超饱合筛选设计
一般来说,头脑风暴讨论后通常会发现几十个可能的活跃因子。与其精简列表而享受不到数据优势,不如使用超饱和设计。
在饱和设计中,试验次数等于模型项的个数。在超饱和设计中,模型项数超过了试验次数 (Lin, 1993)。超饱和设计可使用比因子数一半还少的试验次数来检查几十个因子。于是在因子数众多而试验成本高昂的情况下,超饱和设计便成了颇具吸引力的因子筛选选择。
或者,用组正交超饱和设计代替传统超饱和设计来更好地识别活跃效应。请参见组正交超饱和设计。
超饱和设计的局限性
超饱和设计有一些缺点:
• 若实验中的活跃因子个数超过了试验次数的一半,则这些因子可能无法识别。一般规则是:试验次数应至少是活跃因子个数的四倍之多。换言之:若您预计活跃因子可能多达五个,那么应计划执行至少 20 次试验。
• 超饱和设计分析目前尚无法简化为自动过程。不过,使用前向逐步回归较为合理。此外,“筛选”平台(实验设计 > 经典 > 两水平筛选 > 拟合两水平筛选)提供简化分析。
生成超饱和设计
在本例中,您想要通过构造超饱和设计在 8 次试验中研究 12 个因子。要创建超饱和设计,需要将所有模型项(截距除外)的“可估计性”设置为“若可能”。
注意:本例仅用于演示目的。在任意超饱和设计中都应至少进行 14 次试验。若活跃因子多达四个,则很难解释 8 次试验设计的结果。请参见超饱和设计的局限性。
1. 选择实验设计 > 定制设计。
2. 在添加因子数旁边键入 12。
3. 点击添加因子 > 连续。
4. 点击继续。
5. 在“模型”分级显示项中,选择除“截距”之外的所有项。
6. 点击任意效应旁边的必需,将其更改为若可能。
将效应设置为若可能可确保 JMP 使用 Bayes D 最优性准则获取设计。
因子、模型和试验次数
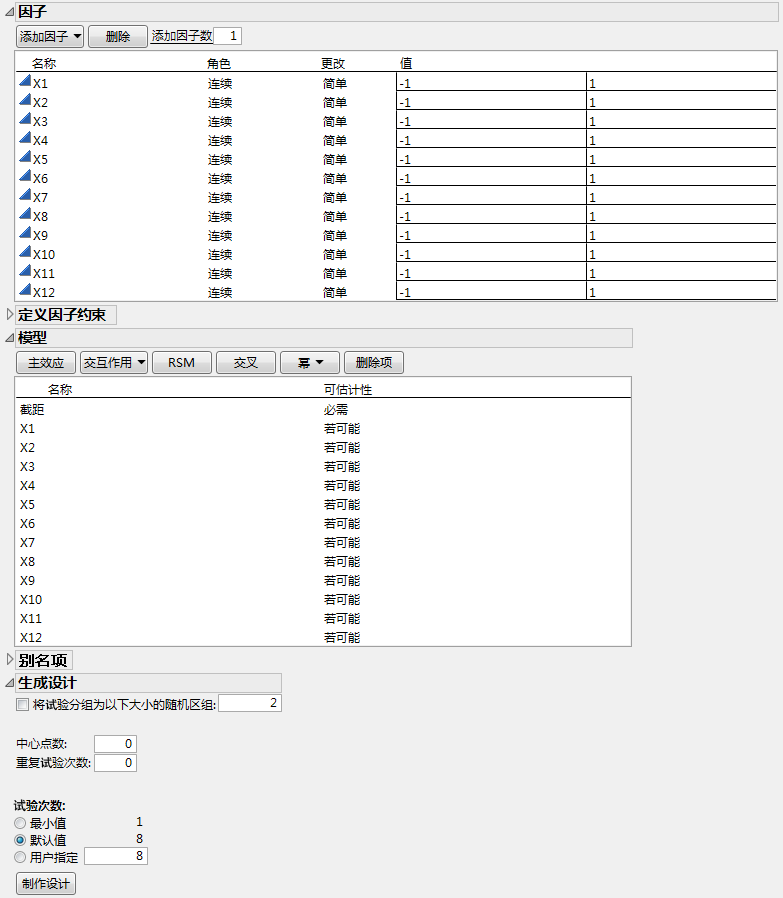
7. 在“别名项”分级显示项中,选择所有效应,然后点击删除项。
这将确保只有主效应才会显示在“相关性色图”中。一旦创建设计即构造该图。
8. 点击“定制设计”红色小三角,然后选择模拟响应。
该选项将生成显示在设计表中的随机响应。您需要使用这些响应来查看如何分析实验数据。
保持“试验次数”设置为默认值 8。
注意:在步骤 9中设置“随机种子”,在步骤 10中设置“开始数”,这将会重现本例中显示的设计。自行构造设计时,这些步骤不是必需的。
9. (可选)点击“定制设计”红色小三角,选择设置随机种子,键入 12345,然后点击确定。
10. (可选)点击“定制设计”红色小三角,选择开始数,键入 5,然后点击确定。
11. 点击制作设计。
12. 点击制表。
请不要关闭“定制设计”窗口。在本例中,您稍后会返回到该窗口。
包含模拟响应的设计表
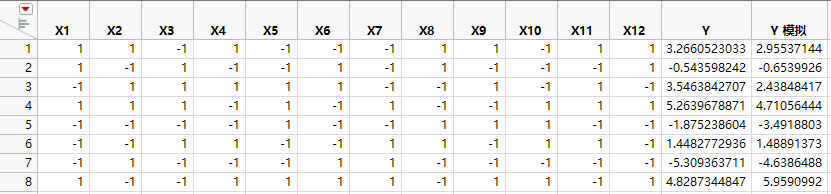
响应列 Y 和 Y 模拟的初始值具有相同的模拟值。这些值是来自 N(0, s) 分布的随机值。其中,s 是来自功效分析对话框的 RMSE,默认值为 1。Y 模拟值随着使用“模拟响应”窗口中的参数值定义的模型随机生成的值而更新。Y 列专用于运行实验后的真实响应。
“模拟响应”窗口

“模拟响应”窗口显示所有项的默认系数均为 1,分布选择为“正态”,“误差 s”为 1。Y 和 Y 模拟列中的值当前仅反映随机变异。
13. 更改“模拟响应”窗口中的系数的值,如模拟响应的参数值 所示。
模拟响应的参数值
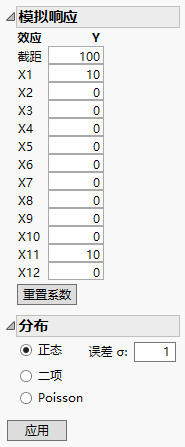
14. 点击应用。
Y 模拟列中的响应值随即更改。
注意:响应值随机生成。您的值不会与X1 和 X11 活跃时的 Y 模拟响应列 中的值精确匹配。
X1 和 X11 活跃时的 Y 模拟响应列
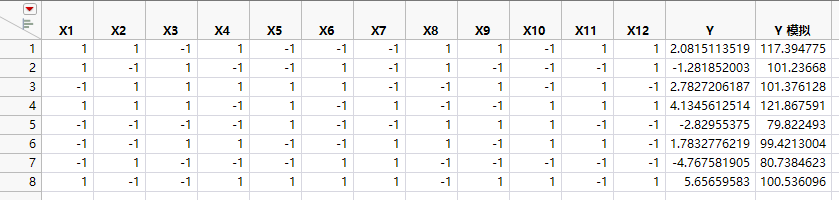
在您的模拟中,您将 X1 和X11 指定为活跃因子;相对于误差变异,这两个因子的效应较大。出于此原因,您在分析数据时应将这两个因子标识为活跃因子。
使用“筛选”平台分析超饱和设计
“筛选”平台提供了用于标识活跃因子的方法。使用“筛选”平台分析设计表中的 Y 模拟值(X1 和 X11 活跃时的 Y 模拟响应列)。“筛选”平台位于实验设计 > 经典菜单下。
1. 选择实验设计 > 经典 > 两水平筛选 > 拟合两水平筛选。
2. 选择 Y 模拟并点击 Y。
3. 从 X1 一直选择到 X12,然后依次点击 X 和确定。
超饱和设计的筛选报表
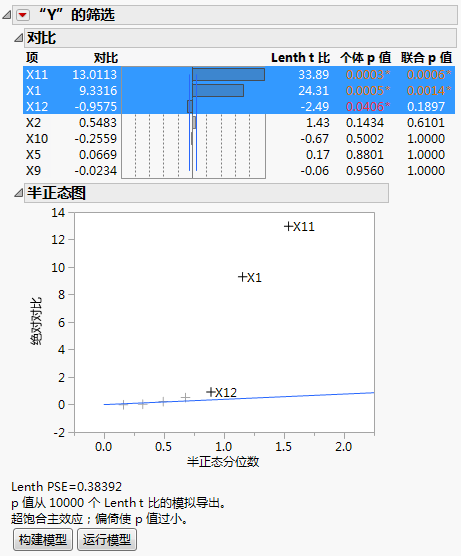
因子 X1 和 X11 具有较大的对比以及 Lenth t 比值。此外,这两个因子的“联合 p 值”较小。在半正态图中,X1 和 X11 均落在距离线条较远的位置。“对比”报表和“半正态图”报表指示 X1 和 X11 是活跃的。尽管 X12 的“个体 p 值”小于 0.05,但其效应比 X1 和 X11 的效应小得多。
由于设计超饱和,p 值可能比所有效应都可估计的模型中的 p 值要小。这是因为效应估计值因其他可能活跃的主效应产生偏倚。在超饱和设计的筛选报表 中,“构建模型”按钮正上方的注释提醒您这一可能性。
您可能还需要检查显示为活跃的效应是否与其他效应高度相关。若高度相关,则一个效应可能会掩盖另一个效应的真正显著性。“相关性色图”分级显示项 中的色图显示效应之间的绝对相关性。
4. 点击构建模型。
构造的模型仅包含效应 X1、X11 和 X12。
5. 在“模型规格”窗口中,点击运行。
模型的参数估计值
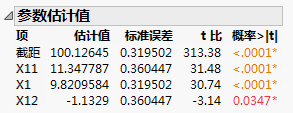
请注意,X11 和 X1 的参数估计值接近您用来模拟模型的理论值。请参见模拟响应的参数值,您在该窗口中指定了模型的 X1 = 10,X11 = 10。因子 X12 的显著性是假阳性的一个示例。
6. 在“定制设计”窗口中,打开设计评估 > 相关性色图分级显示项。
“相关性色图”分级显示项

将您的鼠标指针置于单元格上方可查看绝对相关性。请注意,X1 与其他主效应(X4、X5、X7)的相关性高达 0.5。(“相关性色图”分级显示项 使用 JMP 默认颜色。)
使用逐步回归分析超饱和设计
逐步回归是另一种标识活跃因子的方式。X1 和 X11 活跃时的 Y 模拟响应列 中的设计表包含三个脚本。“模型”脚本使用“拟合模型”平台中的逐步回归分析数据。
1. 在设计表的“表”面板中,点击模型脚本旁边的绿色小三角。
2. 将特质从标准最小二乘改为逐步。
3. 点击运行。
4. 在“Y 的逐步拟合”报表中,将停止规则改为最小 AICc。
对于设计的实验,BIC 通常是比 AICc 更为宽松的停止规则,因为 BIC 往往允许在模型中包含不活跃效应。
5. 点击执行。
超饱和设计的逐步回归
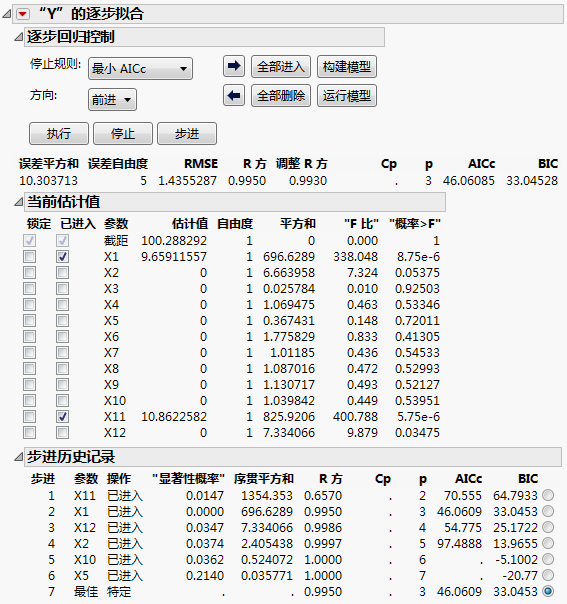
超饱和设计的逐步回归 显示选定模型包含两个活跃因子:X1 和 X11。步进历史记录显示在报表的底部。请记住,X1 和 X11 与其他因子的相关性可能掩盖其他活跃因子的效应(“相关性色图”分级显示项)。
注意:本例定义了两个较大的主效应并将其他效应设置为零。现实中不太可能有这种区分明显的效应。