估计方法
REML
当数据包含缺失值时,与 ML(最大似然)估计方法相比,REML(限制最大似然)估计值的偏倚更小。REML 方法基于误差对比将边缘似然最大化。REML 方法经常用于估计方差和协方差。“主成分”平台中的 REML 方法与针对重复测量数据(具有非结构化协方差矩阵)使用的混合模型的 REML 估计相同。请参见 SAS PROC MIXED 文档,了解有关混合模型的 REML 估计。
宽
“宽”方法使用可避免计算协方差矩阵的高效计算算法。该算法基于奇异值分解。考虑以下符号:
• n = 行数
• p = 变量数
• X = 数据值的 n x p 矩阵
非零特征值数以及得到的主成分数均等于 X 的相关性矩阵的秩。非零特征值数不得超过 n 和 p 中较小的那个值。
若选择“宽”方法,数据将被标准化。要将某个值标准化,需减去其均值,再除以其标准差。用 Xs 来表示标准化数据值的 n x p 矩阵。之后,标准化数据的协方差矩阵成为 X 的相关性矩阵,它的计算公式如下:
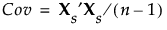
使用奇异值分解,Xs 可表示为 UDiag(Λ)V′。这种表示法用于获取 Xs′Xs 的特征向量和特征值。主成分或得分通过 XsV 计算得出。更多背景信息,请参见“宽线性”方法和奇异值分解。
 稀疏
稀疏
与“宽”方法类似,“稀疏”方法基于奇异值分解。因此,“稀疏”方法的算法避免计算协方差矩阵,计算效率较高。
考虑对宽中所述的 X 使用相同的符号和标准化。X 的相关性矩阵由 Xs 的协方差矩阵表示:
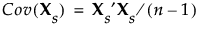
“稀疏”方法与“宽”方法的不同之处在于奇异值分解的计算方式。“宽”方法执行完整奇异值分解,而“稀疏”方法使用的算法在奇异值分解时仅计算第一个指定数量的奇异值和奇异值向量。因此,只返回第一个指定数量的特征值和主成分。有关算法的详细信息,请参见 Baglama and Reichel (2005)。