 検証列の作成例
検証列の作成例
「Lipid Data.jmp」データテーブルは、カリフォルニア州の、ある病院で収集された、95人の患者に関する血液測定値・身体測定値・質問票データです。今後の分析に使用する検証列をしてみます。
1. [ヘルプ]>[サンプルデータライブラリ]を選択し、「Lipid Data.jmp」を開きます。
2. [分析]>[一変量の分布]を選択します。
3. 「性別」を選択し、[Y, 列]をクリックします。
4. [OK]をクリックします。
図11.1 「Lipid Data.jmp」での「性別」の分布
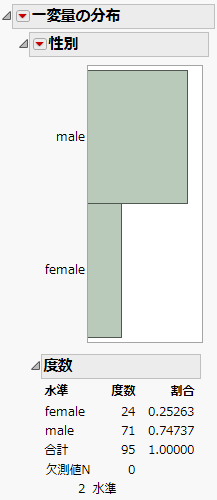
図11.1は、データ内の「性別」の分布を示しています。被験者の男性と女性の割合は同じではないことに注目してください。女性のデータのほうが少ないので、検証セットと学習セット全体では性別のバランスをとる必要があります。
5. [分析]>[予測モデル]>[検証列の作成]を選択します。
6. 「性別」を選択し、[層別の列]をクリックします。
7. [OK]をクリックします。
「検証列の作成」レポートが開き、選択した検証手法の説明が表示されます。ここには、割合や列の種類を変更するオプションや、シード値を設定するオプションもあります。
8. (オプション)レポートの「オプション」セクションにある「乱数シード値」フィールドに「1234」と入力します。
9. [実行]をクリックします。
データテーブルに「検証」列が追加されます。モザイク図を作成すると、検証セットと学習セットの分布を確認できます。
10. [分析]>[二変量の関係]を選択します。
11. 「検証」を[Y, 目的変数]に、「性別」を[X, 説明変数]に割り当てます。
12. [OK]をクリックします。
図11.2 検証セットと学習セットにおける性別の分布
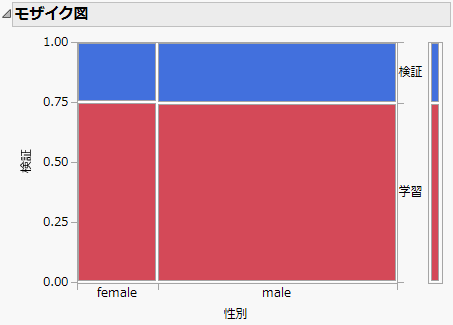
図11.2は、検証セットと学習セットにおける「性別」の分布を示しています。男性と女性それぞれの約75%が学習セットに、男性と女性それぞれの約25%が検証セットに含まれていることがわかります。