図13.8 [テキストデータファイル]の環境設定
|
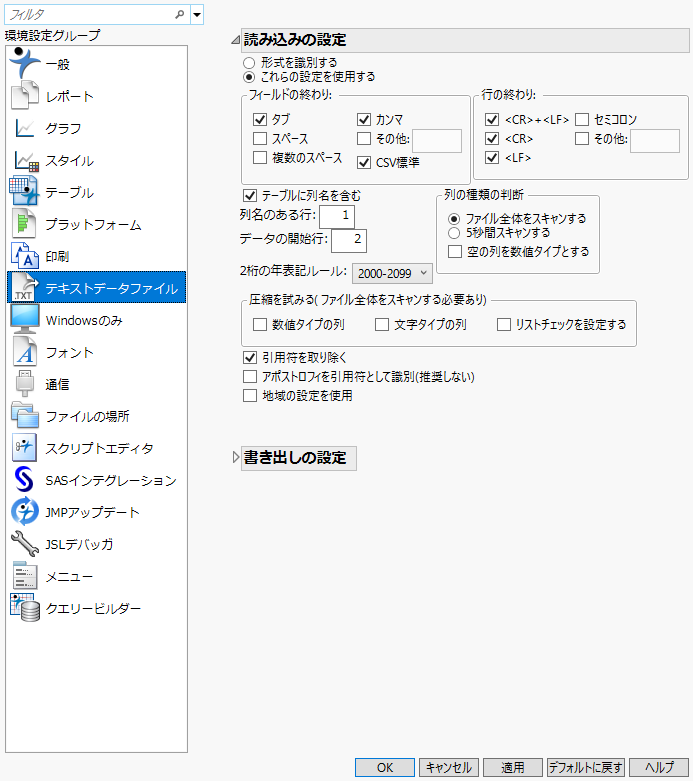
JMPでテキストファイルを開く方法を指定します。デフォルトでは、[これらの設定を使用する]が選択されています。この場合は、読み込むテキストファイルの形式に合った設定を、このウィンドウで指定しておく必要があります。
[形式を識別する]を選択した場合は、テキストファイル内のタブ、カンマ、空白などの文字がカウントされ、決められたルールに基づいてファイル形式が自動認識されます。ルールに従って、フィールド幅と1行のフィールド数が推測されます。実際のデータの形式が、ルールによって認識可能な形式と大幅に異なる場合は、自動認識が正しく機能しません。その場合は、ウィザードを使用するか、環境設定でデータの形式を指定しておく必要があります。
|
|||||
|
リストに表示されていない区切り文字を指定する場合は、[その他]チェックボックスをオンにし、文字を入力します。
|
|||||
|
リストに表示されていない区切り文字を指定する場合は、[その他]チェックボックスをオンにし、文字を入力します。
|
|||||
|
テキストファイルに列名が含まれている場合は、このチェックボックスをオンにします。このオプションを選択した場合は、列名が含まれている行の番号を[列名のある行]の横のフィールドに入力します。
|
|||||
|
[テーブルに列名を含む]チェックボックスをオンにした場合は、列名が含まれている行の番号をこのフィールドに入力します。
|
|||||
|
列のデータタイプを認識するためにテキストファイルをスキャンする長さを設定します。デフォルトで[ファイル全体をスキャンする]が選択されています。[ファイル全体をスキャンする]オプションを選択した場合は、テキストファイルが大きいときは読み込みに時間がかかります。[5秒間スキャンする]への変更を検討してください。
すべての値が欠測値となっている列がテキストファイルに含まれている場合、[空の列を数値タイプとする]を選択すると、それらの列が、文字型ではなく、数値型として読み込まれます。ピリオド、Unicodeのドット、NaN、または、空の文字列は欠測値と見なされます。このオプションは、デフォルトではオフになっています。
|
|||||
|
|||||
|
リストに表示されていない区切り文字を指定する場合は、[その他]チェックボックスをオンにし、文字を入力します。
|
|
|
リストに表示されていない区切り文字を指定する場合は、[その他]チェックボックスをオンにし、文字を入力します。
|