限制最大似然 (REML) 方法
基于所选的拟合方法,“拟合最小二乘法”报表提供不同的分析结果并提供“保存列”和“刻画器”的更多菜单选项。尤其需要指出,“方差分析”报表并不显示,因为方差和自由度未按照通常方式分割。您可以从“REML 方差分量估计值”报表获取残差方差估计值。(请参见REML 方差分量估计值。)对于检验固定效应的情况,“效应检验”报表被“固定效应检验”报表取代。其他报表提供随机效应的预测值以及关于方差分量的详细信息。
REML 方法的“拟合最小二乘法”报表 显示了使用 REML 方法拟合 Investment Castings.jmp 样本数据所获取的报表。运行脚本模型 - REML,然后拟合该模型。请注意,铸件是嵌套在温度内的随机效应。
REML 方法的“拟合最小二乘法”报表
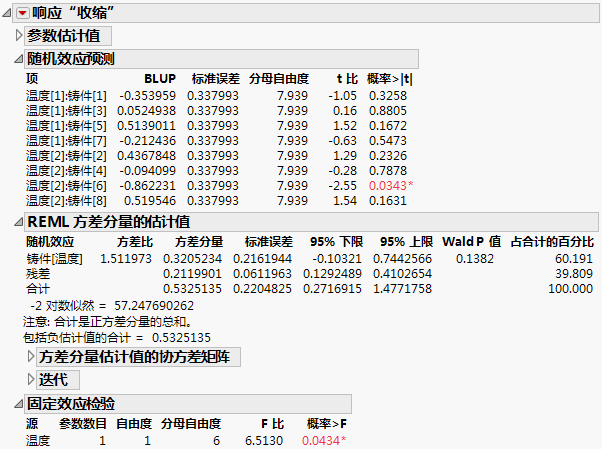
随机效应预测
对于模型中的每个项,该报表提供其最佳线性无偏预测变量 (BLUP) 的经验估计值,以及针对相应系数是否为 0 的检验。
注意:必须选定“回归报表”>“参数估计值”选项,才能显示“随机效应预测”报表。
项
模型中与随机效应对应的项。
BLUP
每个随机效应的最佳线性无偏预测变量 (BLUP) 的经验估计值。请参见最佳线性无偏预测变量。
标准误差
BLUP 的标准误差。
分母自由度
针对效应为 0 的检验的分母自由度。多数情况下,t 检验的自由度是小数。
t 比
用于检验效应为 0 的 t 比。通过将 BLUP 除以其标准误差可以得出 t 比。
概率>|t|
检验的 p 值。
95% 下限
BLUP 的 95% 置信下限。仅当已选定“回归报表”>“显示所有置信区间”选项或是在报表中右击并选择“列”>“95% 下限”时,该列才显示。
95% 上限
BLUP 的 95% 置信上限。仅当已选定“回归报表”>“显示所有置信区间”选项或是在报表中右击并选择“列”>“95% 上限”时,该列才显示。
最佳线性无偏预测变量
最佳线性无偏预测变量 (BLUP) 一词指的是随机效应的估计量。具体而言,它是所有无偏估计量中可最小化均方预测误差的估计量。“随机效应预测”报表提供 BLUP 的估计值或经验 BLUP。这些之所以是经验值是因为 BLUP 依赖方差分量的值,而这些值是未知的。方差分量的估计值被代入 BLUP 的公式中,生成了报表中所示的估计值。
REML 方差分量估计值
在“拟合模型”启动窗口中将 REML 选作拟合方法后,会提供“REML 方差分量估计值”报表。该报表包含以下列:
随机效应
模型中的随机效应。
方差比
效应的方差分量与残差的方差分量之比。它比较的是效应的估计方差与模型的估计误差方差。
方差分量
效应的估计方差分量。请注意,“合计”的方差分量只是正方差分量之和。所有方差分量的总和在表的下方提供。
标准误差
方差分量估计值的标准误差。
95% 下限
方差分量的 95% 置信下限。请参见方差分量的置信区间。
95% 上限
方差分量的 95% 置信上限。请参见方差分量的置信区间。
Wald P 值
用于检验协方差参数是否等于零的 p 值。仅当您在“拟合模型”启动窗口中选定了“无界限方差分量”时,该列才显示。
占合计的百分比
效应的方差分量与合计的方差分量之比(用百分比表示)。
方差分量平方根
相应方差分量的平方根。它是效应的标准差的估计值。仅当您在报表中右击并选择“列”>“方差分量平方根”时才显示该列。
变异系数
方差分量的变异系数。它是将方差分量的平方根乘以 100 后再除以响应均值的结果。仅当您在报表中右击并选择“列”>“变异系数”时才显示该列。
范数 KHC
Kackar-Harville 校正。请参见Kackar-Harville 校正。仅当您在报表中右击并选择“列”>“范数 KHC”时才显示该列。
方差分量的置信区间
用于计算置信限的方法取决于您是否在“拟合模型”启动窗口中选定了“无界限方差分量”。请注意,默认情况下选定“无界限方差分量”选项。
• 若选定了“无界限方差分量”,则计算基于 Wald 的置信区间。这些区间渐近有效,但请注意样本较小时它们并不可靠。
• 若未选定“无界限方差分量”,这表示参数的下边界约束为 0,此时将使用 Satterthwaite 近似 (Satterthwaite 1946)。
Kackar-Harville 校正
在 REML 方法中,使用方差分量估计值来估计固定效应的标准误差。不过,若不考虑这些估计值中的变异性,则会低估标准误差。要考虑增大的变异性,可以使用 Kackar-Harville 校正(Kackar and Harville 1984;Kenward and Roger 1997)来调整固定效应的协方差矩阵。涉及固定效应的协方差矩阵的所有计算都使用该校正。这些计算包括最小二乘均值、固定效应检验、置信区间和预测方差。有关统计详细信息,请参见Kackar-Harville 校正。
“范数 KHC”是 Kackar-Harville 校正的 Frobenius(矩阵)范数。在设计颇为平衡的情况下,“范数 KHC”往往较小。
方差分量估计值的协方差矩阵
该报表提供方差分量的渐近协方差矩阵的估计值。它是观测的 Fisher 信息矩阵的逆矩阵。
迭代
通过将仅依赖于这些参数的残差对数似然函数最大化,可获得 σ2 的估计值和 G 中的方差分量。迭代过程尝试将残差对数似然函数最大化,或等效于将负残差对数似然的两倍(–2对数似然)最小化。“迭代”报表提供有关该过程的详细信息。
迭代
迭代次数。
-2对数似然
负对数似然的两倍。它是目标函数。
范数梯度
目标函数的梯度(一阶导数)范数。
参数
在标记为“参数”的列和其余列中,每一列都对应一个随机效应。列的顺序遵循随机效应在“REML 方差分量估计值”报表中所列的顺序。在每次迭代中,列中的值是该阶段方差分量的估计值。
收敛准则基于梯度,默认容差为 10-8。您可以在“拟合模型”启动窗口中更改该准则,只需选择“收敛设置”>“收敛极限”选项并指定所需容差即可。
固定效应检验
使用 REML 时,“效应检验”报表提供固定效应检验。该报表包含以下列:
源
模型中的固定效应。
参数数目
与效应关联的参数数目。
自由度
与效应关联的自由度。
分母自由度
分母自由度。这些基于使用 Kenward-Roger 校正调整协方差矩阵时获得的统计量的近似分布。请参见Kackar-Harville 校正和随机效应。
F 比
计算的 F 比。
概率 > F
效应检验的 p 值。
REML“保存列”选项
使用 REML 方法时,“保存列”菜单中将额外显示六个选项。这些选项的名称以条件一词开头。该前缀指示这些列的计算使用与随机效应关联的项的预测值,而不是其期望值 0。
条件预测公式
将预测公式保存至数据表中的新列。
条件预测值
将预测值保存至数据表中的新列。
条件残差
将残差保存至数据表中的新列。
条件均值置信区间
保存均值的置信区间。
条件单值置信区间
保存单值的置信区间。
 发布条件公式
发布条件公式
创建条件预测公式并将其另存为“公式存储库”平台中的公式列脚本。若未打开“公式存储库”报表,该选项将创建“公式存储库”报表。请参见《预测和专业建模》中的公式存储库。
REML“刻画器”选项
当您使用 REML 方法并选择“因子刻画”>“刻画器”时,新选项“条件预测”将显示在“预测刻画器”旁边的红色小三角菜单中。请注意,条件值使用随机效应的预测值,而不是其期望值 0。
注意:刻画器为因子水平的所有组合显示条件预测值和条件均值置信区间。某些组合可能因为嵌套而无意义。