ここでは、「選択モデル」プラットフォームを使い、「ケース(症例)」と「コントロール(対照)」とでペアごとに対応している子宮内膜がんの調査結果に対して、条件付きロジスティック回帰分析を行う例を紹介します。使用するデータは、Breslow and Day(1980)で取り上げられている「Los Angeles Study of the Endometrial Cancer Data」からの引用です。このケースコントロール分析の目標は、高血圧による影響を考慮しながら、胆嚢疾患の相対リスクを推定することです。「アウトカム」の1の値は、子宮内膜がんの発症(ケース群)を示し、0はコントロール群を示します。胆嚢疾患と高血圧も、同様に1と0で示されています。
|
1.
|
[ヘルプ]>[サンプルデータライブラリ]を選択し、「Endometrial Cancer.jmp」を開きます。
|
|
2.
|
[分析]>[消費者調査]>[選択モデル]を選択します。
|
|
3.
|
「データ形式」が[1つのデータテーブル, 積み重ね]になっていることを確認します。
|
|
4.
|
[データテーブルの選択]ボタンをクリックします。
|
|
5.
|
|
6.
|
「アウトカム」を選択し、[応答の指示変数]をクリックします。
|
|
7.
|
「ペア」を選択し、[グループ]をクリックします。
|
|
8.
|
|
9.
|
[Firthバイアス調整推定値]のチェックマークを外します。
|
|
10.
|
[モデルの実行]をクリックします。
|
|
11.
|
「選択モデル」の赤い三角ボタンをクリックし、[効用プロファイル]を選択します。
|
子宮内膜がんデータのロジスティック回帰のようなレポートが作成されます。
図4.42 子宮内膜がんデータのロジスティック回帰
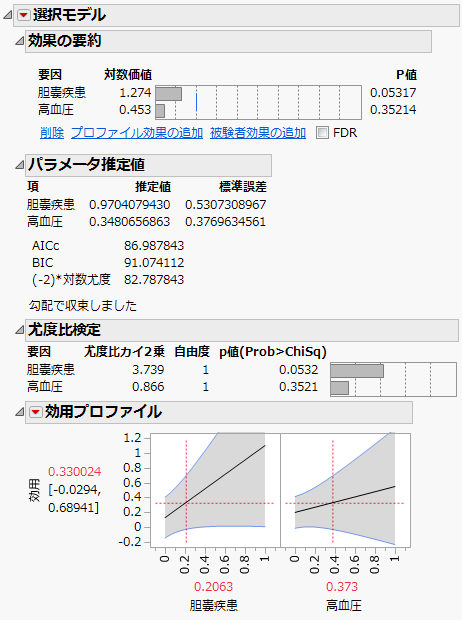
要因ごとに尤比度検定が実行されています。「胆嚢疾患」が、α水準を0.05としたとき、統計的にほぼ有意であることがわかります(p値は0.0532)。また、効用プロファイルによって、応答に対する要因の影響を視覚的に確認できます。