この例では、まず「Tablet Measurements.jmp」にある、非正規分布に従う3つの変数に対し、工程能力分析を行います。その後、シミュレーション機能を使用して「純度」の不適合率に対する信頼限界を求めます。
|
1.
|
[ヘルプ]>[サンプルデータライブラリ]を選択し、「Tablet Measurements.jmp」を開きます。
|
|
2.
|
[分析]>[品質と工程]>[工程能力]を選択します。
|
|
3.
|
|
4.
|
|
5.
|
「分布のオプション」アウトラインを開きます。
|
|
6.
|
「分布」リストから[最良]を選択します。
|
|
7.
|
[工程分布の設定]をクリックします。
|
右側のリストにある列名に、「&分布(最良)」という接尾辞が追加されます。
|
8.
|
[OK]をクリックします。
|
「工程能力指数プロット」が作成され、Ppkの値が表示されます。「厚さ」の変数だけが、Ppk = 1の線より上に位置しています。「純度」はほぼ線上にあります。測定値の個数は250で少なくないように思うかもしれせんが、Ppkの推定値はばらつきが大きくなっています。「純度」Ppk値に対する信頼区間を計算して、そのことを確認してみましょう。
|
9.
|
「工程能力分析」の赤い三角ボタンのメニューから、[各列に対する詳細レポート]を選択します。
|
|
–
|
「重さ」: 対数正規
|
|
–
|
「厚さ」: Johnson Sb(「工程能力 厚さ(Johnson)」というレポートタイトルの下のメモを参照)
|
|
–
|
「純度」: Weibull
|
シミュレーション機能を使ってPpkの信頼限界を推定するには、あてはめたWeibull分布を反映したシミュレーション計算式を作成する必要があります。以下の手順を自分で実行しなくても、「シミュレーション列の追加」テーブルスクリプトを実行すれば、同じ結果が得られます。
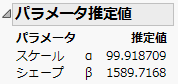
図11.27 「純度」のWeibullパラメータ推定値
|
2.
|
「Tablet Measurements.jmp」サンプルデータテーブルで、[列]>[列の新規作成]を選択します。
|
|
3.
|
「列名」として「Simulated Purity」を入力します。
|
|
4.
|
「列プロパティ」リストから[計算式]を選択します。
|
|
5.
|
計算式エディタで、[乱数]>[Random Weibull]を選択します。
|
|
6.
|
「beta」のプレースホルダーが選択されています。画面上部のアイコン一覧より、挿入アイコン(^)をクリックします。
|
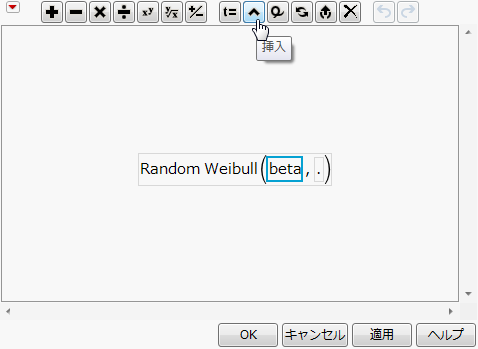
これで、alphaパラメータのプレースホルダーが追加されます。
|
7.
|
「パラメータ推定値」レポートの任意の箇所で右クリックし、[データテーブルに出力]を選択します。
|
|
8.
|
作成されたデータテーブルの行2の「推定値」列の値をコピーします(1589.7167836)。
|
|
9.
|
|
10.
|
「パラメータ推定値」レポートから作成したデータテーブルで、行1の「推定値」列の値をコピーします(99.918708989)。
|
|
11.
|
図11.29 入力後の計算式ウィンドウ

|
12.
|
計算式エディタウィンドウで[OK]をクリックします。
|
|
13.
|
「列の新規作成」ウィンドウで[OK]をクリックします。
|
「Simulated Purity」列には、最良の分布から値をシミュレーションする計算式が含まれています。
シミュレーション機能を使うと、分析全体が指定の回数だけ実行されます。必要な分析だけを実行し、計算の負担を減らせば、計算時間が短くなります。この例では、Weibull分布があてはめられた「純度」だけに興味があるので、シミュレート機能を実行する前に、「純度」の分析だけを行います。
|
1.
|
「工程能力分析」レポートで、「工程能力分析」の赤い三角ボタンのメニューから[ダイアログの再起動]を選択します。
|
|
3.
|
|
4.
|
[削除]をクリックします。
|
|
5.
|
[OK]をクリックします。
|
|
6.
|
「工程能力分析」の赤い三角ボタンのメニューから、[各列に対する詳細レポート]を選択します。
|
PpkとPplの両方の値が計算されていますが、値は同じです。なぜなら、「純度」には下側仕様限界しかないためです。
|
7.
|
|
8.
|
「標本数」のボックスに「500」を入力します。
|
|
9.
|
|
10.
|
[OK]をクリックします。
|
計算には、多少時間がかかります。「工程能力 シミュレーション結果(推定値)」というデータテーブルが開きます。このデータテーブルにある「Ppk」と「Ppl」の各列には、「Simulated Purity」の計算式に基づいて計算した500の値が含まれます。最初の行は、「純度」のデータに対して得られた元の値を含んでいます。この行の属性には除外が与えられています。「純度」は下側仕様限界しか持たないので、「Ppk」と「Ppl」の値は同じになります。
|
11.
|
「工程能力 シミュレーション結果(推定値)」データテーブルで、「一変量の分布」スクリプトの緑色の三角ボタンをクリックします。
|
図11.30 シミュレーションで求めた「純度」のPpk値の分布
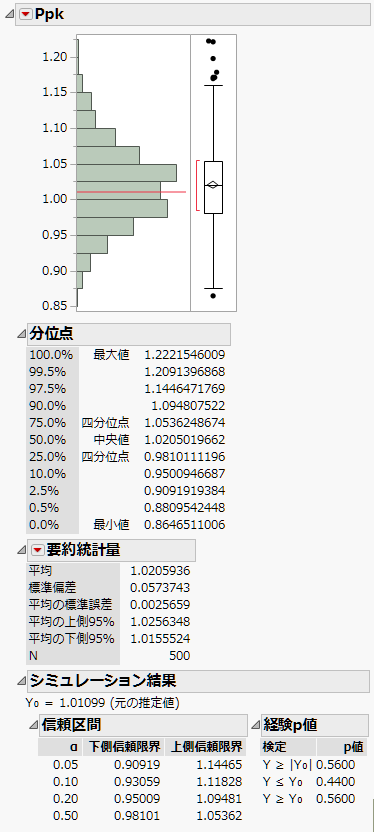
PpkとPplの2つの「一変量の分布」レポートが表示されます。ただし、「純度」は下側仕様限界しか持たないため、PpkとPplの値は同じです。そのため、「一変量の分布」レポートも内容は同じです。
「シミュレーションの結果」レポートを見ると、Ppkの95%信頼区間は0.909~1.145です。真のPpkの値は、1.0より大きい可能性は否定できません。つまり、「純度」に対する結果は、第 “非正規分布の工程能力分析”で作成した「工程能力指数プロット」のPpk = 1の線より上に位置しているのかもしれません。
|
12.
|
|
13.
|
「標本数」のボックスに「500」を入力します。
|
|
14.
|
|
15.
|
[OK]をクリックします。
|
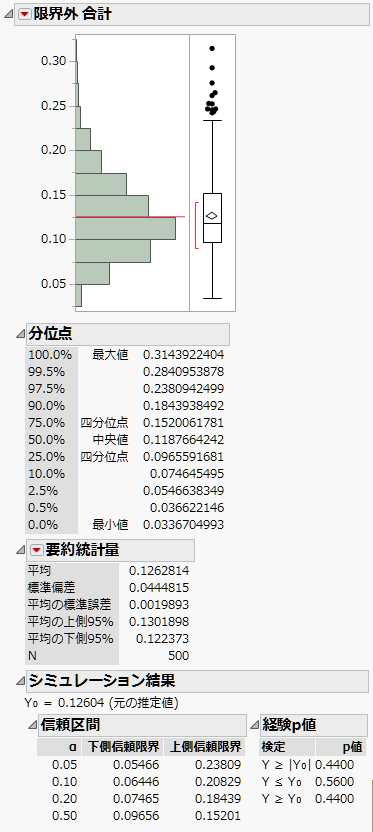
計算には、多少時間がかかります。「工程能力 シミュレーション結果(全体σ %)」というデータテーブルが開きます。「純度」には下側仕様限界しかないため、「LSL未満」の値は「限界外 合計」と一致します。
|
16.
|
「工程能力 シミュレーション結果(全体σ %)」データテーブルで、「一変量の分布」スクリプトの緑色の三角ボタンをクリックします。
|
図11.31 「純度」の「限界外 合計」をシミュレーションした値の分布