Hierarchical Cluster
Group Observations Using a Tree of Clusters
Clustering is a multivariate technique that groups together observations that share similar values across a number of variables. Use it to understand the clumping structure of your data.
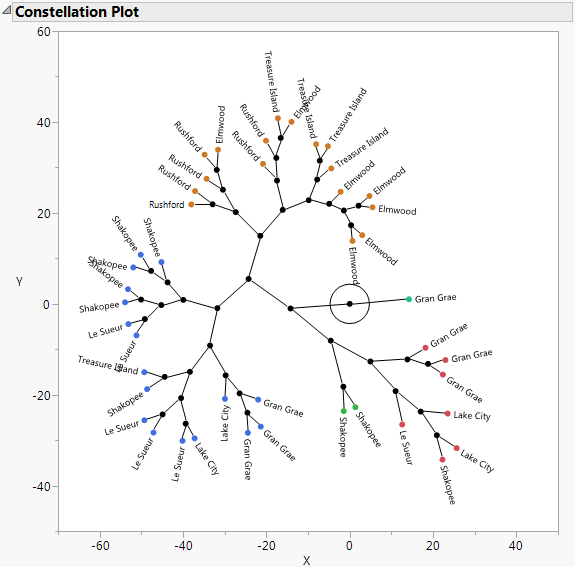
Hierarchical clustering combines clusters successively. The method begins by treating each observation as its own cluster. Then, at each step, the two clusters that are closest in terms of distance are combined into a single cluster. The result is depicted as a tree, called a dendrogram.
Use hierarchical clustering for small data tables with no more than several tens of thousands of rows. The algorithm is time-intensive and can run slowly for larger data tables. For larger data tables, use K Means Cluster or Normal Mixtures.
Note: Hierarchical cluster supports character columns; K Means Cluster or Normal Mixtures require numeric columns.
Figure 12.1 Example of a Constellation Plot