|
•
|
|
•
|
|
•
|
|
•
|
|
•
|
|
•
|
連続尺度の数値データを持つ列の場合、[分布]プロパティを使用して、列にあてはめる分布の種類を選びます。この分布は「一変量の分布」プラットフォーム、および特定の条件下での「工程能力分析」プラットフォームで使用されます。詳細については、第 “分布と工程能力分布”を参照してください。
その列に対して「一変量の分布」レポートを作成すると([分析]>[一変量の分布]を選択)、常に、指定された分布を使って自動的にあてはめが行われます。あてはめた分布を表す曲線は、ヒストグラム上で重ねて表示されます。
|
•
|
独自の境界線データが、デフォルトで決められている地図ディレクトリにある場合、-Nameファイル内で「地図の役割」プロパティを指定しておけば地図を表示できます。
|
|
•
|
独自の境界線データが別の場所にある場合、-Nameファイル内と分析を行うデータテーブル内の両方で「地図の役割」プロパティを指定する必要があります。
|
「地図の役割」を使用した例については、『グラフ機能』の「地図の作成」章を参照してください。
|
1.
|
境界線を含む列を右クリックし、[列プロパティ]>[地図の役割]を選びます。
|
|
2.
|
[シェープ名の定義]を選びます。
|
|
3.
|
[OK]をクリックします。
|
|
1.
|
境界線を含む列を右クリックし、[列プロパティ]>[地図の役割]を選びます。
|
|
2.
|
[使用するシェープ名]を選びます。
|
|
3.
|
|
4.
|
「シェープ定義の列」の横に、選択している列に対応する値を含む、地図データテーブル内の列の名前を入力します。
|
|
5.
|
[OK]をクリックします。
|
|
2.
|
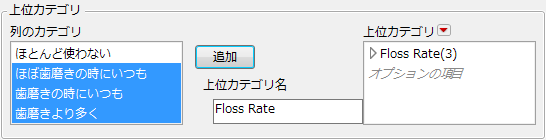
[列プロパティ]>[上位カテゴリ]を選択します。
|
|
5.
|
[追加]をクリックすると、上位カテゴリが作成されます。
|
|
6.
|
「上位カテゴリ」の赤い三角ボタンのメニューをクリックして、次のオプションを選択します。
|
|
–
|
[オプション]>[非表示]: 選択した上位カテゴリのデータをレポートおよびグラフで非表示にします。
|
|
–
|
[すべて追加]: 列のすべてのカテゴリから上位カテゴリを作成します。
|
|
–
|
[平均を追加]と[標準偏差を追加]: 値スコアの統計量を計算します。詳細については、『消費者調査』を参照してください。
|
|
7.
|
[OK]をクリックして、上位カテゴリをプロパティに追加します。
|
図5.5 上位カテゴリの設定例
多重応答とは、列のセルの中に複数の応答値が含まれている状態を指します。たとえば、「Consumer Preferences.jmp」サンプルデータテーブルの「歯磨き カンマ区切り」列内の多くのセルには複数の値が含まれています。行6を見てください。そこには“Wake, After Meal, Before Sleep”というデータが含まれています。
カンマ以外の区切り文字を指定したい場合は、「多重応答」列プロパティを追加します。それ以外の場合は、列情報ウィンドウで列の尺度を多重応答に変更します。多重応答尺度の詳細については、第 “尺度について”を参照してください。
図5.6 「多重応答」の設定ウィンドウ
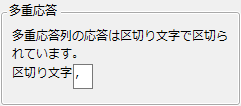
メモ: 「多重応答」プロパティは「カテゴリカル」プラットフォームで使用できます。詳細については、『消費者調査』の「カテゴリカルな応答の分析」章を参照してください。このプロパティは、データフィルタでも使用できます。詳細については、「JMPのレポート」章の「データフィルタ」(387ページ)を参照してください。区切り文字がカンマの場合は、代わりに多重応答尺度の使用を検討してください。
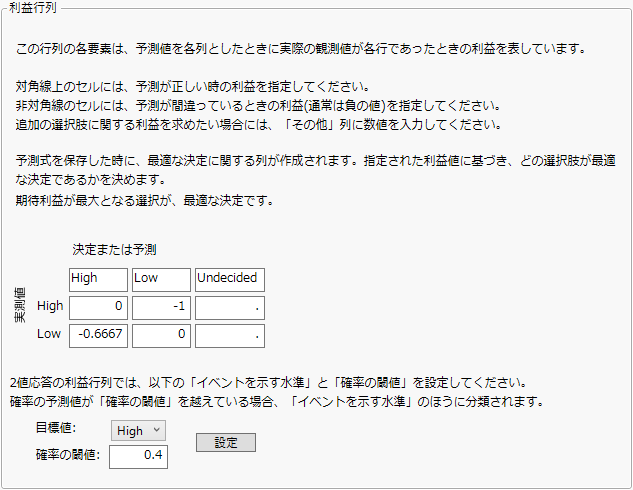
[列プロパティ]>[利益行列]を選択すると、選択した列の各値を行および列とした行列テンプレートが表示されます。実測水準は行として表示され、予測された水準は列として表示されます。対角線上のセルは予測が正しいときのものであり、予測された水準と実測水準が一致しています。
ここでは、閾値の確率をtで表します。[設定]をクリックすると、利益行列の各セルは次のように割り当てられます。
|
•
|
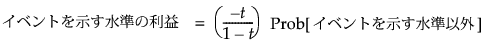
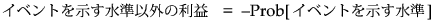
「利益が最大となる予測値」は、利益がこれらの2つの値の大きい方となる水準です。上記の2つの利益の式から、Prob[イベントを示す水準]が少なくともtに設定されているときには、オブザベーションがイベントを示す水準に割り当てられるという結果が導き出されます。
|
•
|
<水準>の利益: 応答の各水準について、各オブザベーションをその水準に分類するための期待利益が与えられます。
|
|
•
|
<列名>の予測値: 各オブザベーションについて、予期された利益が最も高い応答の水準が与えられます。
|
|
•
|
<column name>の期待利益: 各オブザベーションについて、(利益が最大となる)予測値によって定義されている分類の期待利益が与えられます。
|
|
•
|
<column name>の実測利益: 各オブザベーションについて、そのオブザベーションを(利益が最大となる)予測値の列で指定されている水準に分類するための実測水準が与えられます。
|
詳細については、第 “3水準以上の利益行列の例”を参照してください。モデル化で利益行列を使用する例については、『予測モデルおよび発展的なモデル』の「パーティション」章を参照してください。
図5.7 「利益行列」ウィンドウの例
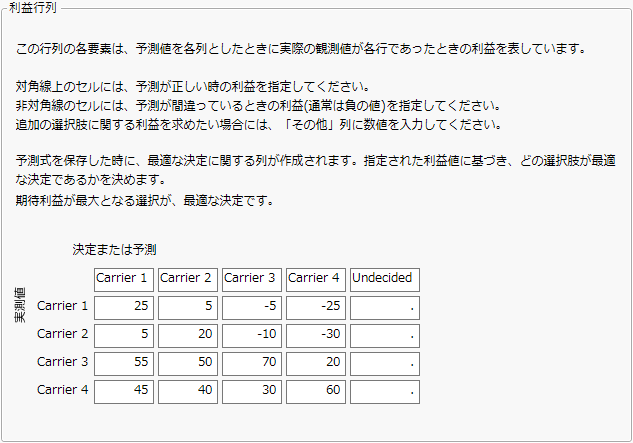
この利益行列の値がどのように割り当てられたのかを理解するために、4つの航空会社Carrier 1~Carrier 4を使用して顧客に対応している旅行代理店について考えてみましょう。旅行代理店は、販売した各航空券について、顧客が選んだ航空会社に応じた利益を得ます。旅行代理店は、航空会社を顧客に勧めた、つまり予測した段階で、航空券を予約し、予約金を支払います。顧客が予測された航空会社の使用を決めた場合、予約金を差し引いた所定の金額が旅行代理店の利益となります。しかし、顧客が別の航空会社を選んだ場合は、支払い済みの予約金が無駄になるうえ、別の予約金を払わなければならなくなります。旅行代理店の利益は、間違った予測のため少なくなります。
「Liver Cancer.jmp」サンプルデータテーブルには、136人の患者に対する病気の「重症」度の評価データが含まれています。「BMI」から「黄疸」までの列で与えられている予測値を使用して「重症」をモデル化してみましょう。モデルの通常の予測式では、患者が最も確率の高い「重症」水準に割り当てられます。しかし、重症度が実際にはHighである患者をLowに分類してしまうことは、重症度が実際にはLowである患者をHighに分類してしまうよりも重大な間違いです。そこで、重要度が実際にはHighである患者を間違ってLowに分類することに対し、より高いコストを設定することにします。
確率の閾値を設定することによりこのコストが割り当てられます。あなたは、専門家の意見を基にして、水準値がHighとなる確率の予測値が0.4を超える患者を「重症」のHighの水準に分類することにしました。
|
1.
|
[ヘルプ]>[サンプルデータライブラリ]を選択し、「Liver Cancer.jmp」を開きます。
|
|
2.
|
「重症」列を選択し、[列]>[列情報]を選択します。
|
|
4.
|
「目標値」を[High]に変更します。
|
|
5.
|
「確率の閾値」に0.4と入力します。
|
|
6.
|
[設定]をクリックします。
|
図5.8 確率の閾値に対応する重みを示した利益行列