变异统计量
使用 s 表示过程的标准差。“过程能力”平台提供了两种类型的能力指标。Ppk 指标基于 s 的估计值,它以不依赖于子组的方式使用所有数据。这一总估计值可能会反映特殊原因以及普通原因变异。Cpk 指标基于试图仅捕获普通原因变异的估计值。Cpk 指标使用 s 的子组内或组间和组内子组估计值来构造。这样,它们试图反映真实的过程标准差。若过程不稳定,s 的不同估计值会有明显差异。
总 Sigma
总 sigma 不依赖于子组。JMP 计算 s 的总估计值方法如下:
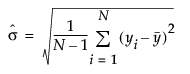
该公式使用以下符号:
N = 整个数据集中的非缺失值个数
yi = 第 i 个观测的值
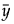 = 整个数据集中的非缺失值的均值
= 整个数据集中的非缺失值的均值
警告:若过程稳定,“总 Sigma”估计过程标准差。若过程不稳定,s 的总估计值是不可靠值,因为过程标准差未知。
基于子组内变异的 Sigma 的估计值
基于子组内变异的 s 的估计值可通过以下三种方式之一构造:
• 通过极差平均值估计的组内 sigma
• 通过无偏标准差的平均值估计的组内 sigma
• 通过移动极差估计的组内 sigma
• 无偏合并标准差估计的组内 sigma
若您在启动窗口中指定了子组 ID 列或常数子组大小,则可以指定首选子组内变异统计量。请参见启动“过程能力”平台。若不指定子组 ID 列、常数子组大小或历史 sigma,JMP 将使用第三种方法(大小为 2 的子组的移动极差)估计组内 sigma。
基于极差平均值的组内 sigma
通过极差平均值估计的组内 sigma 与均值和 R 图的标准差估计值相同:
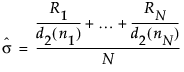
该公式使用以下符号:
Ri = 第 i 个子组的极差
ni = 第 i 个子组的样本大小
d2(ni) = 服从单位标准差正态分布的 ni 个自变量的极差期望值
N = ni ≥ 2 的子组数
基于无偏标准差的平均值的组内 sigma
通过无偏标准差的平均值估计的组内 sigma 与均值和 S 图的标准差估计值相同:
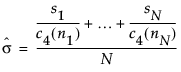
该公式使用以下符号:
ni = 第 i 个子组的样本大小
c4(ni) = 服从单位标准差正态分布的 ni 个自变量的标准差期望值
N = ni ≥ 2 的子组数
si = 第 i 个子组的样本标准差
基于平均移动极差的组内 Sigma
通过平均移动极差估计的组内 sigma 与“单个测量值”和“移动极差”图的标准差的估计值相同:
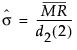
该公式使用以下符号:
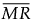 = 非缺失移动极差的均值,计算方式为 (MR2+MR3+...+MRN)/(N-1),其中 MRi = |yi - yi-1|。
= 非缺失移动极差的均值,计算方式为 (MR2+MR3+...+MRN)/(N-1),其中 MRi = |yi - yi-1|。
d2(2) = 服从单位标准差正态分布的两个自变量的极差期望值。
基于移动极差中位数的组内 Sigma
通过移动极差中位数估计的组内 sigma:
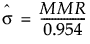
该公式使用以下符号:
MMR = 非缺失移动极差的中位数,计算方式为 Median(MR2, MR3,..., MRN),其中,MRi = |yi - yi-1|。
基于无偏合并标准差的组内 Sigma
通过无偏合并标准差估计的组内 sigma:
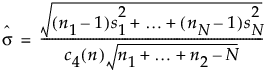
该公式使用以下符号:
ni = 第 i 个子组的样本大小
n = n1 + ¼ + nN,合计样本大小
c4(n) = 服从单位标准差正态分布的 n 个自变量的标准差的期望值
N = ni ≥ 2 的子组数
si = 第 i 个子组的样本标准差
基于组间变异的 Sigma 估计值
基于移动极差的组间 Sigma
基于子组间变异的 s 的估计值通过子组均值的移动极差来估计:
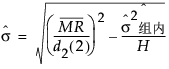
该公式使用以下符号:
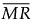 = 非缺失移动极差的均值,计算方式为 (MR2+MR3+...+MRN)/(N-1),其中 MRi = |yi - yi-1|。
= 非缺失移动极差的均值,计算方式为 (MR2+MR3+...+MRN)/(N-1),其中 MRi = |yi - yi-1|。
d2(2) = 服从单位标准差正态分布的两个自变量的极差期望值。
s2组内 = 指定的组内 sigma 估计值。
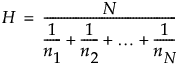 ,子组样本大小的调和均值。
,子组样本大小的调和均值。
基于组间和组内变异的 sigma 估计值
组间和组内 Sigma
基于组合的组间和组内变异的 Sigma 估计值定义如下:
