hard and Very Hard. To set a factor to Very Hard, the list must contain another factor that is set to Hard.
You can set Changes for a Covariate factor to Hard. In this case, all other covariates are also set to Hard and the remaining factors are set to Easy. The algorithm requires a combination of row exchange and coordinate exchange. For this reason, even moderately sized designs might take some time to generate.
For designs with Hard or Very Hard to change factors, Custom Design strives to find a design that is optimal, given your specified optimality criterion. See Optimality Criteria. For more information about the methodology used to generate split-plot designs, see Jones and Goos (2007). For more information about designs with hard-to-change covariates, see Jones and Goos (2015).
Figure 4.19 shows a split-split-plot scenario, using the factors from the Cheese Factors.jmp sample data table (located in the Design Experiment folder).
Figure 4.19 Factors and Design Generation Outline for a Split-Split-Plot Design
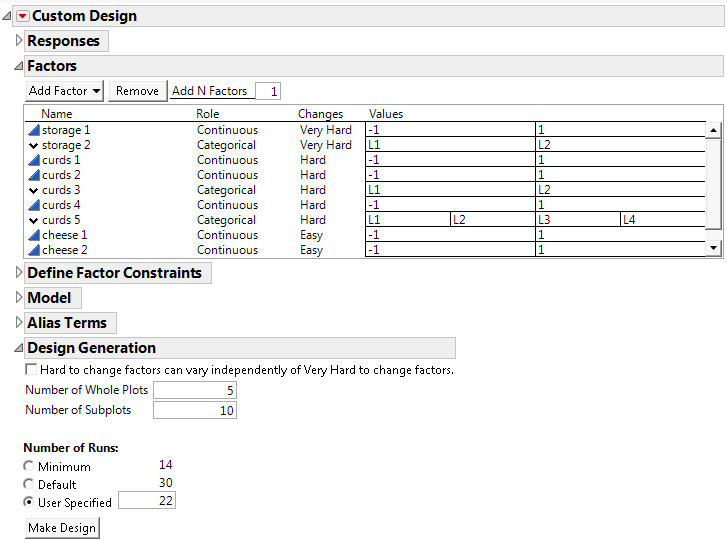
If you assign Changes as Hard for one or more factors, but no factors are assigned Changes that are Very Hard, a categorical factor called Whole Plots is added to the design. This situation results in a split-plot design:
• Each level of Whole Plots corresponds to a block of constant settings of the hard-to-change factors.
• The Model script in the design table applies the Random Effect attribute to the factor Whole Plots.
• The factor Whole Plots is assigned the Design Role column property with a value of Random Block.
When you designate Changes as both Hard and Very Hard, categorical factors called Subplots and Whole Plots are added to the design. This situation results in a split-split-plot design:
• Each level of Subplots corresponds to a block of constant settings of the hard-to-change factors.
• Each level of Whole Plots corresponds to a block of constant settings of the very-hard-to-change factors.
• The Model script in the design table applies the Random Effect attribute to the Whole Plots and Subplots effects.
• The levels of the hard-to-change factor are assumed to be nested within the levels of the very-hard-to-change factor by default.
• In the design table, both of the factors Whole Plots and Subplots are assigned the Design Role column property with a value of Random Block.
To construct a two-way split-plot design, select the Hard to change factors can vary independently of Very Hard to change factors option under Design Generation. The option crosses the levels of the hard-to-change factor with the levels of the very-hard-to-change factor. See Two-Way Split-Plot Designs.
Use the Number of Whole Plots and Number of Subplots text boxes to specify values for the numbers of whole plots or subplots. These boxes are initialized to suggested numbers of whole plots and subplots. For information about how these values are obtained, see Numbers of Whole Plots and Subplots.
For more information and scenarios that illustrate random block split-plot, split-split-plot, and two-way split-plot designs, see Designs with Randomization Restrictions. For more information about designs with hard-to-change covariates, see Covariates with Hard-to-Change Levels.
Factor Column Properties
For each factor, various column properties are saved to the data table. You can find more information about these column properties and related examples in Column Properties.
Design Role
Each factor is given the Design Role column property. The Role that you specify in defining the factor determines the value of its Design Role column property. When you add a random block under Design Generation, that factor is assigned the Random Block value. The Design Role property reflects how the factor is intended to be used in modeling the experimental data. Design Role values are used in the Augment Design platform. See Design Role in the Column Properties section.
Factor Changes
Each factor is assigned the Factor Changes column property. The value that you specify under Changes determines the value of its Factor Changes column property. The Factor Changes property reflects how the factor is used in modeling the experimental data. Factor Changes values are used in the Augment Design and Evaluate Design platforms. See Factor Changes in the Column Properties section.
Coding
If the Role is Continuous, Discrete Numeric, a continuous Covariate, or Uncontrolled, the Coding column property for the factor is saved. This property transforms the factor values so that the low and high values correspond to –1 and +1, respectively. See Coding in the Column Properties section.
Value Order
If the Role is Categorical or Blocking, the Value Order column property for the factor is saved. This property determines the order in which levels of the factor appear. See Value Order in the Column Properties section.
Mixture
If the Role is Mixture, the Mixture column property for the factor is saved. This property indicates the limits for the factor and the mixture sum. It also enables you to choose the coding for the mixture factors. See Mixture in the Column Properties section.
RunsPerBlock
For a blocking factor, indicates the maximum allowable number of runs in each block. When a Blocking factor is specified in the Factors outline, the RunsPerBlock column property is saved for that factor. See RunsPerBlock in the Column Properties section.