多重因子分析における行列Xの特異値分解は、以下のように定義することができます。
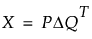 ここで、
ここで、 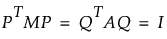
多重因子分析の詳細については、Abdi et al.(2013)を参照してください。
JMPでは、慣性(分散)を計算する際にN - 1を使用しています。これらの計算は、データ行とブロックに対するスコアの計算に影響します。