提升曲线
“提升曲线”选项提供另一个图来显示分割模型的预测能力。提升曲线标绘针对观测部分的提升。每个非重复预测概率值都对应一个点。响应水平的每个预测概率都定义预测概率大于或等于非重复预测概率值的观测部分。对于特定的响应水平,提升值是该部分中观测响应的比例与观测响应的总体比例之比。
注意:对于较小的模型,可能有大部分点都具有相同的预测概率值。若该概率是响应水平的最高预测概率,则提升曲线不会从“对应部分 = 0”开始。例如,Figure 4.18 的“Low”提升曲线中对此进行了演示。
图 4.18 提升曲线
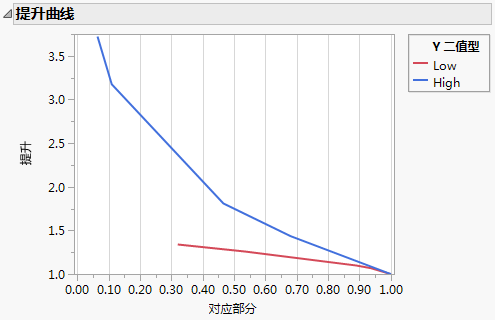
图 4.19 提升曲线的提升表

Figure 4.19 提供一个值表来演示如何计算用于Figure 4.18中所示的“High”提升曲线的“提升”和“对应部分”。构建了具有五个拆分的一个分割模型来预测响应 Y 二值型。Y 二值型具有两个水平:“Low”和“High”。提升曲线基于 309 个观测。有 83 个观测到的“High”响应,总体比率为 0.27。
• 概率“High”:分割模型用于“High”响应水平的五个非重复预测概率值。
• 数目 > 概率“High”:预测概率值等于或大于概率“High”中值的观测数。
• 对应部分:数目 > 概率“High”除以 309(观测总数)。
• 对应部分中的“High”数目:每个对应部分中具有观测到的“High”响应的观测数。
• “High”对应部分:对应部分中“High”的数目除以数目 > 概率“High”。
• 提升:“High”对应部分除以 0.27(观测到的“High”响应的总比率)。
提升量测量与每个部分的期望“High”响应数相比,有多少“High”响应落入该部分。对于数据集的前 6%,提升量为 3.72。使用该模型选择具有最高预测值的 6% 的观测所得的“High”响应比随机选择这 6% 所得的“High”响应多 3.72。