混合模型和随机效应模型
随机效应模型是所有因子都表示随机效应的模型。(请参见随机效应。)此类模型亦称方差分量模型。随机效应模型往往是分层模型。同时包含固定和随机效应的模型称为混合模型。重复测量和裂区模型是混合模型的特例。通常使用混合模型一词来包含随机效应模型。
要拟合混合模型,您必须在“拟合模型”启动窗口中指定随机效应。不过,若所有模型效应都是随机的,您还可以在“变异性 / 计数量具图”平台中拟合模型。只能在该平台中拟合特定模型。请注意,在“变异性 / 计数量具图”平台中使用的拟合方法不允许方差分量估计值为负。有关“变异性/计数量具图”平台如何拟合方差分量模型的详细信息,请参见《质量和过程方法》中的变异性量具图和计数量具图。
随机效应
随机效应是其水平被视为某个总体中的随机样本的因子。通常,随机效应的精确水平并不受关注,而水平反映出的变异才受关注(方差分量)。不过,也有些时候您想要预测随机效应给定水平的响应。更严格地来讲,随机效应被视为服从均值为零且方差非零的正态分布。
假定您关注的是两种特定的烤炉对模具收缩的影响是否不同。一个烤炉一次仅处理一批 50 个模具。您设计这样一个研究方案:先后分别为每一个烤炉随机选三个批次(每批 50 个模具)放进烤炉。这些批次的模具处理完毕后,对每批中随机选择的五个部件测量收缩。
请注意,“批次”是包含六个水平的因子,每批次对应一个水平。所以,在您的模型中包括两个因子 —“烤炉”和“批次”。由于您特别关注比较每个烤炉对于收缩的影响,所以“烤炉”是一个固定效应。但您并不关注这六个特定批次对于收缩均值的影响。这些批次代表了一个都有可能被这个实验选上的批次总体,而且其分析结果必须推广到的整个批次总体。“批次”被视为随机效应。在该实验中,“批次”因子因为在所有可能批次中的收缩变异而受到关注。您想要估计它所解释的收缩变异量。(请注意,“批次”还嵌套在“烤炉”中,因为在一个烤炉中一次只能处理一个批次。)
现在假定您关注的是在两种不同喂养制度下喂养出来的母鸡的蛋重。为十只母鸡随机分配喂养制度:为五只分配了喂养制度 A,另五只分配了喂养制度 B。不过,在本研究方案的设计中并未考虑这十只母鸡存在的一些基因上的差异。在这种情况下,您关注的是某些特定母鸡的预测蛋重以及母鸡蛋重的方差。
经典线性混合模型
JMP 拟合经典线性混合效应模型:
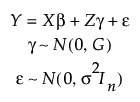
在此,
• Y 是响应的 n x 1 向量
• X 是固定效应的 n x p 设计矩阵
• β 是设计矩阵 X 的未知固定效应的 p x 1 向量
• Z 是随机效应的 n x s 设计矩阵
• γ 是设计矩阵 Z 的未知随机效应的 s x 1 向量
• ε 是未知随机误差的 n x 1 向量
• G 是 s x s 对角矩阵(针对随机效应的每个水平包含相同的条目)
• In 是 n x n 单位矩阵
• γ 和 ε 不相关
G 的对角线元素以及 σ2 称为方差分量。这些方差分量以及固定效应的向量 β 和随机效应的向量 γ 都是必须要估计的模型参数。
该模型的协方差结构有时称为方差分量结构 (SAS Institute Inc. 2018d, ch.81)。这种协方差结构仅在“标准最小二乘法”特质中提供。
 “混合模型”特质拟合众多协方差结构,包括残差、一阶自回归(或 AR(1))、非结构化和空间。请参见“重复结构”选项卡。
“混合模型”特质拟合众多协方差结构,包括残差、一阶自回归(或 AR(1))、非结构化和空间。请参见“重复结构”选项卡。
用于拟合包含随机效应的模型的 REML 与 EMS
JMP 提供了两种方法来拟合包含随机效应的模型:
• REML 表示限制最大似然(始终为推荐方法)
• EMS 表示期望均方(仅适用于旧版教科书的教学)
REML 方法现已取代传统 EMS 方法成为主流的拟合方法。与 EMS 方法相比,REML 在适用性方面要广泛得多。REML 方法最早是由 Patterson and Thompson (1974) 提出的。另见 Wolfinger et al. (1994) 和 Searle et al. (1992)。
EMS 方法,亦称矩量法,是在功能强大的计算机面世之前开发出来的。研究人员将自己限定在平衡环境中,并使用 EMS 方法(提供了计算快捷方式)来计算随机效应的估计值和混合模型。由于当今仍在使用的许多教科书仍使用 EMS 方法来介绍包含随机效应的模型,所以 JMP 提供了 EMS 选项。(请参见,例如 McCulloch et al., 2008; Poduri, 1997; Searle et al., 1992。)
REML 方法执行限制似然函数的最大似然估计,它不依赖于固定效应参数。这将生成方差分量的估计值,该估计值随后用于获取固定效应的估计值。精确估计值基于参数的协方差矩阵的估计值。即便数据不平衡,REML 也可提供有用的估计值、检验和置信区间。
EMS 方法通过使观测均方与期望均方相等对方差分量的估计值求解。对于平衡设计,通过一组复杂的规则指定如何获取估计值。对不平衡数据应用该方法存在问题。
对于平衡数据,REML 估计值与 EMS 估计值相同。但是,与 EMS 不同的是,REML 善于处理不平衡数据。
指定随机效应和拟合方法
在“拟合模型”启动窗口中指定包含随机效应的模型。要指定随机效应,在“构造模型效应”列表中将其突出显示,然后选择特性 > 随机效应。这将向模型效应列表中的效应名称后附加上“&随机”。(有关随机效应的定义,请参见随机效应。)还可以在单独的效应选项卡中指定随机效应。(请参见“构造模型效应”选项卡。)
在“拟合模型”启动窗口中,一旦向效应添加了“&随机”特性,您就可以在 REML(推荐)或 EMS(传统)这两种拟合方法中任选其一。
警告:您必须显式声明交叉和嵌套关系。例如,当每个对象仅位于一个组内时,对象 ID 也可能标识包含该对象的组。在这种情形下,对象 ID 必须仍声明为嵌套在组内。务必要小心谨慎地明确定义设计结构。
不受限的方差分量参数化
将方差分量参数化可使用两种不同的方法:不受限方法和受限方法。当模型中存在混合效应时(比如固定效应与随机效应的交互作用),就会出现问题。这种交互作用项被视为随机效应。
在受限方法中,对于随机效应的每个水平,在固定效应各个水平上的交互作用效应的总和假设为 0。在不受限方法中,只是简单地将混合项假设为具有均值 0 和公共方差的正态分布的独立随机实现。(该假设类似于通常应用于剩余误差的假设。)
JMP 和 SAS 使用不受限方法。该区别很重要,因为很多统计学教科书都使用受限方法。这两种方法都已广泛教授有 60 年之久。有关这两种方法的讨论,请参见 Cobb(1998,第 13.3 节)。
负方差
尽管方差始终为正,但在某些情况下方差的无偏估计值也可能为负。以下实验情况可能出现负估计值:某个效应非常微弱,或是只有极少的水平与方差分量对应。因此,观测数据有可能导致估计值为负。
无界限方差分量
JMP 可以为 REML 和 EMS 生成负估计值。对于 REML,“拟合模型”启动窗口中有两个选项:“无界限方差分量”和“仅估计方差分量”。默认选定“无界限方差分量”选项。取消选择该选项将限制方差分量估计值为非负。
若您关注的是固定效应,则应保持选定“无界限方差分量”选项。将方差估计值限制为非负将导致固定效应检验发生偏倚。
仅估计方差分量
若您只想查看“REML 方差分量估计值”报表,则选择该选项。若您仅关注方差分量,则可能想限制方差分量为非负。适当的操作可能是取消选择“无界限方差分量”选项,然后选择“仅估计方差分量”选项。