「パーティション」プラットフォームの例
この例では、「パーティション」プラットフォームを使用して、糖尿病患者の1年間にわたる症状進行(LowまたはHigh)を予測するディシジョンツリーを作成します。
1. [ヘルプ]>[サンプルデータライブラリ]を選択し、「Diabetes.jmp」を開きます。
2. [分析]>[予測モデル]>[パーティション]を選択します。
3. 「Y 2値」を選択し、[Y, 目的変数]をクリックします。
4. 「年齢」から「グルコース」までを選択し、[X, 説明変数]をクリックします。
5. 「検証セットの割合」に「0.33」と入力します。
注: JMP Proでは、分析対象のデータテーブルにて検証セットを示す列がある場合、その列を指定することもできます。JMP Proにて検証セットを示す列を指定するには、この例では、「検証」列を選択し、[検証]ボタンをクリックしてください。その場合、「検証セットの割合」は「0」に設定してください。
6. [OK]をクリックします。
7. プラットフォームのレポートウィンドウで[実行]をクリックし、自動分岐を実行します。
注: 学習セットと検証セットがランダムに決められるため、実際の結果は図4.2とは異なります。
図4.2 糖尿病の「パーティション」レポート
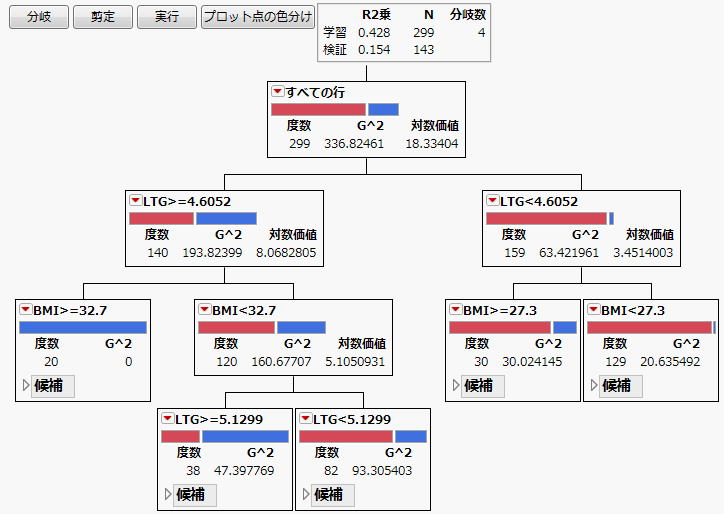
今回の実行では、分岐数が4となり、「検証」セットの最終的な「R2乗」は0.154となりました。このディシジョンツリーには、4つの分岐と、各分岐におけるオブザベーション数が示されています。
8. 「Y 2値のパーティション」の横にある赤い三角ボタンをクリックし、[列の寄与]をクリックします。
図4.3 「列の寄与」レポート
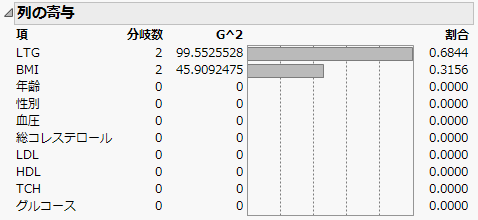
この「列の寄与」レポートには、ディシジョンツリーモデルの説明変数として「LTG」と「BMI」だけが示されています。これらの2つ列は、それぞれ2つの分岐に使用されています。なお、実際の分析結果は、ここでの結果と異なる可能性があります。なぜなら、「検証セットの割合」を使用すると、検証セットは分析対象のデータテーブルから無作為に選択されます。分析を実行するたびに、新しい検証セットが無作為に選択さるため、それぞれの結果は異なったものになります。
9. 「Y 2値のパーティション」の横にある赤い三角ボタンをクリックし、[列の保存]>[プロファイル]を選択します。
図4.4 パーティションモデルのプロファイル
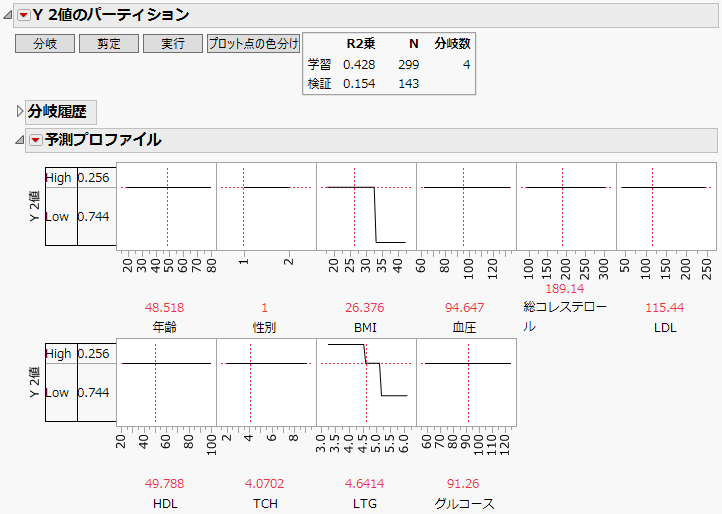
このプロファイルを使用すると、「BMI」および「LTG」の値を変更したときの、Y2値の予測値を知ることができます。他の説明変数は、今回のパーティションモデルでは分割がありませんでした。それらの説明変数に対しては、プロファイルは平坦な水平線になっています。
10. 「Y 2値のパーティション」の横にある赤い三角ボタンをクリックし、[列の保存]>[予測式の保存]を選択します。
「Diabetes.jmp」データテーブルに、「確率(Y 2値==Low)」、「確率(Y 2値==High)」、および「最尤 Y 2値」という列が追加されます。これらの応答確率の計算方法を確認するには、「列」パネルで各列の横にある計算式アイコン![]() をダブルクリックします。
をダブルクリックします。