Simple Linear Regression
What is simple linear regression?
Simple linear regression is used to model the relationship between two continuous variables. Often, the objective is to predict the value of an output variable (or response) based on the value of an input (or predictor) variable.
When to use regression
See how to perform simple linear regression using statistical software
- Download JMP to follow along using the sample data included with the software.
- To see more JMP tutorials, visit the JMP Learning Library.
We are often interested in understanding the relationship among several variables. Scatterplots and scatterplot matrices can be used to explore potential relationships between pairs of variables. Correlation provides a measure of the linear association between pairs of variables, but it doesn’t tell us about more complex relationships. For example, if the relationship is curvilinear, the correlation might be near zero.
You can use regression to develop a more formal understanding of relationships between variables. In regression, and in statistical modeling in general, we want to model the relationship between an output variable, or a response, and one or more input variables, or factors.
Depending on the context, output variables might also be referred to as dependent variables, outcomes, or simply Y variables, and input variables might be referred to as explanatory variables, effects, predictors or X variables.
We can use regression, and the results of regression modeling, to determine which variables have an effect on the response or help explain the response. This is known as explanatory modeling.
We can also use regression to predict the values of a response variable based on the values of the important predictors. This is generally referred to as predictive modeling. Or, we can use regression models for optimization, to determine settings of factors to optimize a response. Our optimization goal might be to find settings that lead to a maximum response or to a minimum response. Or the goal might be to hit a target within an acceptable window.
For example, let’s say we’re trying to improve process yield.
- We might use regression to determine which variables contribute to high yields,
- We might be interested in predicting process yield for future production, given values of our predictors, or
- We might want to identify factor settings that lead to optimal yields.
We might also use the knowledge gained through regression modeling to design an experiment that will refine our process knowledge and drive further improvement.
Linear regression example
Consider an example where we are interested in the cleaning of metal parts.
We have 50 parts with various inside diameters, outside diameters, and widths. Parts are cleaned using one of three container types. Cleanliness is a measure of the particulates on the parts. This is measured before and after running the parts through the cleaning process. The response of interest is Removal. This is the difference between pre-cleaning and post-cleaning measures.
We’re interested in whether the inside diameter, outside diameter, part width, and container type have an effect on the cleanliness, but we’re also interested in the nature of these effects. The relationship we develop linking the predictors to the response is a statistical model or, more specifically, a regression model.
The term regression describes a general collection of techniques used in modeling a response as a function of predictors. The only regression models that we'll consider in this discussion are linear models.
An example of a linear model for the cleaning data is shown below.
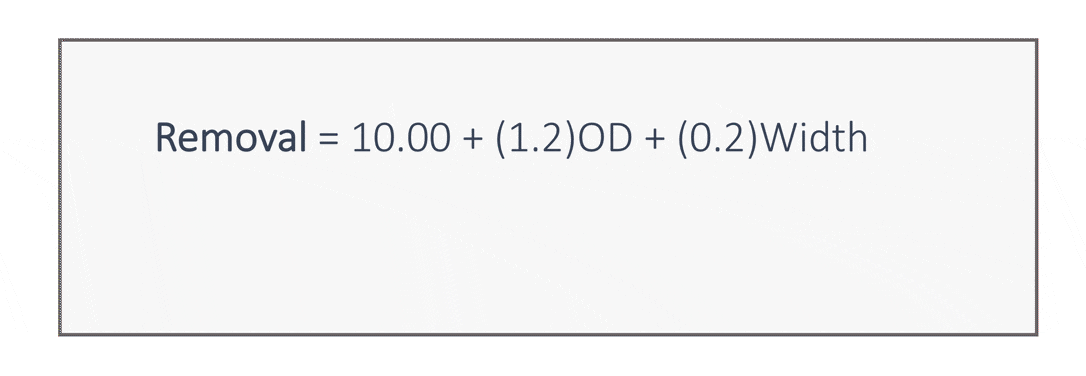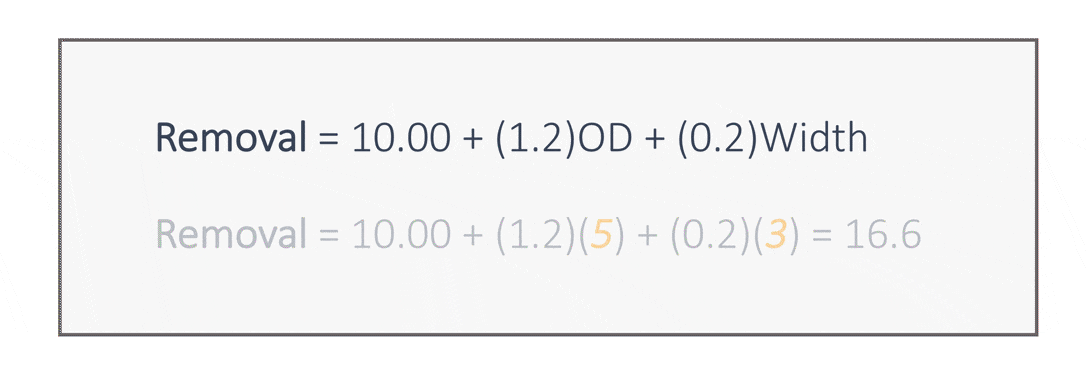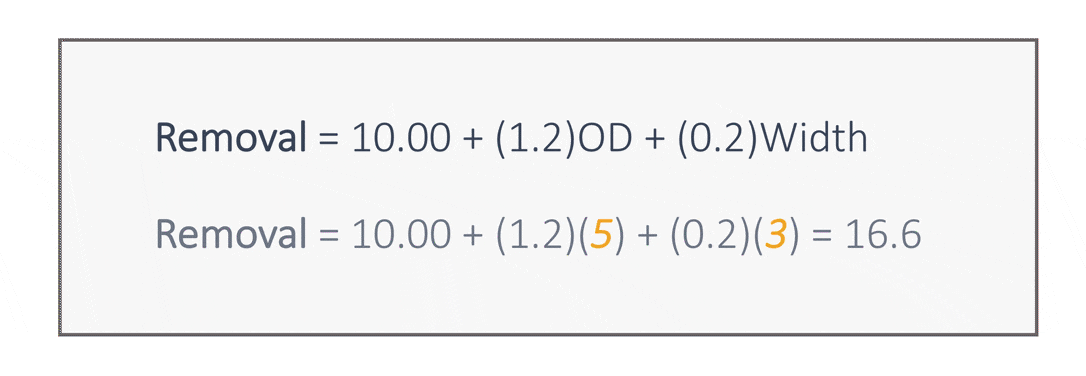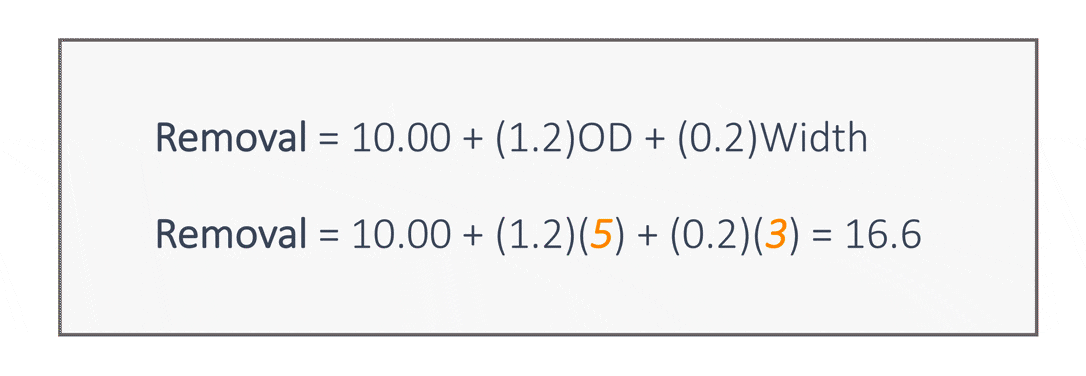
In this model, if the outside diameter increases by 1 unit, with the width remaining fixed, the removal increases by 1.2 units. Likewise, if the part width increases by 1 unit, with the outside diameter remaining fixed, the removal increases by 0.2 units. This model enables us to predict removal for parts with given outside diameters and widths.
For example, the predicted removal for parts with an outside diameter of 5 and a width of 3 is 16.6 units. In this example, we have two continuous predictors. When more than one predictor is used, the procedure is called multiple linear regression.
When only one continuous predictor is used, we refer to the modeling procedure as simple linear regression. For the remainder of this discussion, we'll focus on simple linear regression.
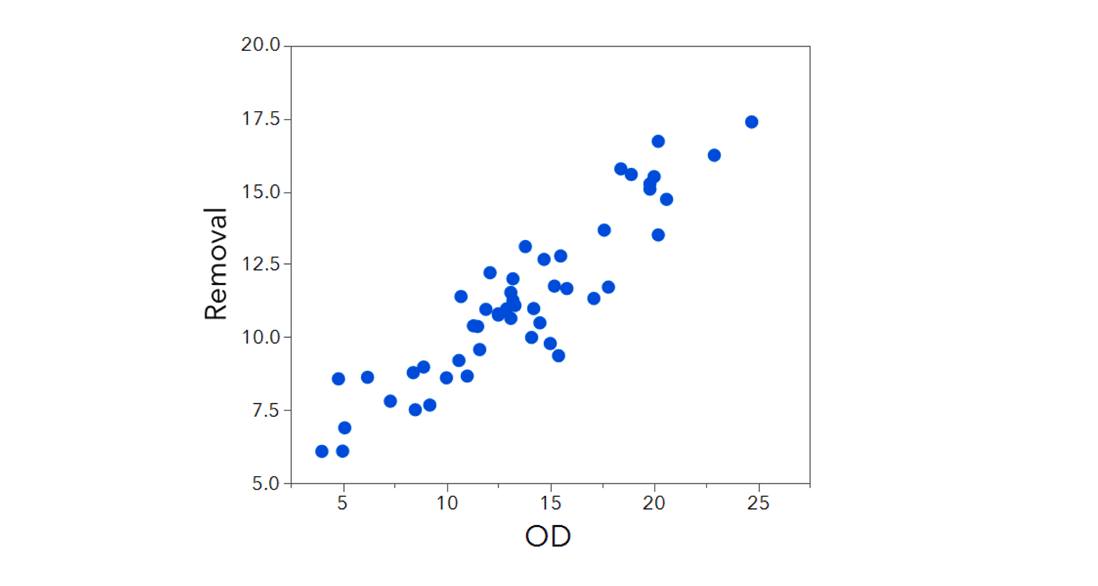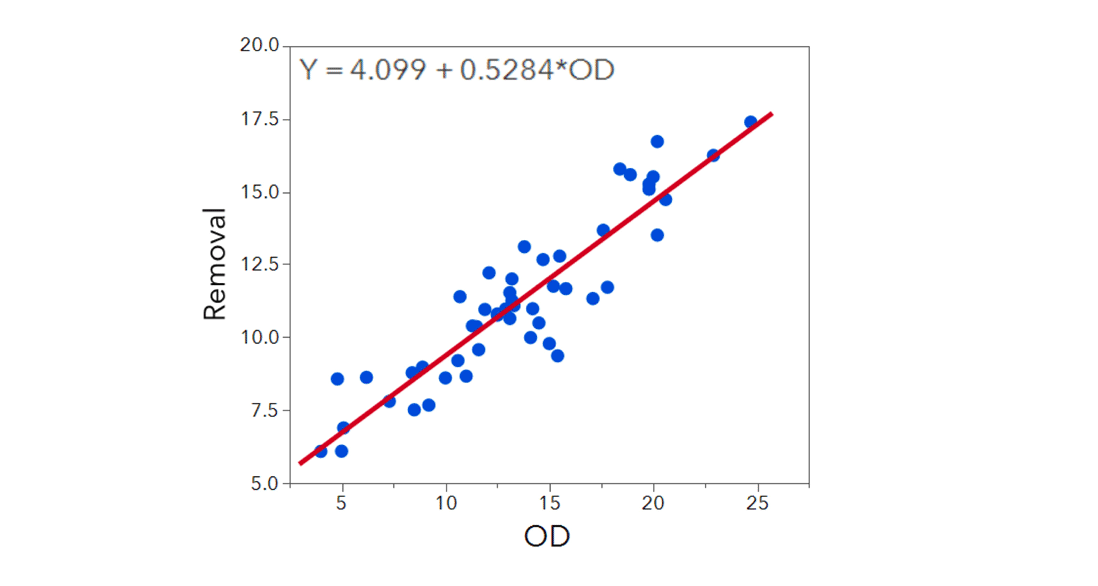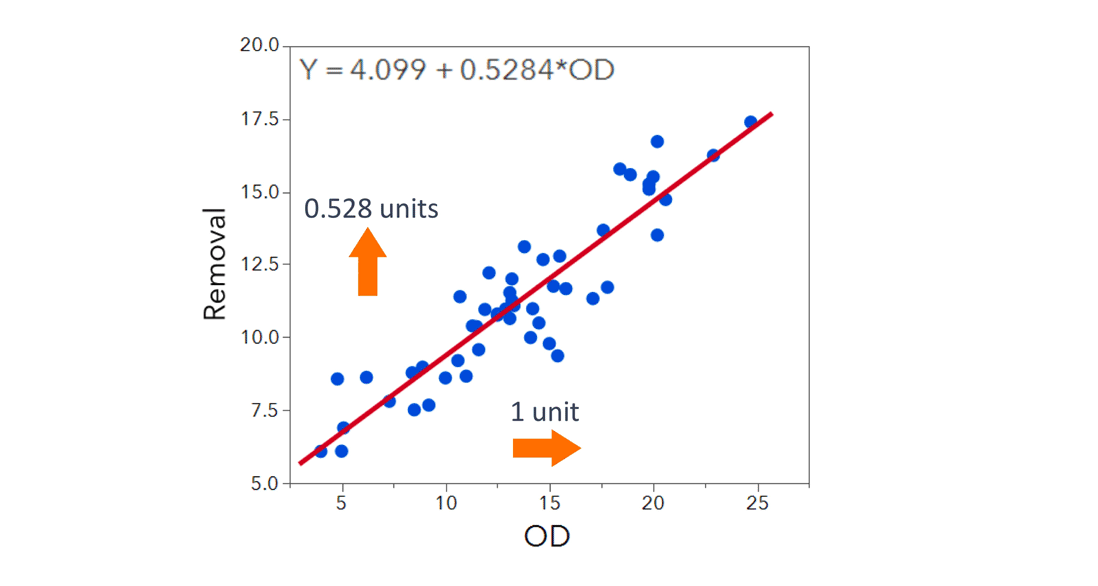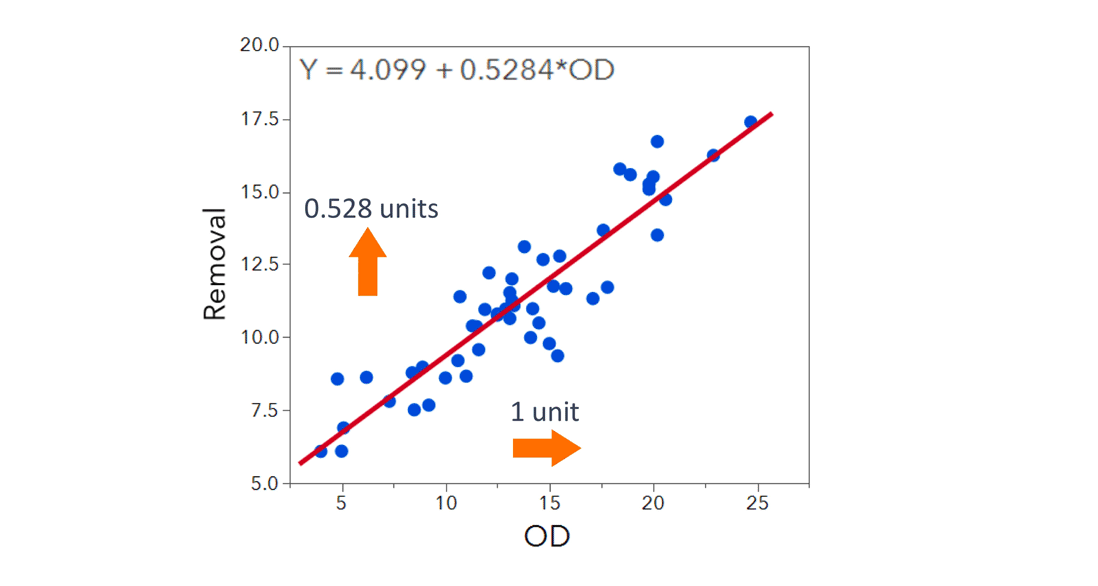
A scatterplot indicates that there is a fairly strong positive relationship between Removal and OD (the outside diameter). To understand whether OD can be used to predict or estimate Removal, we fit a regression line. The fitted line estimates the mean of Removal for a given fixed value of OD. The value 4.099 is the intercept and 0.528 is the slope coefficient. The intercept, which is used to anchor the line, estimates Removal when the outside diameter is zero. Because diameter can’t be zero, the intercept isn’t of direct interest.
The slope coefficient estimates the average increase in Removal for a 1-unit increase in outside diameter. That is, for every 1-unit increase in outside diameter, Removal increases by 0.528 units on average.
The simple linear regression model
In the example above, we collected data on 50 parts. We fit a regression model to predict Removal as a function of the OD of the parts. But what if we had sampled a different set of 50 parts and fit a regression line using these data? Would this produce the same regression equation? By fitting a regression line to observed data, we are trying to estimate the true, unknown relationship between the variables. This fitted regression equation is just one estimate of the true linear model. In reality, the true linear model is unknown.
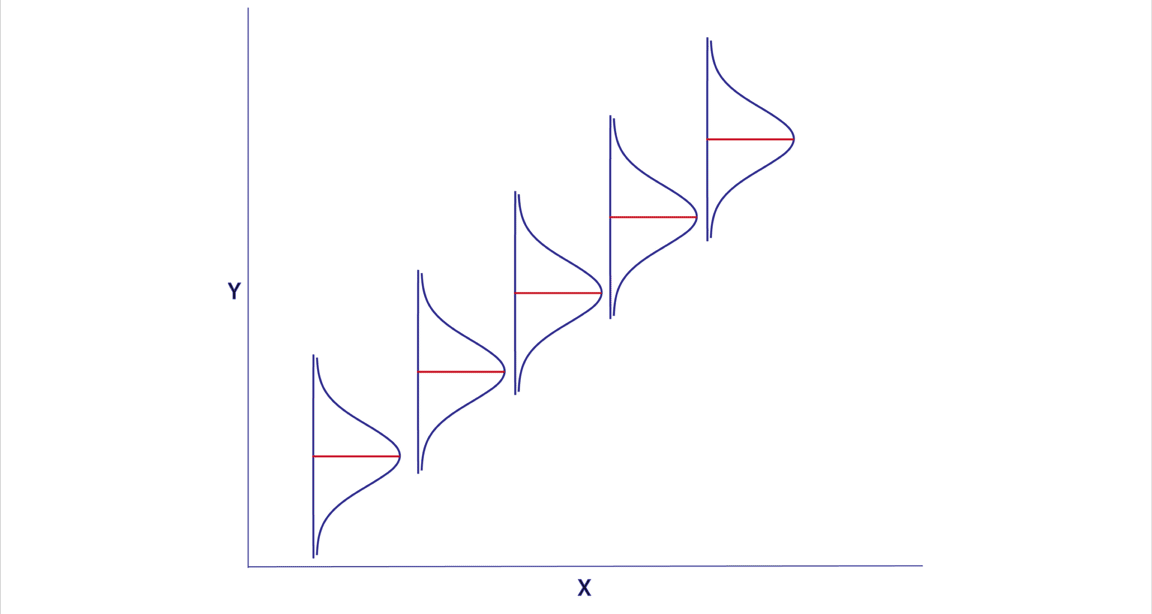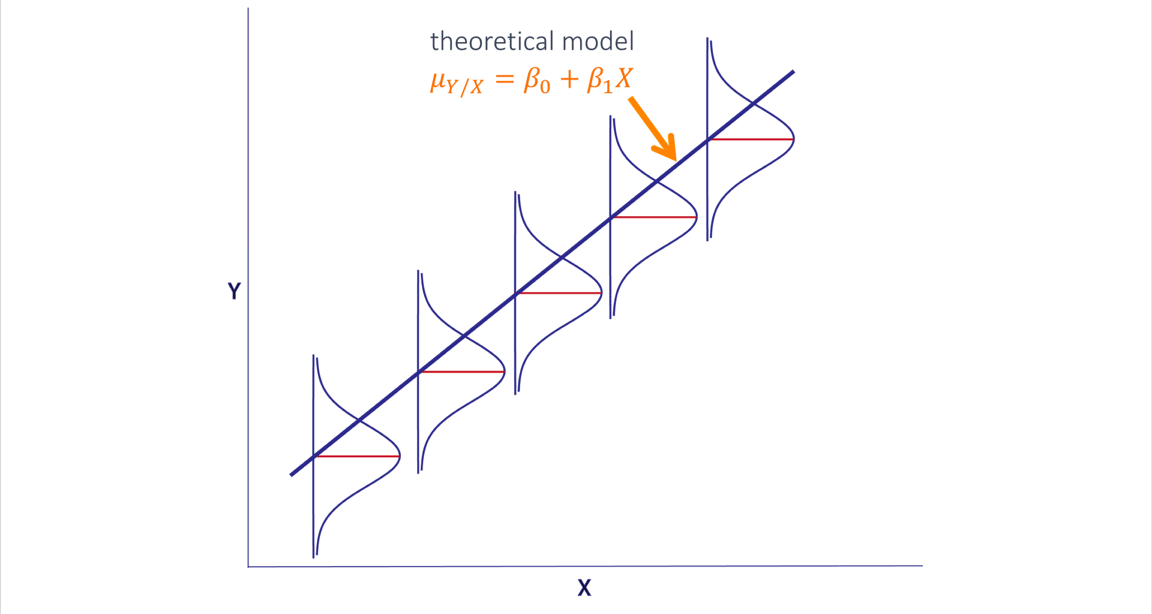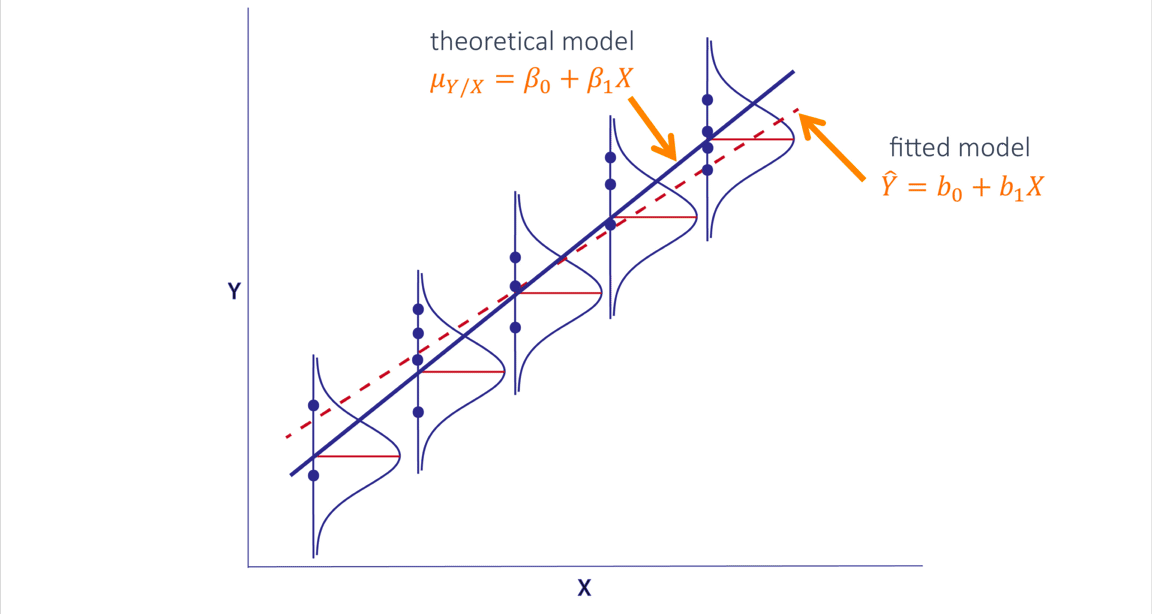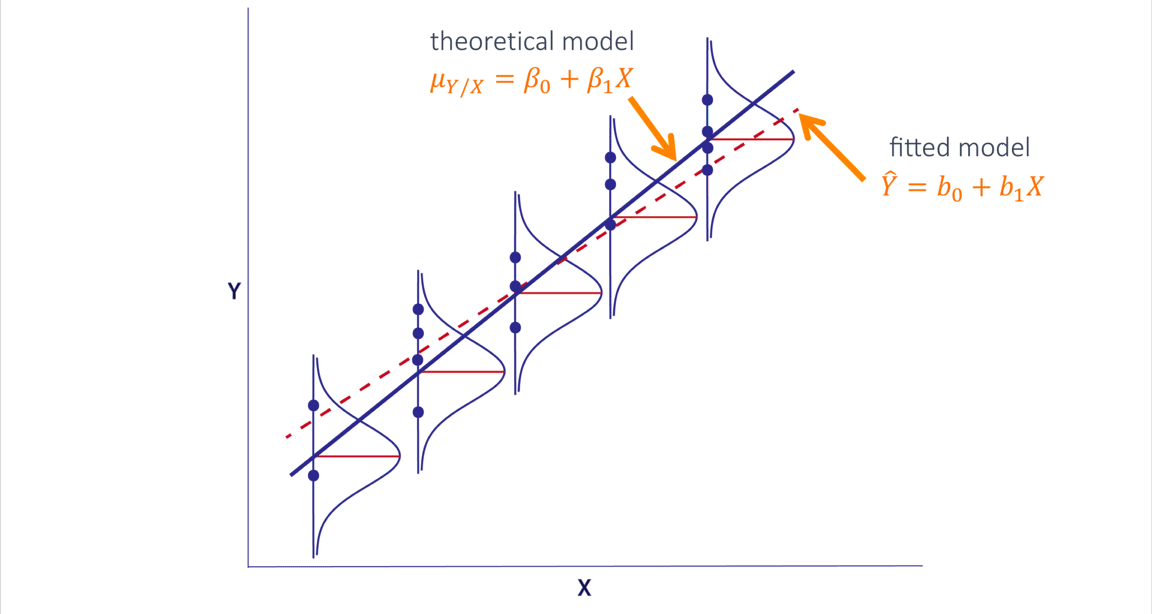
In simple linear regression we assume that, for a fixed value of a predictor X, the mean of the response Y is a linear function of X. We denote this unknown linear function by the equation shown here where b0 is the intercept and b1 is the slope. The regression line we fit to data is an estimate of this unknown function.
The equation of the fitted line is denoted by the following equation:

Here, b0 and b1 are estimates of beta0 and beta1, respectively. The notation $ \hat{Y} $ (in this case, Y = Removal) indicates that the response is estimated from the data and that it is not an actual observation. In the cleaning example, the intercept, b0, is 4.099 and the slope, b1, is 0.528.
If we select a different sample of parts, our fitted line will be different. To illustrate, we use the Demonstrate Regression teaching module in the JMP sample scripts directory.
Regression vs. ANOVA
Let’s compare regression and ANOVA. In simple linear regression, both the response and the predictor are continuous. In ANOVA, the response is continuous, but the predictor, or factor, is nominal. The results are related statistically. In both cases, we’re building a general linear model. But the goals of the analysis are different.
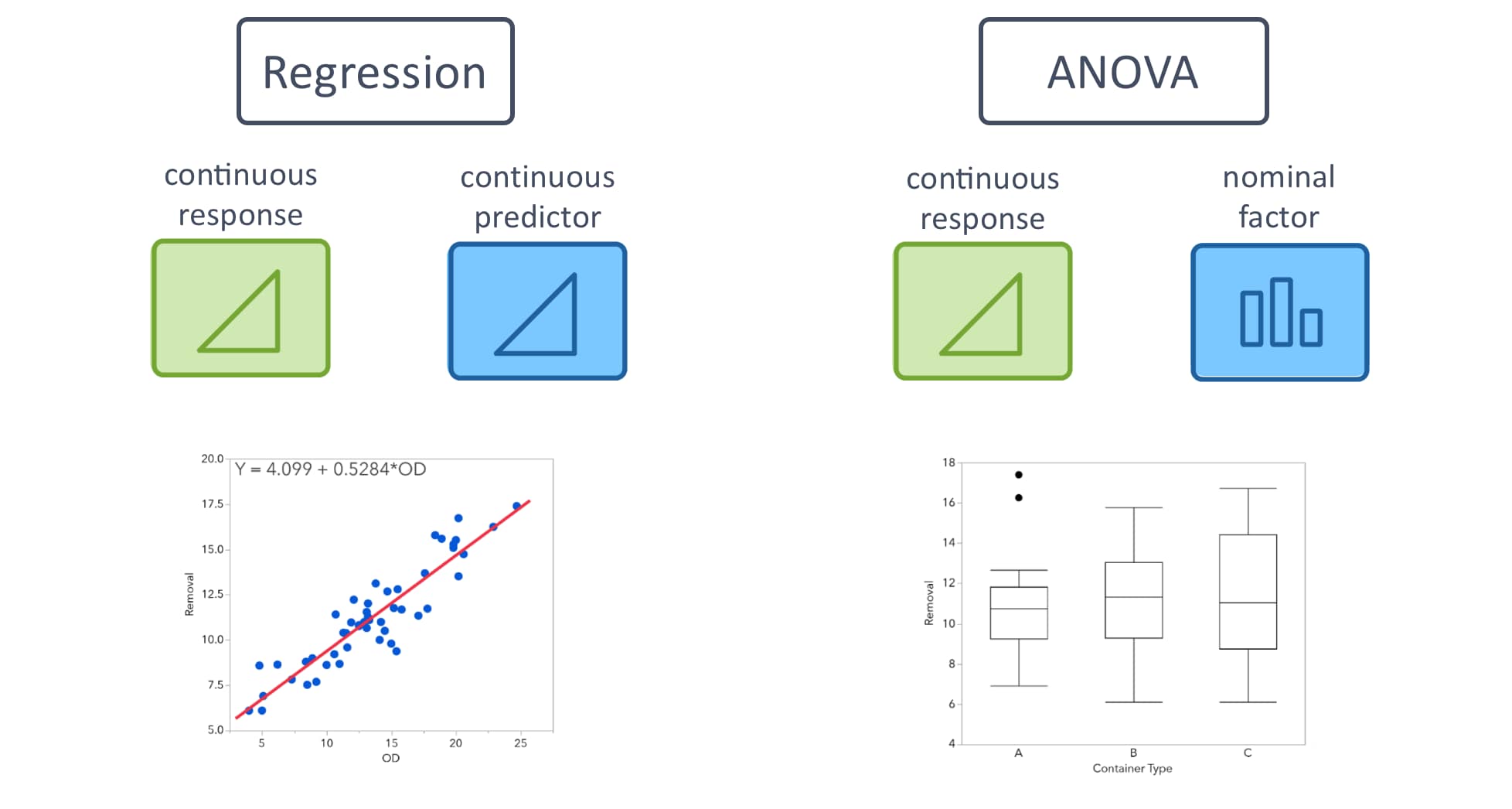
Regression gives us a statistical model that enables us to predict a response at different values of the predictor, including values of the predictor not included in the original data.
ANOVA measures the mean shift in the response for the different categories of the factor. As such, it's generally used to compare means for the different levels of the factor.