缺失值报表
图 20.13 Arrhythmia.jmp 中连续变量的缺失值报表
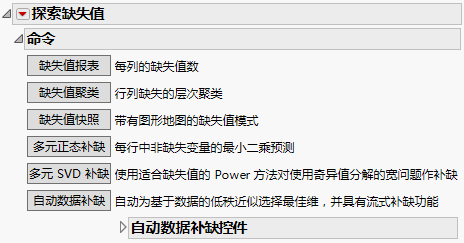
在启动窗口中点击“确定”后,该报表随即打开以显示“命令”分级显示项和一个“缺失列”报表。命令如下:
• “缺失值”报表
• 缺失值聚类
• 缺失值快照
• 多元正态插补(若在启动窗口中输入了建模类型为“名义型”或“有序型”的“数值”列则不可用。)
• 多元 SVD 插补(若在启动窗口中输入了建模类型为“名义型”或“有序型”的“数值”列则不可用。)
•  自动数据插补(若在启动窗口中输入了建模类型为“名义型”或“有序型”的“数值”列则不可用。)
自动数据插补(若在启动窗口中输入了建模类型为“名义型”或“有序型”的“数值”列则不可用。)
提示:要对依据变量的所有水平运行缺失值命令,请按住 Ctrl 键并点击所需的命令按钮。
“缺失值”报表
使用“缺失值报表”可打开“缺失列”报表,其中列出每列的名称和该列中缺失值的个数。
仅显示带缺失值的列
从列表中删除不含缺失值的列。
关闭
关闭“缺失列”报表。
选择行
选择数据表中的特定行,这些行包含您在“缺失列”报表中选择的一个或多个列的缺失值。
排除行
针对数据表中的特定行应用排除行状态,这些行包含您在“缺失列”报表中选择的列的缺失值。
为单元格着色
为数据表中的特定单元格着色,这些单元格包含您在“缺失列”报表中选择的列的缺失值。
为行着色
为数据表中的特定行着色,这些行包含您在“缺失列”报表中选择的一个或多个列的缺失值。
缺失值聚类
“缺失值聚类”提供对缺失数据的层次聚类分析。
• 图右侧的树状图显示缺失数据模式行的聚类。这些是您通过使用“表”>“缺失数据模式”得到的行。
• 图下方的树状图显示变量聚类。
使用该报表可确定特定列组是否倾向于具有相似的缺失值模式。
图的各行通过缺失数据模式来定义;每个模式对应一行。列对应变量。每个红色方格都指示图下方所列的列的一组缺失值。将光标置于方格中可查看所代表的值的列表。在图中点击可选择缺失数据模式行。显示垂直直条以指示选定的模式。
缺失值快照
缺失值快照显示缺失值的方格图。列表示变量。黑色方格指示缺失值。该图对于理解纵向数据的缺失尤其有用;缺失纵向数据时,对象可能在数据收集期结束之前退出研究。
多元正态插补
“多元正态插补”实用工具基于多元正态分布插补缺失值。该过程要求所有变量的建模类型都为“连续”。该算法使用最小二乘插补。使用配对协方差构造协方差矩阵。使用每个变量的所有非缺失值计算对角线元素(方差)。使用任意两个变量均无缺失的所有观测计算这两个变量的非对角线元素。对于协方差矩阵奇异的情况,算法使用基于 Moore-Penrose 伪逆矩阵的最小范数最小二乘插补。
多元正态插补允许选择对协方差使用收缩估计量。使用收缩估计量是改善协方差矩阵的估计的一种方法。有关收缩估计量的详细信息,请参见 Schafer and Strimmer (2005)。
注意:若指定了验证列,则使用来自训练集的观测计算协方差矩阵。
“多元正态插补”报表
插补报表解释多元插补过程的结果。结果包括以下内容:
• 插补方法(最小二乘或最小范数最小二乘)
• 替换了多少值
• 是否使用收缩估计量
• 非对角线元素按哪个因子统一尺度
• 有多少行列受到影响
• 有多少不同的缺失值模式
一旦完成插补,与数据表中的插补值对应的方格就会变为浅蓝色。若“缺失列”报表处于打开状态,则该报表将更新以显示没有缺失值。
点击撤销可撤销插补,用缺失值替换插补的数据。
多元 SVD 插补
“多元 SVD 插补”实用工具使用奇异值分解 (SVD) 插补缺失值。该实用工具适用于有数以百计或数以千计变量的数据。由于 SVD 计算不要求计算协方差矩阵,所以推荐对包含大量变量的广泛问题使用 SVD 方法。该过程要求所有变量的建模类型都为“连续”。
奇异值分解将观测矩阵 X 表示为 X = UDV′,其中,U 和 V 是正交矩阵,D 是对角矩阵。
“多元 SVD 插补”实用工具中默认使用的 SVD 算法是稀疏 Lanczos 方法,亦称隐式重新启动的 Lanczos 双对角化方法 (IRLBA)。请参见 Baglama and Reichel (2005)。该算法执行以下计算:
1. 每个缺失值都用其列均值替代。
2. 针对观测矩阵 X 执行 SVD 分解。
3. 包含缺失值的每个单元格都替换为从 SVD 分解获得的 UDV′ 矩阵的相应元素。
4. 重复执行步骤 2 和 3,直到 SVD 收敛到矩阵 X。
“插补方法”窗口
点击“多元 SVD 插补”后,“插补方法”窗口即显示推荐的设置。
奇异向量数
在插补中计算和使用的奇异向量数。
注意:一定注意:不要指定过多的奇异向量,否则 SVD 和插补不会在各次迭代之间改变。
最多迭代次数
插补缺失值时使用的迭代次数。
显示迭代日志
打开一个“详细信息”报表,其中显示迭代次数并提供关于准则的详细信息。
对于较大的问题,进度条会显示 SVD 完成了多少个维。您可以停止插补并随时使用该维数。
“多元 SVD 插补”报表
插补报表解释多元插补过程的结果。
• 插补方法
• 替换了多少值
• 有多少行列受到影响
一旦完成插补,即自动显示“缺失列”报表,该报表指示插补的列中没有缺失值。插补值显示为浅蓝色。
点击撤销可撤销插补,用缺失值替换插补的数据。
 自动数据插补
自动数据插补
“自动数据插补”(ADI) 实用工具使用低秩矩阵近似方法(亦称矩阵完成)插补缺失值。经过训练后,ADI 模型能够对得分公式中的流数据执行缺失数据插补。流数据是随时变得可用而添加的观测行,并不用于优化或验证插补的模型。该实用工具灵活稳健,可以为低秩近似自动选择最佳维。这些功能使得 ADI 能够很好地适用于许多不同类型的数据集。该过程要求所有变量的建模类型都为“连续”。
矩阵的低秩近似采用 X = UDV′ 的形式,可视为奇异值分解 (SVD) 的扩展。ADI 将 Soft-Impute 方法用作插补模型,而且经过专门设计,使得数据能够确定低秩近似的秩。
ADI 算法执行以下步骤:
1. 数据划分到各个训练集和验证集中。
2. 每个集都使用训练集中的观测值进行中心化和统一尺度。
3. 对于每个划分的数据集,在每列中添加其他缺失值,这些值被称为引入的缺失 (IM) 值。
4. 针对训练数据集沿着调节参数的解路径拟合插补模型。IM 值用于确定调节参数的最佳值。
5. 使用训练数据集通过消除step 4中所选插补模型的结果的偏倚来执行其他秩缩减。
6. 执行最终秩缩减以校准流数据模型,以防过度拟合。这需要将step 5中确定的秩用作上限,针对验证集拟合插补模型。
自动数据插补控件
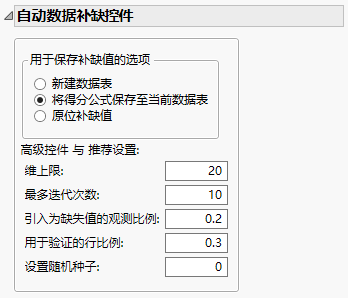
ADI 实用工具包含用于保存插补值的选项和高级控件。
图 20.14 ADI 控件
用于保存插补值的选项
提供以下用于保存 ADI 方法的插补值的三个选项:
新建数据表
创建与原始数据表具有相同维的新数据表。在新数据表中,启动窗口中的选定列包含插补值。
将得分公式保存至当前数据表
将名为 Imputed_ 的列组保存至包含在启动窗口中指定的插补列的当前数据表。隐藏列 ADI 插补列也会添加至包含数据插补中使用的插补向量和得分公式的当前数据表。若向数据表添加任何其他行,列公式会自动更新,从而支持对流数据进行缺失数据插补。这是默认选项。
原位插补值
在当前数据表中插补缺失值。插补值显示为浅蓝色。
高级控件
包含以下高级控件,默认使用基于数据的推荐设置:
维上限
确定低秩近似中允许的最大秩。由所选列构成的矩阵的维确定。
最多迭代次数
确定要迭代的值的个数,以确定插补模型的调节参数。默认值为 10。
引入为缺失值的观测比例
确定添加到训练集和验证集的 IM 值的比例。每个集的默认比例为 0.2。
用于验证的行比例
确定在训练集和验证集中使用的行的比例。验证集的默认比例为 0.3。
设置随机种子
确定 ADI 的随机种子。使用该选项获取可重现的结果。