启动“偏最小二乘”平台
有两种启动“偏最小二乘”平台的方法:
• 选择分析 > 多元方法 > 偏最小二乘。
•  选择分析 > 拟合模型,然后从“特质”菜单中选择偏最小二乘。该方法允许您执行以下操作:
选择分析 > 拟合模型,然后从“特质”菜单中选择偏最小二乘。该方法允许您执行以下操作:
‒ 输入分类变量作为 Y 或 X。通过输入分类 Y 来执行 PLS-DA。
‒ 将交互作用项和多项式项添加到您的模型。
‒ 使用“标准化 X”选项以使用中心化和统一尺度的列构造高阶项。
‒ 保存您的模型规格脚本。
“拟合模型”启动窗口上的一些功能不适用于“偏最小二乘”特质:
• “权重”、“嵌套”、“特性”、“变换”和“无截距”。
提示:您可以通过在“选择列”框中右击某个变量并选择一个“变换”选项来变换该变量。
• 下面的宏:混料响应曲面和 Scheffé 三次项。
JMP Pro“偏最小二乘”启动窗口(选择了 EM 作为补缺方法 )
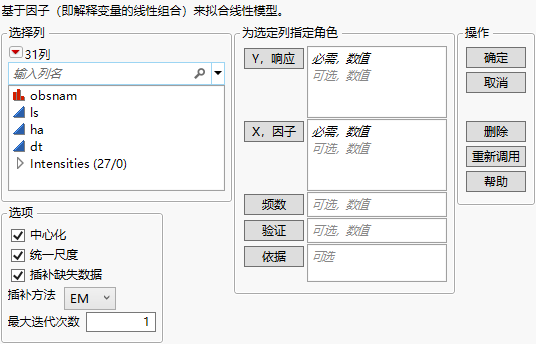
有关“选择列”红色小三角菜单中选项的详细信息,请参见《使用 JMP》中的“列过滤器”菜单。
“偏最小二乘”启动窗口包含以下选项:
Y,响应
输入数值响应列。若您输入了多个列,则它们联合建模。
 在 JMP Pro 中,您可以在“拟合模型”启动窗口中输入名义型响应列来执行 PLS-DA。请参见PLS 判别分析 (PLS-DA)。
在 JMP Pro 中,您可以在“拟合模型”启动窗口中输入名义型响应列来执行 PLS-DA。请参见PLS 判别分析 (PLS-DA)。
X,因子
输入预测变量列。“偏最小二乘”启动窗口只允许数值型预测变量。
 在 JMP Pro 中,您可以在“拟合模型”启动窗口中输入名义型和有序型模型效应。有序型效应被视为名义型处理。
在 JMP Pro 中,您可以在“拟合模型”启动窗口中输入名义型和有序型模型效应。有序型效应被视为名义型处理。
频数
若您的数据进行了汇总,则输入其值包含各行计数的列。
 验证
验证
输入可选的验证列。验证列只能包含连续的整数值。请注意以下事项:
‒ 若验证列有两个水平,则较小的值定义训练集,较大的值定义验证集。
‒ 若验证列有三个水平,则这些值按大小递增的顺序定义训练集、验证集和测试集。
‒ 若验证列有三个以上的水平,则使用“K 重交叉验证”。有关其他验证选项的信息,请参见验证方法。
注意:若在“选择列”列表中没有选择任何列的情况下点击“验证”按钮,则可以在数据表中添加一个验证列。有关“生成验证列”实用工具的详细信息,请参见《基本分析》。
依据
输入一列,用于创建为变量的每个水平包含单独分析的报表。若分配了多个“依据”变量,则为“依据”变量水平的每个可能组合生成单独分析。
中心化
通过从每个列减去均值将所有 Y 变量和模型效应中心化。请参见中心化和统一尺度。
统一尺度
通过将每个列除以其标准差对所有 Y 变量和模型效应统一尺度。请参见中心化和统一尺度。
 标准化 X
标准化 X
(仅可用于“拟合模型”启动窗口。)将构造模型效应时使用的所有列中心化和统一尺度。若未选择该选项,则使用原始数据表列构造高阶效应。然后基于所选的“中心化”和“统一尺度”选项将每个高阶效应中心化或统一尺度。请注意,“标准化 X”选项不将 Y 变量中心化或统一尺度。请参见标准化 X。
 补缺缺失数据
补缺缺失数据
使用非缺失值替代 Y 或 X 中的缺失数据值。从补缺方法列表中选择合适的方法。
若未选择补缺缺失数据,则从分析中排除在任何 X 变量上具有缺失观测的行,而且不为这些行计算预测值。此外还会从分析中排除在 X 变量上不具有缺失观测但是在 Y 变量上具有缺失观测的行,但是计算预测值。
 补缺方法
补缺方法
(仅在补缺缺失数据时显示。)从以下补缺方法中选择:
均值
对于每个模型效应或响应列,使用非缺失值的均值替代缺失值。
EM
使用迭代期望值最大化 (EM) 方法来补缺缺失值。在第一次迭代时,使用均值替代效应或响应的缺失值,对数据拟合指定的模型。使用 Y 模型的预测值和 X 模型的预测值来补缺缺失值。对于后续迭代,在使用当前估计值给出条件分布时,使用其预测值替代缺失值。
为了进行补缺,多项式中的项被视为单独的预测变量处理。当指定了多项式中的项时,将根据原始数据计算该项;若选中了“标准化 X”,则根据标准化的列值计算该项。若某一行在定义多项式中的项所涉及的列中存在缺失值,则该条目对于多项式中的项是缺失的。使用这样定义的多项式中的项执行补缺。
有关 EM 方法的详细信息,请参见 Nelson, Taylor and MacGregor (1996)。
 最大迭代次数
最大迭代次数
(仅在将 EM 选作补缺方法时才显示。)支持您设置算法使用的最大迭代次数。若缺失值的当前估计值和前一估计值之间的最大差值不超过 10-8,算法将终止。
在完成启动窗口并点击确定后,将显示“模型启动”控制面板。请参见“模型启动”控制面板。