レポートの赤い三角ボタンメニューから[推定値]>[パラメータに対する検出力]を選択すると、パラメータ推定値の事後的な検出力が求められます。このオプションを選択すると、「パラメータ推定値」レポートに、有意水準を5%としたときの、最小有意値、最小有意数、調整済み検出力が表示されます。
ある効果のF検定における検出力を求めるには、その効果の赤い三角ボタンメニューから[検出力の分析]を選択します。各効果の赤い三角ボタンメニューは、手法として[要因のスクリーニング]と[最小レポート]を選んだ場合は、「効果の詳細」の下に表示されます。手法として[効果てこ比]を選んだ場合は、ウィンドウの右側に表示されます。
1つまたは複数の対比の検定における検出力を求めるには、まず、効果の赤い三角ボタンメニューから[最小2乗平均の対比]を選択します。次に、分析する対比を定義し、[完了]をクリックします。そして、「対比」の赤い三角ボタンをクリックし、メニューから[検出力の分析]を選択します。
カスタム検定における検出力を求めるには、まず、応答の赤い三角ボタンメニューから[推定値]>[カスタム検定]を選択します。次に、分析する対比を定義し、[完了]をクリックします。そして、「カスタム検定」の赤い三角ボタンをクリックし、メニューから[検出力の分析]を選択します。
δという記号で表される効果の大きさ(effect size; 効果量)は、パラメータの真値が帰無仮説からどれぐらい離れているかを表しています。帰無仮説は、1つの対比で表されることもあれば、複数の対比で表される場合もあるでしょう。δは、対比の真値が帰無仮説の値からどれぐらい離れているかを示しています。
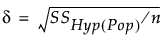
ここで、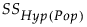 は、パラメータの真値から計算した仮説検定の平方和、nは標本サイズです。
は、パラメータの真値から計算した仮説検定の平方和、nは標本サイズです。
は、パラメータの真値から計算した仮説検定の平方和、nは標本サイズです。データから検出力を事後的に計算したい場合は、δを求める上式の平方和として、データから計算された平方和を代入します。
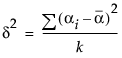
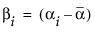
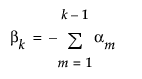
となるようにパラメータ化されています。よって、JMPで使われているパラメータで、2群のt検定におけるδを表すと、次式のようになります。
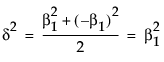
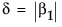
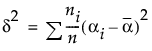
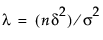
一部の書籍では(たとえば、Cohen, 1977)、JMPで使用されている生の効果の大きさではなく、標準化した効果の大きさΔ = δ/σを使用しています。標準化した効果の大きさで表した場合、非心度パラメータはλ = nΔ2になります。
「検出力の詳細」ウィンドウでは、最初、δは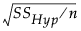 に設定されています。SSHypは仮説の平方和、nは現在のデータにおける標本サイズです。SSHypを用いて計算されたδは、真の効果の大きさではなく、それを推定した値になっています。この推定値にはバイアスがあります(Wright and O’Brien, 1988)。δの推定値を使って検出力を計算するには、[検出力を求める]ではなく、[調整済み検出力と信頼区間]で計算したほうが良いでしょう。調整済みの検出力の計算には、バイアスを調整したδの推定値が使われます。付録「統計的詳細」の「調整済み検出力の計算」(510ページ)を参照してください。
に設定されています。SSHypは仮説の平方和、nは現在のデータにおける標本サイズです。SSHypを用いて計算されたδは、真の効果の大きさではなく、それを推定した値になっています。この推定値にはバイアスがあります(Wright and O’Brien, 1988)。δの推定値を使って検出力を計算するには、[検出力を求める]ではなく、[調整済み検出力と信頼区間]で計算したほうが良いでしょう。調整済みの検出力の計算には、バイアスを調整したδの推定値が使われます。付録「統計的詳細」の「調整済み検出力の計算」(510ページ)を参照してください。
に設定されています。SSHypは仮説の平方和、nは現在のデータにおける標本サイズです。SSHypを用いて計算されたδは、真の効果の大きさではなく、それを推定した値になっています。この推定値にはバイアスがあります(Wright and O’Brien, 1988)。δの推定値を使って検出力を計算するには、[検出力を求める]ではなく、[調整済み検出力と信頼区間]で計算したほうが良いでしょう。調整済みの検出力の計算には、バイアスを調整したδの推定値が使われます。付録「統計的詳細」の「調整済み検出力の計算」(510ページ)を参照してください。標本サイズと検出力の関係をグラフで描くには、「検出力」レポートの下部にある赤い三角ボタンをクリックし、[検出力プロット]オプションを選択します。「検出力」表の「数」列に対して、検出力がプロットされます。標本サイズと検出力のプロットのグラフは、第 “検出力の事後計算の例”の「検出力」表をプロットした結果です。
図3.69 標本サイズと検出力のプロット
最小有意数(LSN; Least Significant Number)は、α(有意水準)、σ(誤差の標準偏差)、δ(効果の大きさ)が与えられているときに、 結果が有意となるのに最低限必要な標本サイズです。最小有意数に基づいて、将来の標本サイズを決めるのはお勧めできません。
|
•
|
最小有意数が実際の標本サイズであるnより小さい場合、現在の結果は有意になっています。
|
|
•
|
最小有意数がnより大きい場合、現在の結果は有意になっていません。最小有意数は、現在のデータから計算された誤差標準偏差の推定値や、データの構造がまったく変わらないという条件のもとで、検定が有意になるのに必要な標本サイズです。
|
|
•
|
|
•
|
最小有意数がnと等しいときの検出力は、常に0.5以上になります。差を検出する実験を計画するときに検出力を0.5ぐらいに設定するのは、検出力が低すぎます。
|
最小有意値(LSV; Least Significant Value)は、自由度が1である仮説検定に対して計算されます。自由度が1である仮説検定には、モデルパラメータに対する検定や、より一般的な対比に対する検定があります。最小有意値は、検定が有意となるパラメータ値の最小値です。最小有意値は、確率ではなく、パラメータ値を単位として検定の有意度を表していると言えます。
|
•
|
パラメータ推定値の絶対値または対比が最小有意値以上の場合、現在のデータから得られるp値はα以下になります。
|
|
•
|
パラメータ推定値の絶対値または対比が最小有意値と等しい場合、現在のデータから得られるp値はちょうどαになります。
|
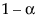 の両側信頼区間の半分になっています。なお、
の両側信頼区間の半分になっています。なお、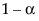 信頼区間の中心は、その点推定値です。
信頼区間の中心は、その点推定値です。ある検定の検出力は、その検定が有意となる確率です。検出力は、効果の大きさδ、有意水準α、誤差の標準偏差σ、および標本サイズnの関数です。検出力は、指定した有意水準で、指定した効果の大きさを検出できる確率です。実質的または科学的に意味がある大きさをもつ効果を高い確率で検出できるような実験を計画するのが望ましいです。
検出力の事後計算では、検出力を計算するにあたって、母集団での真値ではなく、 標本の推定値を用います。そのままの値を代入して計算した非心度パラメータの推定値には、正のバイアスがあります(Wright and O’Brien, 1988)。調整済み検出力の計算は、このバイアスを修正した非心度パラメータ推定値を用います。
調整済み検出力は、バイアスを調整した、より適切な検出力になっています。信頼区間も計算されますが、その区間の幅は広くなる傾向にあります。Wright and O’Brien(1988)を参照してください。
調整済み検出力とその信頼区間は、データから求められるδの推定値(デフォルトで求められた値)だけに対して計算できます。δに任意の値を分析者が設定して、調整済み検出力や信頼区間を求めることはできません。
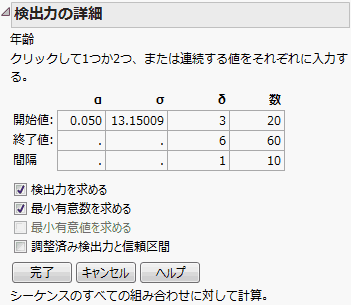
この例では、「Big Class.jmp」サンプルデータを使って、検出力の事後計算を説明します。「検出力の詳細」ウィンドウ(「年齢」の「検出力の詳細」ウィンドウ)で、α、σ、δ、および数の値の範囲にさまざまな値を入力し、 [完了]をクリックすると、検出力の結果が表示されます。
|
1.
|
[ヘルプ]>[サンプルデータライブラリ]を選択し、「Big Class.jmp」を開きます。
|
|
2.
|
[分析]>[モデルのあてはめ]を選択します。
|
|
3.
|
「体重(ポンド)」を選択し、[Y]をクリックします。
|
|
4.
|
|
5.
|
[実行]をクリックします。
|
|
6.
|
「年齢」タイトルバーの赤い三角ボタンをクリックし、[検出力の分析]を選択します。
|
図3.70 「年齢」の「検出力の詳細」ウィンドウ
|
7.
|
|
8.
|
|
9.
|
「検出力を求める」と「最小有意数を求める」にチェックマークをつけます。
|
|
10.
|
[完了]をクリックします。
|
|
11.
|
「年齢」の「検出力の詳細」レポートのような「検出力の詳細」レポートが表示されます。
|
図3.71 「年齢」の「検出力の詳細」レポート
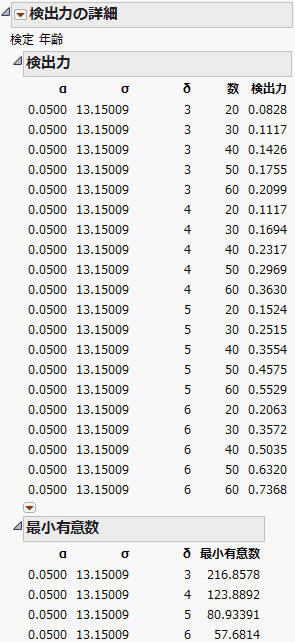
この分析は、「Big Class.jmp」サンプルデータから得られた結果をもとに検出力を事後的に求めています。このようにデータを得た後に検出力を求めることを、「検出力の事後計算」と言います。たとえば、この例では、σの値として、現在のデータから得られた推定値を用いています。その推定値は、データ値やモデルに含める効果によって変化します。σの真値は、その推定値とは大きく異なるかもしれません。
3群の平均を比較する例を取り上げてみましょう。高い検出力をもつための標本サイズを求めるには、まず、[実験計画(DOE)]>[標本サイズ/検出力]を選択し、[k標本平均]を選択します。「標準偏差」のテキスト入力ボックスに誤差の標準偏差(の予想される値)を入力します。次に、平均のリストに、(検出したい差をもつ)平均の値をキーボードで入力します。たとえば、ある1群と他の2群との平均差が8である状況を検出したい場合には、40、40、48というように入力します。検出力は平均間の差だけに依存しますので、0、0、8などと入力しても構いません。
この状態で[続行]をクリックすると、検出力と標本サイズのグラフが表示されます。「標本サイズ」ウィンドウで、「検出力」または「標本サイズ」を入力すると、もう一方の値が自動的に計算され、「標本サイズ」ウィンドウに表示されます。なお、求められた標本サイズは全体での標本サイズです。[k標本平均]の計算では、グループごとの標本サイズは等しいと仮定されています。1群あたりの標本サイズを得るには、得られた標本サイズを3で割ってください。k標本平均の詳細については、『実験計画(DOE)』の「検出力と標本サイズ」章を参照してください。
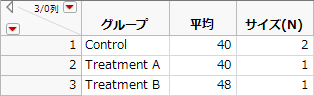
図3.72 「Bacteria.jmp」データテーブル
|
•
|
「グループ」列は、群の名前を含んでいます。
|
|
•
|
「平均」列で、検出したい差を定義しています。ここでは、コントロール群の平均を40としています。どちらかの処置群の平均がコントロール群の平均よりも少なくとも8だけ大きい場合に、その差を検出する計画を立てるのがここでの目的です。そこで、2つの処置群のいずれかに、48という平均を割り当てます。そして、もう一方の処置群の平均には、コントロール群と同じ40という平均を割り当てます。なお、コントロール群といずれか一方の処置群に平均0を割り当てて、もう一方の処置群に平均8を割り当てても同じ結果となります。また、これらの平均値や差は、母集団での平均値や差です。
|
|
•
|
「サイズ(N)」列には、各群の相対的な標本サイズを指定します。この列では、コントロール群の標本サイズを各処置群のサイズの倍にすることが指定されています。ここでは、1と2を指定していますが、2と4などを指定しても構いません。
|
次に、「モデルのあてはめ」を使って一元配置分散分析を行います(バクテリア調査の「モデルのあてはめ」起動ウィンドウ)。起動ウィンドウで、「サイズ(N)」を[度数]に指定します。また、「平均」を[Y]に、「グループ」をモデル効果に指定します。最後に、[最小レポート]オプションを選択します。
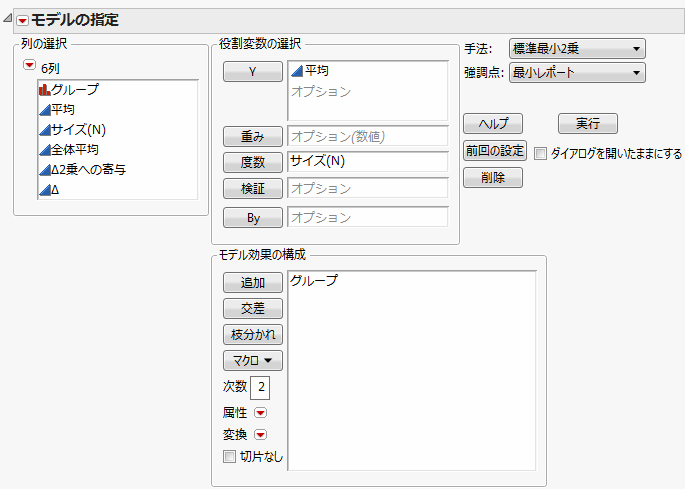
[実行]をクリックすると、「最小2乗法によるあてはめ」レポートが表示されます。データには誤差がないため、誤差の標準偏差や平方和は0.0になっています。検出力を求めるには、想定される誤差分散の範囲を入力します。ここでは、誤差分散は5から6までの大きさだと想定します。
|
2.
|
「グループ」の横にある赤い三角ボタンをクリックし、メニューから[検出力の分析]を選択します。
|
|
3.
|
|
4.
|
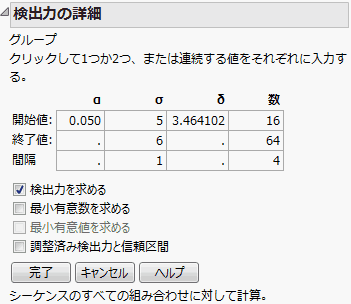
δには「3.464102」と入力されています。この効果の大きさは、サンプルデータに入力されているグループ平均から計算されています。なお、サンプルデータには、効果の大きさを計算する式を含む列が、非表示の状態で3列あります (第 “バランスのとれていない一元配置”を参照)。
|
|
5.
|
|
6.
|
[検出力を求める]にチェックを入れます。
|
|
7.
|
[完了]をクリックします。
|
図3.74 バクテリア調査の「検出力の詳細」ウィンドウ
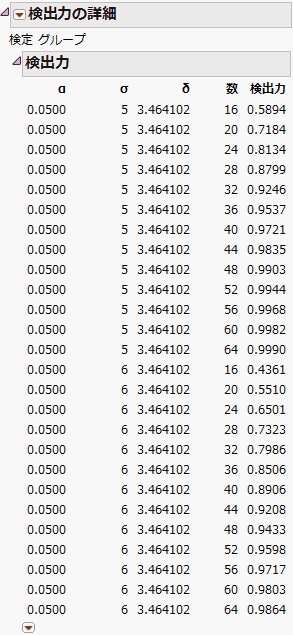
バクテリア調査の「検出力の詳細」レポートのような「検出力の詳細」レポートが表示されます。このレポートには、16~64までの4刻みの標本サイズ、σ = 5および6、α = 0.05での検出力が表示されています。σ = 5のとき、90%以上の検出力を得るには、全体の標本サイズを32にする必要があります。つまり、コントロール群の標本サイズを16、各処置群の標本サイズを8にする必要があります。一方、σ = 6のときは、全体の標本サイズを44にする必要があります。
図3.75 バクテリア調査の「検出力の詳細」レポート
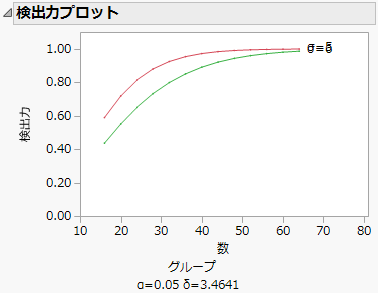
バクテリア調査の「検出力プロット」は、2つのσの値において、標本サイズに対して検出力をプロットしたグラフです。このグラフを表示するには、「検出力の詳細」レポートの表の最下部にある赤い三角ボタンをクリックします。この図では、赤色の曲線がσ = 5 に対応し、緑色の曲線がσ = 6 に対応しています。
図3.76 バクテリア調査の「検出力プロット」