Quelles céréales rentrent dans le cadre d'une alimentation saine ? L'échantillon de données Cereal.jmp (données réelles obtenues sur les boîtes de céréales populaires) fournit des statistiques sur la teneur en fibres, le nombre de calories, et d'autres informations nutritionnelles. Pour identifier les céréales les plus saines, vous devez suivre différentes étapes consistant à interpréter les histogrammes et les statistiques descriptives, à détecter les corrélations et les valeurs aberrantes, et à réaliser des nuages de points et une classification.
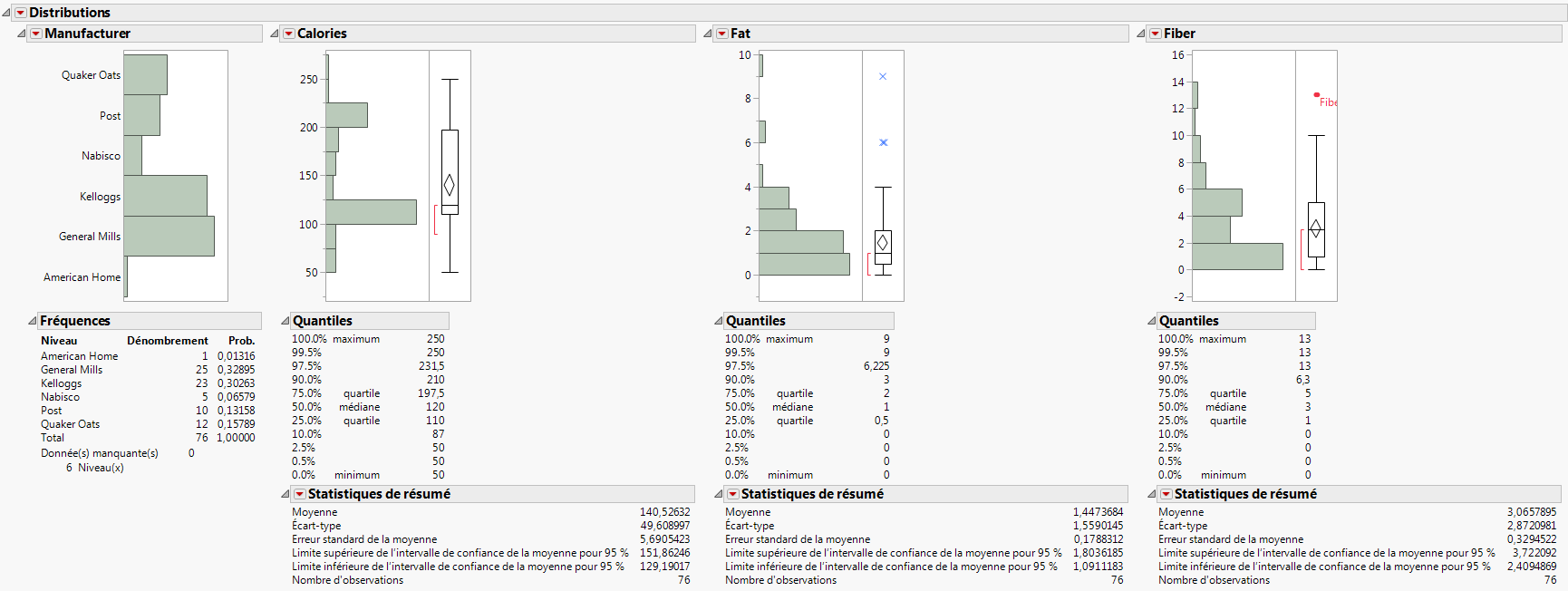
La plate-forme Distribution illustre la distribution d'une seule variable (analyse univariée) à l'aide d'histogrammes, de graphiques supplémentaires et de rapports. Le mot univarié signifie simplement qu'il y a une seule variable, et non deux (bivarié) ou plus encore (multivarié). Vous pouvez cependant examiner la distribution de plusieurs variables individuelles dans un même rapport. Selon que la variable est catégorielle (nominale ou ordinale) ou continue, le contenu du rapport peut varier.
Remarque : Pour plus d'informations sur la plate-forme Distribution, voir le chapitre Distributions dans Basic Analysis.
|
1.
|
|
2.
|
Choisissez Analyse > Distribution.
|
|
3.
|
|
4.
|
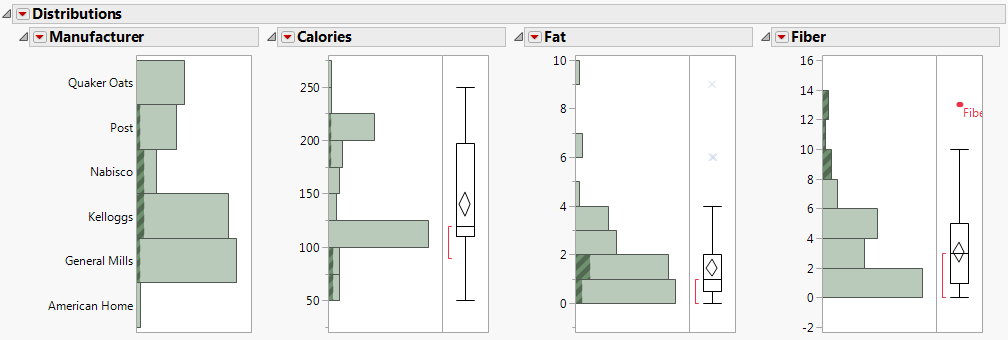
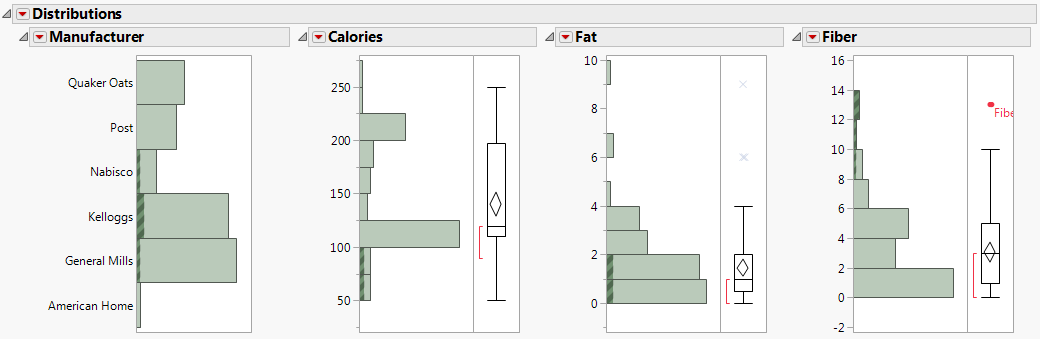
Dans le fichier Cereal.jmp, la ligne contenant Fiber One est étiquetée. Dans les graphiques, cette étiquette permet d'afficher le nom des céréales à côté d'un point de données. Pour voir l'étiquette entière, faites glisser la bordure verticale la plus à droite vers la droite. Placez votre curseur sur le point de données non étiqueté pour voir « All Bran with Extra Fiber ».
Figure 6.3 Distributions pour les céréales Nabisco
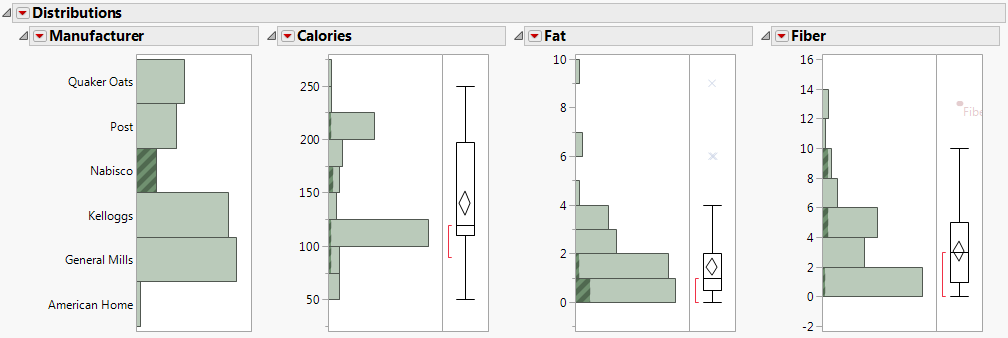
Figure 6.4 Céréales riches en fibres
Conseil : Laissez le rapport Distributions ouvert. Il vous sera utile lorsque vous réaliserez la classification. Voir Analyser les valeurs similaires.
Remarque : Pour plus d'informations sur la plate-forme Multivariée, voir le chapitre Correlations and Multivariate Techniques dans Multivariate Methods.
|
1.
|
Dans la table de données Cereal.jmp, cliquez sur le triangle du bas situé en haut du panneau Colonnes pour désélectionner les lignes.
|
Figure 6.6 Désélectionner des lignes
|
2.
|
Sélectionnez Analyse > Méthodes multivariées > Multivarié.
|
|
3.
|
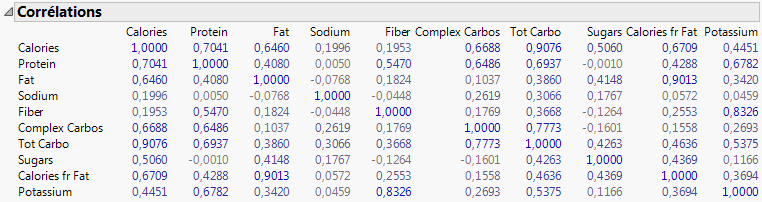
Figure 6.7 Rapport Corrélations
|
–
|
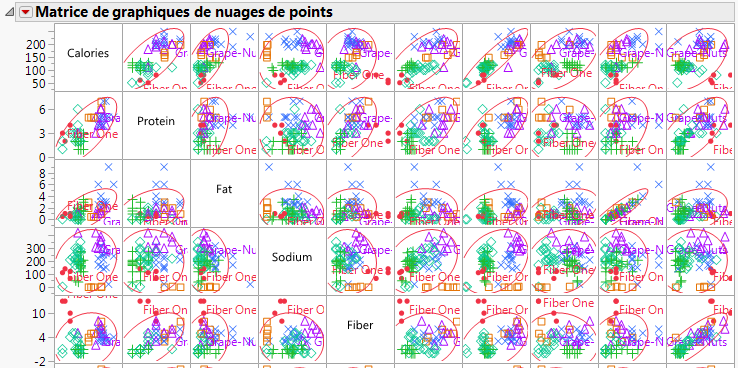
Figure 6.8 Portion de la Matrice de nuages de points
|
4.
|
Figure 6.9 Portion du rapport Corrélations par paire
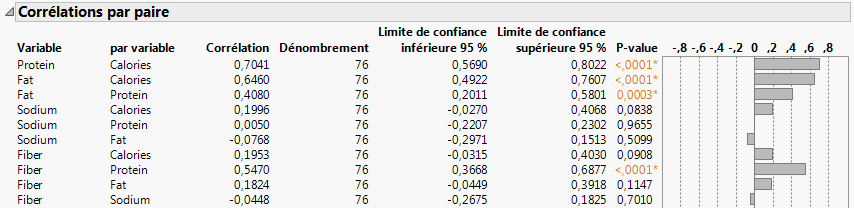
|
5.
|
Pour identifier rapidement les paires fortement corrélées, cliquez avec le bouton droit sur le rapport et sélectionnez la case à cocher Trier par colonne, P-value, Ordre croissant, puis cliquez sur OK.
|
Les paires les plus fortement corrélées apparaissent en haut du rapport. Pour les paires, les petites p-values sont une preuve de corrélation. La corrélation la plus significative est entre Tot Carbo (glucides totaux) et Calories.
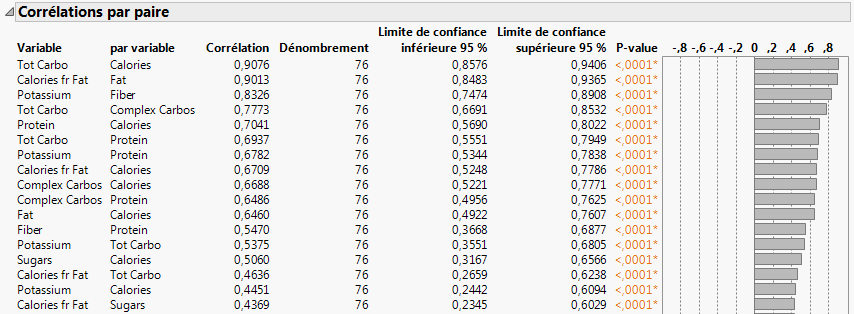
La classification est une technique multivariée qui regroupe les observations qui partagent des valeurs similaires parmi un certain nombre de variables. La classification hiérarchique combine les lignes en une séquence hiérarchique représentée sous la forme d'une arborescence. Les céréales présentant certaines caractéristiques, telles qu'une forte teneur en fibres, sont regroupées dans des clusters de sorte que vous puissiez en identifier les similitudes.
Remarque : Pour plus d'informations sur la classification hiérarchique, voir le chapitre Hierarchical Cluster dans Multivariate Methods.
|
1.
|
|
2.
|
Figure 6.11 Portion du rapport Classification hiérarchique
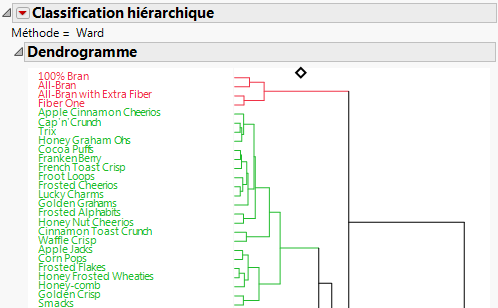
|
3.
|
Cliquez sur le triangle rouge Classification hiérarchique et sélectionnez Colorier les clusters.
|
Figure 6.12 Clusters colorés
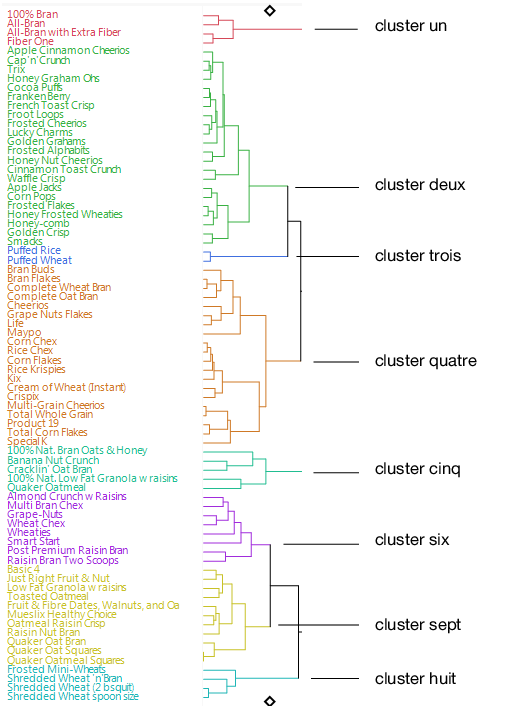
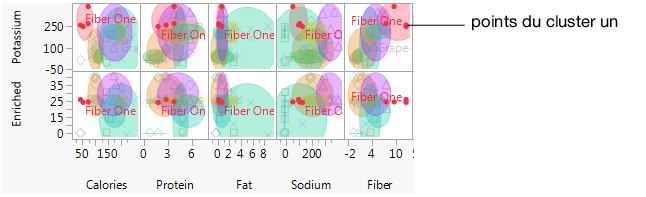
Figure 6.13 Céréales similaires dans le cluster un
Figure 6.14 Sélectionner un cluster
|
5.
|
Figure 6.15 Résumé de clusters
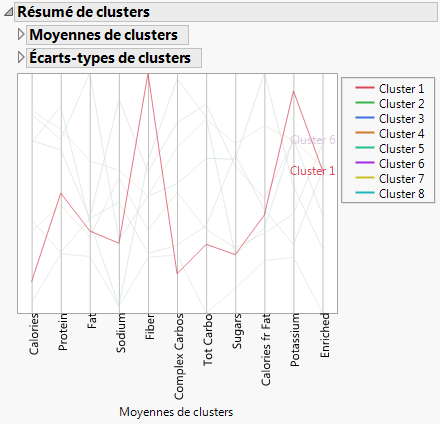
|
6.
|
Cliquez sur le triangle rouge Classification hiérarchique et sélectionnez Matrice de nuages de points.
|
Figure 6.16 Caractéristiques du cluster un