「Diabetes.jmp」サンプルデータテーブルには、病症の進行をモデル化するのに使われる10個の説明変数が含まれています。この例では、それらの連続尺度の変数をクラスタリングします。
|
1.
|
[ヘルプ]>[サンプルデータライブラリ]を選択し、「Diabetes.jmp」を開きます。
|
|
2.
|
[分析]>[クラスター分析]>[変数のクラスタリング]を選択します。
|
|
3.
|
「性別」を除く「年齢」から「グルコース」までの列(「年齢」、「BMI」、「血圧」、「総コレステロール」、「LDL」、「HDL」、「TCH」、「LTG」、「グルコース」)を選択し、[Y, 列]をクリックします。
|
[変数のクラスタリング]では数値の連続変数を使用する必要があるため、「性別」の列は含めることができません。
|
4.
|
[OK]をクリックします。
|
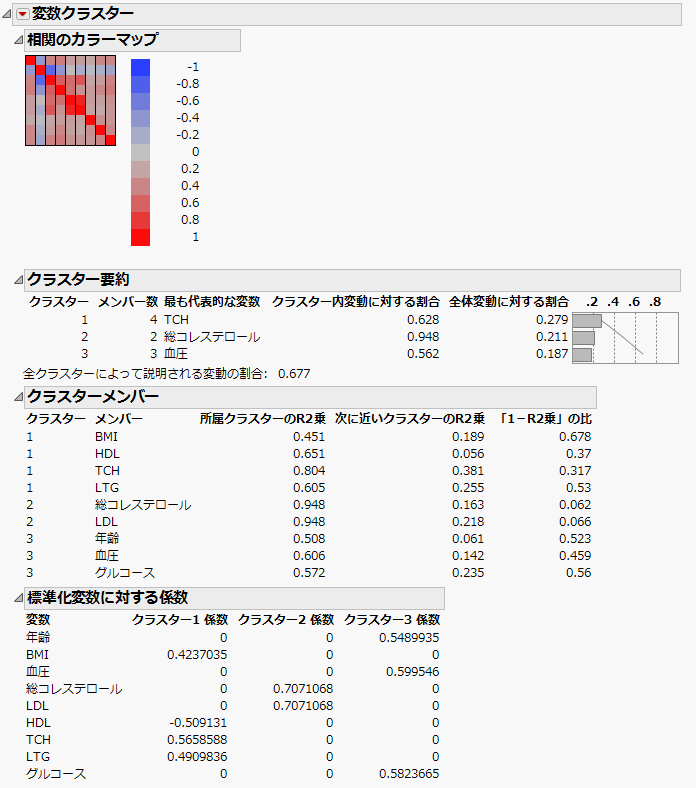
「Diabetes.jmp」の「変数のクラスタリング」レポートは、「変数のクラスタリング」を実行した結果です。「クラスター要約」レポートを見ると、変数は3つのクラスターにグループ化されています。
|
•
|
「クラスターメンバー」レポートを見ると、クラスター1は「BMI」、「HDL」、「TCH」、「LTG」で構成されています。「クラスター要約」レポートを見ると、クラスター1の最も代表的な変数は「TCH」です。また、クラスター1のクラスター成分によって、これら4変数がもつ変動の62.8%を説明していることがわかります。
|
|
•
|
クラスター2は、「総コレステロール」と「LDL」の2つだけで構成されています。「クラスター要約」レポートを見ると、クラスター2の最も代表的な変数は「総コレステロール」です。また、クラスター2のクラスター成分によって、これら2変数がもつ変動の94.8%を説明していることがわかります。
|
|
•
|
クラスター3は、年齢、血圧、 グルコースで構成されています。「クラスター要約」レポートを見ると、クラスター3の最も代表的な変数はBPです。また、クラスター3のクラスター成分によって、これら3変数がもつ変動の56.2%を説明していることがわかります。
|