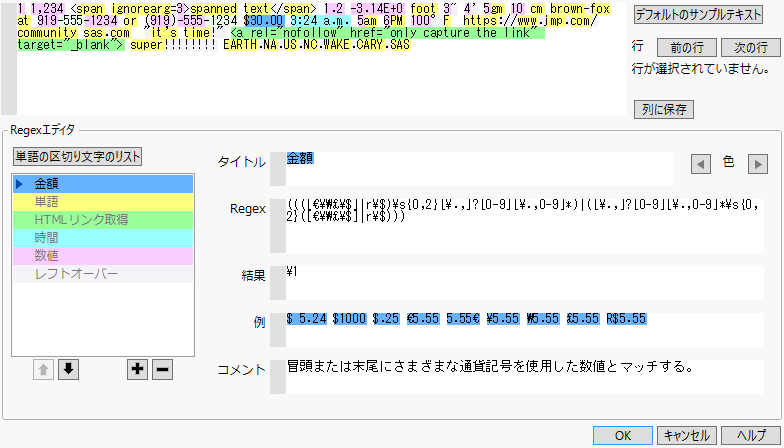
[Regexのカスタマイズ]オプションを選択すると、「テキストエクスプローラ 正規表現エディタ」ウィンドウが表示されます。このウィンドウから、電話番号、時間、金額など、予め提供されている、さまざまなビルトインの正規表現(regular expression)を選択できます。また、独自の正規表現を定義することもできます。
図12.7 テキストエクスプローラ 正規表現エディタ
|
•
|
「行」の[前の行]ボタンまたは[次の行]ボタンをクリックすると、分析対象となっているテキストがスクリプトエディタボックスに表示されます。ここで、各行のテキストがどのように構文解析されるのかを確認できます。
|
|
•
|
[列に保存]ボタンをクリックすると、この正規表現によるトークン化の結果が、データテーブルに新しい列として追加されます。正規表現を変更する方法については、第 “正規表現の編集”を参照してください。
|
メモ: [列に保存]ボタンをクリックしたときの結果には、正規表現のみがテキストのマッチに使用され、 ストップワード、再コード化、語幹抽出、句、単語あたりの最小/最大文字数の設定は使用されません。
このリストから1つまたは複数の正規表現を選択して[OK]をクリックすると、その正規表現がトークン化に使用されるようになります。ライブラリからカスタムの正規表現を削除するには、[選択アイテムを削除]ボタンを使用します。正規表現のライブラリは、ユーザごとに別のJSLファイルとして、「TextExplorer」というディレクトリに保存されます。このディレクトリの場所は、以下のとおりです。
|
•
|
Windows: "¥C:¥Users¥<ユーザ名>¥AppData¥Roaming¥SAS¥JMP¥TextExplorer¥"
|
|
•
|
Macintosh: "/Users/<ユーザ名>/Library/Application Support/JMP/TextExplorer/"
|
|
3.
|
[OK]をクリックします。
|
ヒント: 正規表現の定義フィールドを編集するときは、ログウィンドウを開いて見える状態にしておくと便利です。一部のエラーメッセージは、ログウィンドウにのみ表示されます。ログウィンドウを開くには、[表示]>[ログ]を選択します。正規表現のトラブルシューティングについては、https://regexr.com/をはじめ、インターネット上の多くの資料で解説されています。
[単語の区切り文字のリスト]をクリックすると、トークン化処理において単語の区切りと見なす文字のリストを指定できます。区切り文字は、ある1つの単語の先頭文字には使うことができません。ただし、正規表現で許可されていれば、単語の途中にある文字としては含めることはできます。[単語の区切り文字のリスト]をクリックするとウィンドウが表示され、このウィンドウで区切り文字の追加や削除を行えます。デフォルトでは、空白(ホワイトスペース)のみが区切り文字として指定されています。「区切り文字」ウィンドウで、区切り文字のリストに加えた変更を取り消すには、[リセット]ボタンをクリックします。区切り文字のリストに加えた変更は、そのときのトークン化処理にのみ適用されます。
|
–
|
|
–
|
[列に保存]ボタンをクリックすると、正規表現によるトークン化の結果が、データテーブルに新しい列として追加されます。新しい列は、データタイプが「文字」で、「テキストエクスプローラ」起動ウィンドウで[テキスト列]に指定した名前に、番号が追加されたものになります。
「テキストエクスプローラ 正規表現エディタ」ウィンドウで[OK]をクリックすると、次の一連の処理が行われます。
注意: ユーザーが独自に定義した、カスタムの正規表現がライブラリに保存されるのは、正規表現を定義した後に[OK]をクリックしたときのみです。次にライブラリを使用できるのは、最後に保存した正規表現だけです。正規表現ライブラリに定義した正規表現を保存したい場合は、固有の名前を付けてください。以前の正規表現を後で使用したい場合は、「テキストエクスプローラ」レポートウィンドウで、スクリプトを保存することもできます。