 包含分类响应的 Bootstrap 森林法的示例
包含分类响应的 Bootstrap 森林法的示例
在本例中,您通过构造 Bootstrap 森林法模型来预测客户是否具有不良信用风险。但您清楚您的数据集包含缺失值,所以您还要探索值缺失的程度。
 Bootstrap 森林法模型
Bootstrap 森林法模型
1. 选择帮助 > 样本数据库,然后打开 Equity.jmp。
2. 选择分析 > 预测建模 > Bootstrap 森林法。
3. 选择不良并点击 Y,响应。
4. 从贷款一直选到负债收入比,然后点击 X,因子。
5. 选择验证并点击验证。
6. 点击确定。
7. 在“每树最大拆分数”旁边,输入 30。
8. 选择在数个项数下进行多个拟合并在“最大项数”旁边输入 5。
9. (可选)选择禁止多线程并在“随机种子”旁边输入 123。
由于 Bootstrap 森林法涉及随机样本,这些操作可确保您获取如下所示的精确结果。
10. 点击确定。
图 5.2 “总体统计量”报表
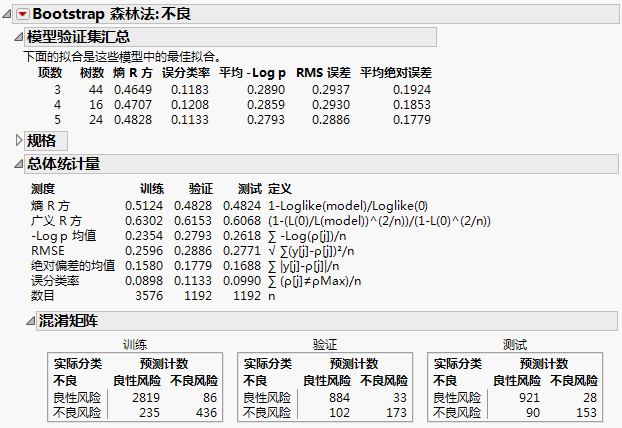
由于指定了“在数个项数下进行多个拟合”选项,则在每个拆分中将 3、4 和 5 用作预测变量数来创建模型。“模型验证集汇总”报表显示验证集有最高的“熵 R 方”的模型是五项模型。这也是误分类率最小的模型。确定该模型为最佳模型,总体报表中的结果是针对该模型的结果。
总体报表显示验证集和测试集的误分类率分别约为 11.3% 和 9.9%。混淆矩阵表明最大的误分类来源是将不良风险客户分类为良性风险客户。
测试集的结果提示您模型扩展到独立观测的能力有多强。验证集用于选择“Bootstrap 森林法”模型。出于该原因,验证集的结果会有一定偏差地指出模型如何推广到独立数据。
您关注的是确定哪些预测变量对模型的贡献最多。
11. 点击“Bootstrap 森林法: 不良”旁边的红色小三角,然后选择列贡献。
图 5.3 “列贡献”报表
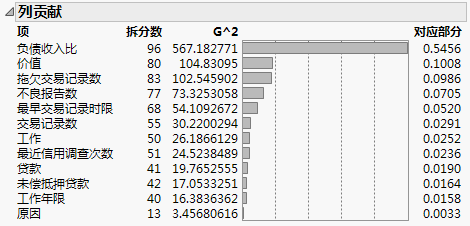
“列贡献”报表表明客户信用风险的最强预测变量为负债收入比,即负债与收入的比率。对模型贡献第二高的变量包括拖欠交易记录数(拖欠债务的贷方行)和价值(客户的评估值)。
 缺失值
缺失值
接下来,您要探索预测变量值缺失的程度。
1. 选择分析 > 筛选 > 探索缺失值。
2. 从不良一直选到负债收入比,然后点击 Y,列。
3. 在出现的“警示”中点击确定。
由于列原因和工作的数据类型为“字符”,所以不会将其添加到“Y,列”列表。您可以使用“分布”(本示例未显示)查看这两列有多少缺失值。
4. 点击确定。
图 5.4 “缺失值”报表
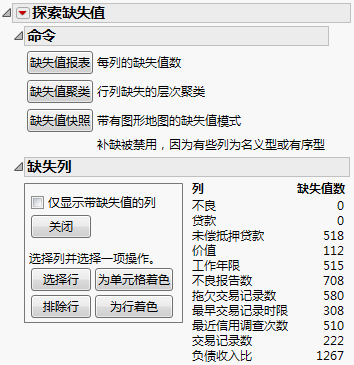
负债收入比列包含 1267 个缺失值,达到观测数的 21%。“Bootstrap 森林法”分析中涉及的大多数其他列也包含缺失值。启动窗口中的“信息性缺失”选项确保在处理缺失值时认可它们所传达的任何信息。请参见信息性缺失。