To produce the plot shown in Example of a Logistic Report, follow the instructions in Example of Nominal Logistic Regression.
Note: The red triangle menu provides more options that can add to the initial report window. See Logistic Platform Options.
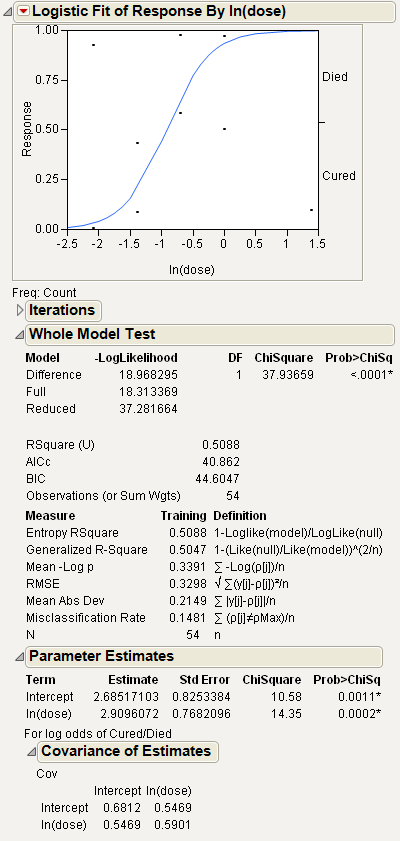
The logistic probability plot gives a complete picture of what the logistic model is fitting. At each x value, the probability scale in the y direction is divided up (partitioned) into probabilities for each response category. The probabilities are measured as the vertical distance between the curves, with the total across all Y category probabilities summing to 1.
The Whole Model Test report shows if the model fits better than constant response probabilities. This report is analogous to the Analysis of Variance report for a continuous response model. It is a specific likelihood-ratio Chi-square test that evaluates how well the categorical model fits the data. The negative sum of natural logs of the observed probabilities is called the negative log-likelihood (–LogLikelihood). The negative log-likelihood for categorical data plays the same role as sums of squares in continuous data. Twice the difference in the negative log-likelihood from the model fitted by the data and the model with equal probabilities is a Chi-square statistic. This test statistic examines the hypothesis that the x variable has no effect on the responses.
Values of the Rsquare (U) (sometimes denoted as R2) range from 0 to 1. High R2 values are indicative of a good model fit, and are rare in categorical models.
|
|||||||
|
Measures variation, sometimes called uncertainty, in the sample.
Full (the full model) is the negative log-likelihood (or uncertainty) calculated after fitting the model. The fitting process involves predicting response rates with a linear model and a logistic response function. This value is minimized by the fitting process.
Reduced (the reduced model) is the negative log-likelihood (or uncertainty) for the case when the probabilities are estimated by fixed background rates. This is the background uncertainty when the model has no effects.
For more information, see Fitting Linear Models.
|
|||||||
|
The likelihood-ratio Chi-square test of the hypothesis that the model fits no better than fixed response rates across the whole sample. It is twice the –LogLikelihood for the Difference Model. It is two times the difference of two negative log-likelihoods, one with whole-population response probabilities and one with each-population response rates.
|
|||||||
|
The observed significance probability, often called the p value, for the Chi-square test. It is the probability of getting, by chance alone, a Chi-square value greater than the one computed. Models are often judged significant if this probability is below 0.05.
|
|||||||
|
The corrected Akaike Information Criterion. See Fitting Linear Models.
|
|||||||
|
The Bayesian Information Criterion. See Fitting Linear Models.
|
|||||||
|
The total sample size used in computations. If you specified a Weight variable, this is the sum of the weights.
|
|||||||
|
is a measure that can be applied to general regression models. It is based on the likelihood function L and is scaled to have a maximum value of 1. The Generalized RSquare measure simplifies to the traditional RSquare for continuous normal responses in the standard least squares setting. Generalized RSquare is also known as the Nagelkerke or Craig and Uhler R2, which is a normalized version of Cox and Snell’s pseudo R2. See Nagelkerke (1991).
|
|||||||
The nominal logistic model fits a parameter for the intercept and slope for each of 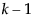 logistic comparisons, where k is the number of response levels. The Parameter Estimates report lists these estimates. Each parameter estimate can be examined and tested individually, although this is seldom of much interest.
logistic comparisons, where k is the number of response levels. The Parameter Estimates report lists these estimates. Each parameter estimate can be examined and tested individually, although this is seldom of much interest.