 カテゴリカルな応答変数に対するブートストラップ森の例
カテゴリカルな応答変数に対するブートストラップ森の例
この例では、顧客の信用リスクが悪いかどうかを予測するブートストラップ森モデルを構築します。また、データセットには欠測値が含まれていることがわかっているため、データがどれぐらい欠測しているかも調べてみます。
 ブートストラップ森のモデル
ブートストラップ森のモデル
1. [ヘルプ]>[サンプルデータライブラリ]を選択し、「Equity.jmp」を開きます。
2. [分析]>[予測モデル]>[ブートストラップ森]を選択します。
3. 「BAD」を選択し、[Y, 目的変数]をクリックします。
4. 「LOAN」から「DEBTINC」までを選択し、[X, 説明変数]をクリックします。
5. 「Validation」列を選択し、[検証]ボタンをクリックします。
6. [OK]をクリックします。
7. 「ツリーあたりの最大分岐数」の横に「30」と入力します。
8. [項数に対する複数のあてはめ]を選択し、「項の最大数」の横に「5」と入力します。
9. (オプション)[マルチスレッドをオフにする]を選択し、「乱数シード値」の横に「123」と入力します。
ブートストラップ森では無作為抽出が行われるため、上記の操作を行うことにより、下の図とまったく同じ結果を得ることができます。
10. [OK]をクリックします。
図5.2 「全体の統計量」レポート
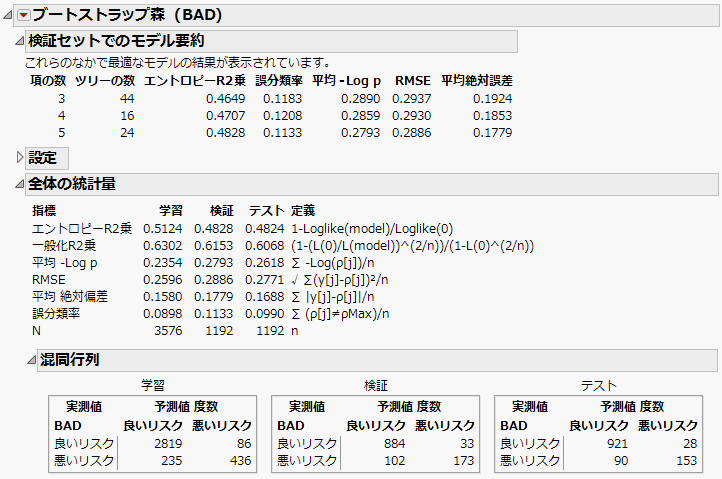
[項数に対する複数のあてはめ]オプションでの指定に従って、各分岐で説明変数が3~5個、抽出されます。「検証セットでのモデル要約」レポートを見ると、検証セットにおいて「エントロピーR2乗」が最大となるのは、各分岐で説明変数を5個、抽出したモデルです。このモデルは、誤分類率も最小になっています。このモデルが最良のモデルであり、「全体の統計量」レポートには、このモデルの結果が表示されています。
「全体の統計量」レポートを見ると、「検証」セットと「テスト」セットの誤分類率が、それぞれ11.3%と9.9%になっています。また、混同行列を見ると、誤分類においては、「信用リスクが悪い顧客を信用リスクが良いとして分類している」ほうが多いことが分かります。
「テスト」セットの結果は、将来の独立したデータに対する予測精度を示します。「検証」セットは現在のブートストラップ森モデルを選択する際に使用されました。そのため、「検証」セットの結果は、独立した将来のデータに一般化するには、バイアス(偏り)をもっています。
次に、このモデルに最も寄与している説明変数を見てみましょう。
11. 「ブートストラップ森(BAD)」の横にある赤い三角ボタンをクリックし、[列の寄与]を選択します。
図5.3 「列の寄与」レポート
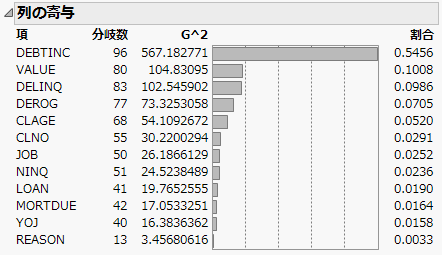
「列の寄与」レポートを見ると、顧客の信用リスクに関する最も強い説明変数は「DEBTINC」であることがわかります。これは、収入に対する債務の比です。その次に大きく寄与しているのは、顧客の評価である「VALUE」や、滞納している支払いの回数である「DELINQ」です。
 欠測値
欠測値
次に、説明変数がどれぐらい欠測値になっているかを調べてみましょう。
1. [分析]>[スクリーニング]>[欠測値を調べる]を選択します。
2. 「BAD」から「DEBTINC」までを選択し、[Y, 列]をクリックします。
3. 表示される警告で、[OK]をクリックします。
「REASON」と「JOB」は、値のデータタイプが文字型であるため、これらの列は[Y, 列]リストに追加されません。これらの2つの列にどのくらいの欠測値があるかを見るには、「一変量の分布」プラットフォームを使用してください(この例では図示されていません)。
4. [OK]をクリックします。
図5.4 欠測値のレポート
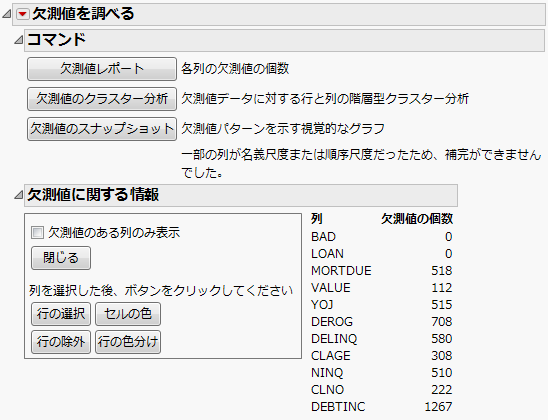
「DEBTINC」列には1267個の欠測値があり、これはオブザベーション数の約21%に相当します。また、その他のほとんどの列にも欠測値があります。先ほどの例では起動ウィンドウにある[欠測値をカテゴリとして扱う]オプションを用いましたが、その場合、これらの欠測値を含んだデータも分析に使われます。欠測値をカテゴリとして扱うを参照してください。