“时间序列”平台的更多示例
该示例使用 SeriesP.jmp 样本数据表来显示如何执行时间序列分析。您首先创建一个适合“时间 ID”的新列。
创建合适的“时间 ID”列
1. 选择帮助 > 样本数据库,然后打开 Time Series/SeriesP.jmp。
SeriesP.jmp 数据表包含一个年份列和季度列来标识在观测响应期间的时间期间。但是,“时间序列”平台需要具有唯一、等间距的时间点的一列来标记 X 轴。若未指定“时间 ID”,则使用行号标识时间期间。为避免该问题和使报表更易于解释,您从年份和季度构造一个“时间 ID”列。
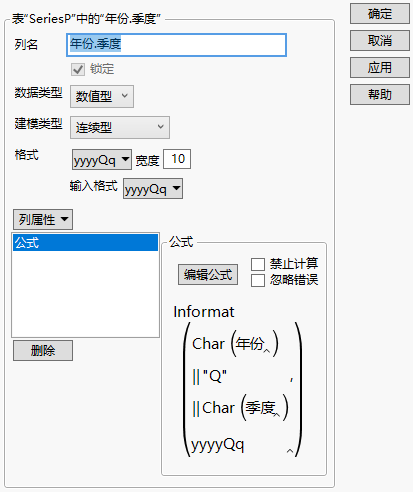
2. 选择列 > 新建列。在“列名”框中,键入年份.季度。
3. 选择“格式”旁边的最佳 > 日期 > yyyyQq。
4. 选择列属性 > 公式。
5. 点击“日期时间”旁边的灰色小三角并点击输入格式。
6. 点击“字符”旁边的灰色小三角。
7. 选择年份,点击字符,然后再点击 Concat。
8. 在框中键入“Q”(包含引号)并按 Enter 键。
9. 点击 Concat。
10. 选择季度,然后点击字符。
11. 点击 <格式名称> 框,键入 yyyyQq,然后按 Enter 键。
12. 点击确定。
完成的“新建列”对话框应如Figure 17.16中所示。
图 17.16 新建列
13. 点击确定。
注意:该时间列同样适用于 X11 分析。
时间序列分析
数据表包含合适的“时间 ID”列后,继续执行分析。
1. 选择分析 > 专业建模 > 时间序列。
2. 选择 GDP 并点击 Y,时间序列。
3. 选择年份.季度并点击 X,时间 ID。
4. 点击确定。
图 17.17 SeriesP.jmp 的“时间序列”报表
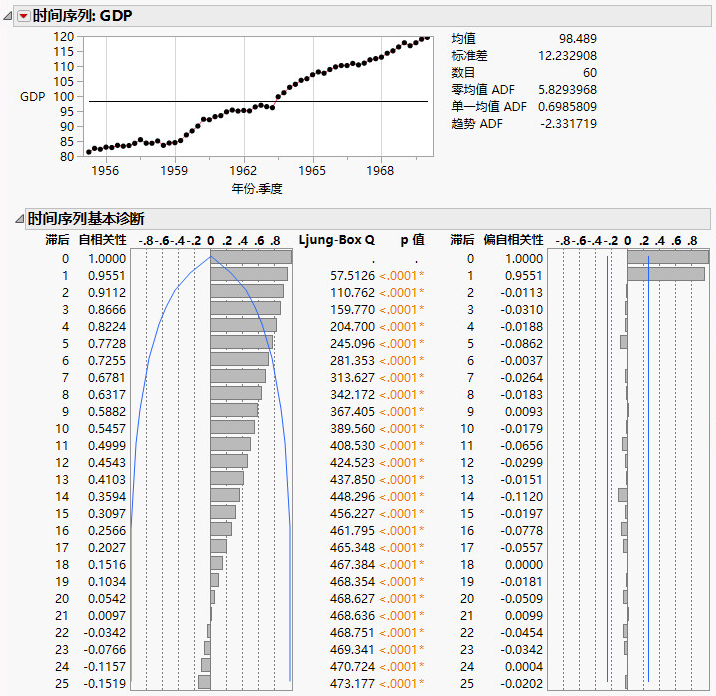
该序列显示一个随时间增长的趋势,它简直是线性的。此外,自相关性图显示在靠得很近的两点之间存在强相关。滞后期数为 1、2 和 3 的点的自相关性值分别为 0.9551、0.9112、0.8666。
5. 点击“时间序列: GDP”红色小三角菜单,然后选择差分。
6. 为“非季节性差分阶数”选择 1,然后点击估计。
图 17.18 SeriesP.jmp 的“差分”报表
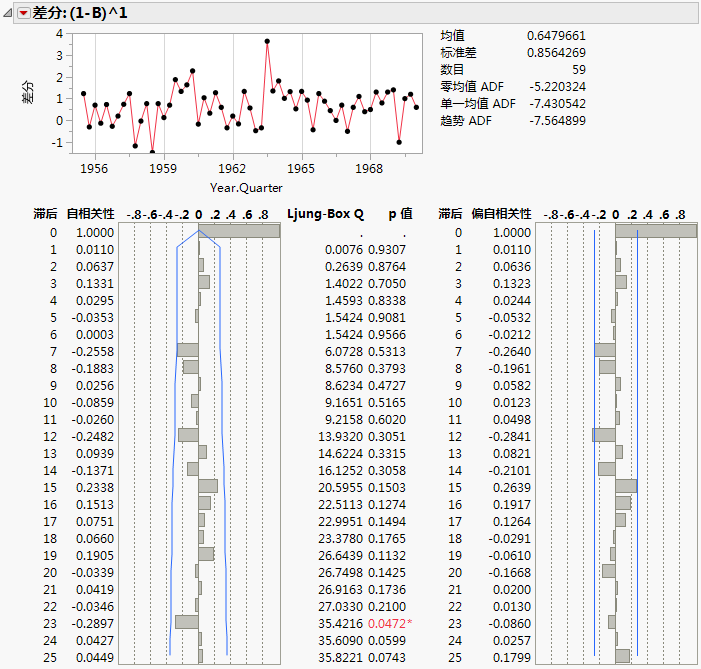
“差分”报表帮助确定要针对原始时间序列拟合的合适模型。差分图显示差分序列不再具有在原始数据中观测到的趋势。这指示“滞后-1”差分是合适的选择。此外,即使去除了该趋势,序列也未显示季节性特征。因此,拟合原始序列的模型应可以处理线性趋势,但是没有必要处理季节性。线性指数平滑和 ARIMA 模型都是合适的。
7. 点击“时间序列: GDP”红色小三角菜单,然后选择平滑模型 > 线性指数平滑。
8. 点击估计。
9. 点击“时间序列: GDP”红色小三角菜单,然后选择 ARIMA 模型组。这样您可以针对 (p,d,q)(P,D,Q) 的值范围拟合多个 ARIMA 模型。
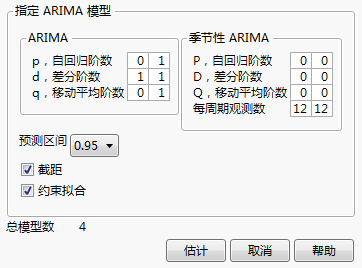
10. 在“ARIMA”框中,设置以下范围:
‒ 通过设置范围 0 到 1,将差分阶数 d 固定为 1,因为差分报表已显示“滞后-1”差分是合适的。
‒ 将自回归阶数 p 设置为 0 到 1 的范围,因为原始序列显示了自相关性的证据。
‒ 将移动平均阶数 q 设置为 0 到 1 的范围。
注意:在大多数情况下,保持 p 和 q 小就足够了。
‒ 让 P、D 和 Q 设置为 0,因为序列没有显示季节性的证据。
这些设置导致总共拟合 4 个模型。
图 17.19 指定 ARIMA 模型组
11. 点击估计。
图 17.20 “模型比较”表

根据 AIC 准则,“模型比较”表按以下方式排序:最佳拟合模型位于列表顶部。在本例中,ARIMA(0,1,0) 模型(在报表中表示为 I(1))拟合原始时间序列的效果最好。还应注意,尽管 I(1) 模型是“最佳的”,所有模型的拟合统计量值都非常相近。它们都可以被视为合适的模型。
图 17.21 ARIMA(0,1,0) 的模型报表
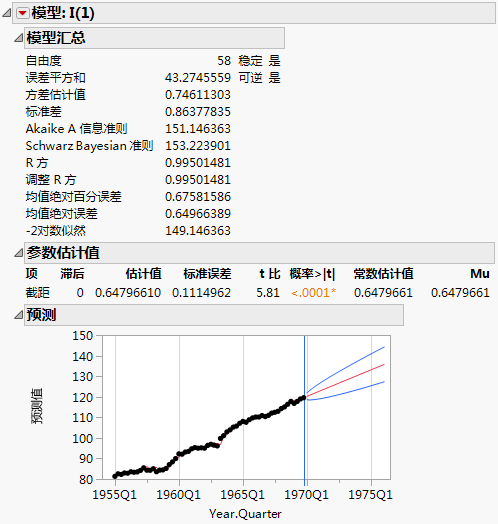
I(1) 的模型报表显示预测图。蓝线指示预测区间。预测 GDP 将以线性速度继续增长。