Distribution Reports
This chapter describes the general analysis performed by the JMP Clinical Adverse Events Distribution, Events Distribution, Interventions Distribution, and Findings Distribution reports. These descriptions apply generally for any event or intervention domain and can be found in the following sections:
AE/Events/Interventions Distributions Workflows and Computations
Understanding Count and Percent Calculations
Note: The Findings Distribution report has slightly different analyses and results and is covered briefly in a separate section.
AE/Events/Interventions Distributions Workflows and Computations
The Adverse Events Distribution report is used as an example to describe the analysis performed. This report has the most sophisticated Report Options of all the distribution reports for customizing the resulting reports. Other Events/Interventions domains follow a similar, although simpler, workflow.
Adverse Events Distribution requires (or expects) several demographic- and specific domain-related variables to generate full report results. The system is flexible. If a certain variable does not exist, the analysis is still performed without it whenever a related variable can be substituted. For example, in adverse event, required, or expected, variables include:
| • | USUBJID, |
| • | a treatment variable (examples include either TRTxxP or TRTxxA, ARM, or a specified comparison variable1), |
| • | AGE, SEX, RACE, SITEID, COUNTRY, STUDYID (All are optional), |
| • | Treatment Date/Time variables (required if filtering interventions/events based on study treatment). These can include TRTSDTM, TRTSDTC, TRTEDTM, TRTEDTC (ADSL) or RFXSTDC, RFSTDTC, RFXENDTC, RFENDTC (DM domain), EXSTDTC, and EXENDTC (EX domain), |
| • | AEDECOD, AETERM, AEBODSYS, or other higher level term (at least one of these is required), |
| • | AESTDTC (Required), |
| • | AESER, either AESEV or AETOXGR, AEREL, AEOUT, and AEACN (All are optional). |
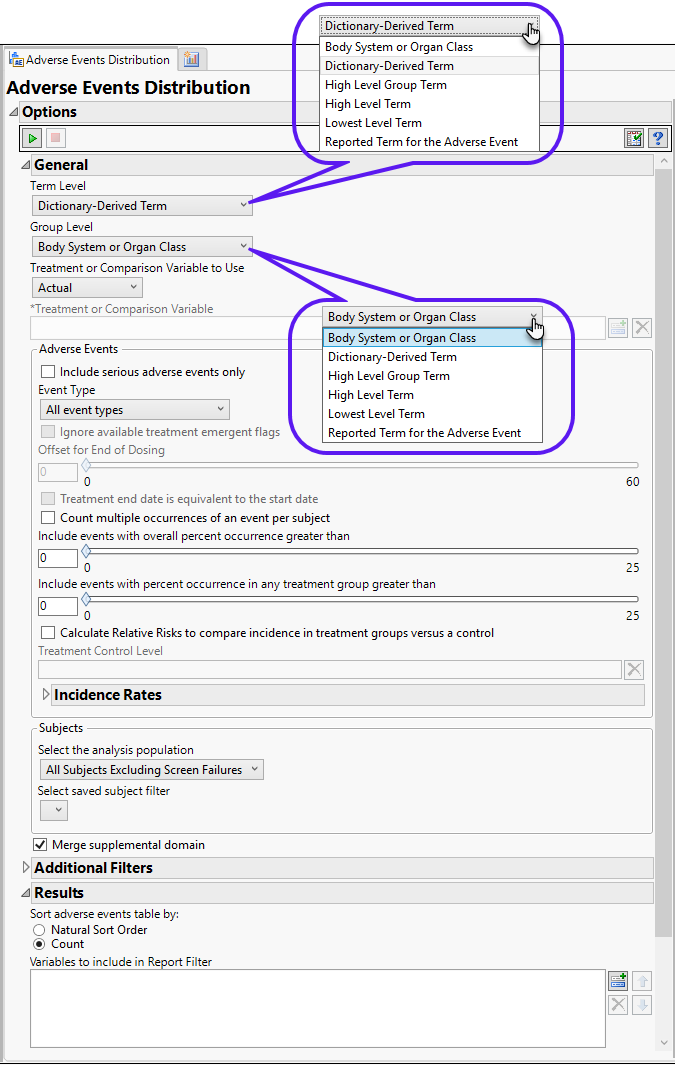
The Adverse Events Distribution dialog (shown below) enables you to use the term level and group level that are available in your ae.sas7bdat data so that while AEDECOD and AEBODSYS are specified by default variables in the examples shown here, this specification can be customized based on the term levels available in the given Study.
Distribution Workflow Summary
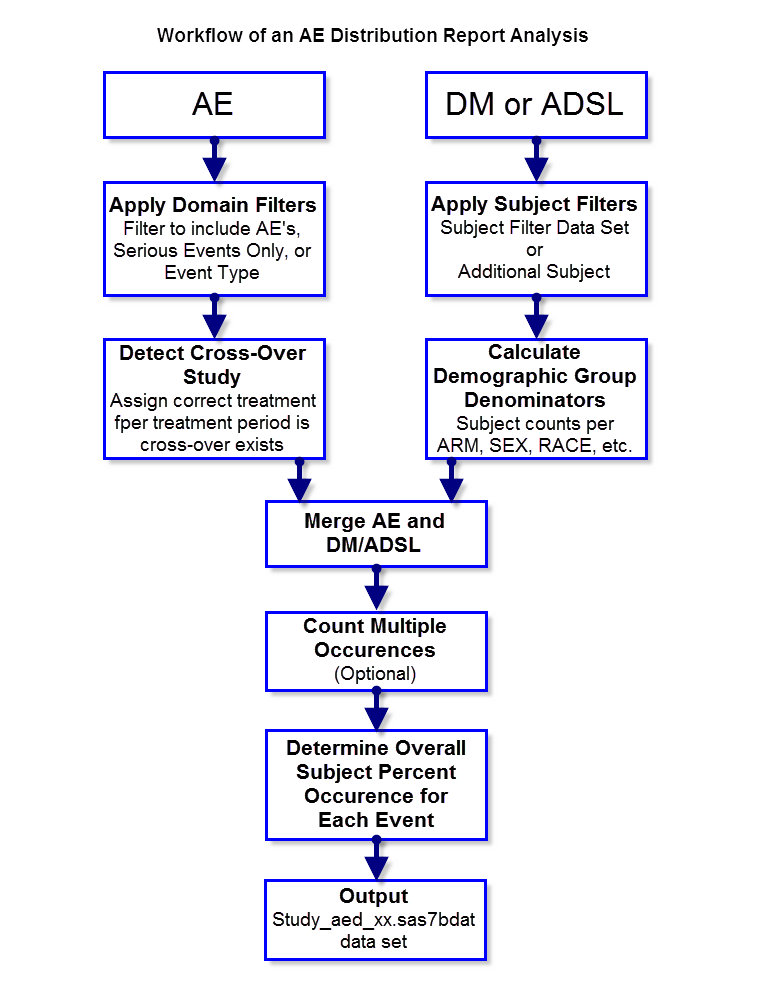
The following diagram outlines the analysis performed to summarize adverse events count and percent calculations for the Adverse Events Distribution report.
Distribution Workflow Steps
Apply Domain Filters
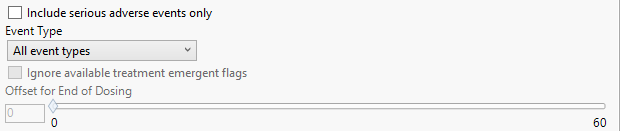
Three parameters, Include serious adverse events only, Event Type and Offset for End of Dosing, are used to specify a domain filter.
Available options are described in the following table:
|
Option: |
Select when you want to: |
|||||||||
|
||||||||||
|
Event Type options rely on the available Date/Time start and end variables referenced above. Options include: |
||||||||||
|
All event types |
|
|||||||||
|
Pre treatment events |
|
|||||||||
|
Treatment emergent adverse events |
|
|||||||||
|
On treatment events |
|
|||||||||
|
Off treatment followup events |
|
|||||||||
You can also use the Include the following adverse events: and Filter to Include Adverse Events options based on user-customized condition and/or on new/modified/stable records (when JMP Clinical snapshot comparison is being used)
Apply Subject Filters
These options filter the available subjects to use for the analysis and impact both the counts of adverse events (relevant events are considered only for subject in the analysis population) as well as for computing denominators to perform subject percent calculation.
Three parameters, Select saved subject filter, Additional Filter to Include Subjects and Select the population to include in the analysis, are used to specify a domain filter.
Available options are described in the following table:
|
Option: |
Select when you want to use a: |
||||||
|
|||||||
|
|||||||
|
Detect Crossover Study
If an ADSL table is defined and contains multiple treatment periods (TRTxxP for example) and treatment period start/stop dates, ADSL is merged in and the corresponding treatment and period is assigned based on comparison with AESDTC.
Calculate Demographic Group Denominators
Fixed adverse event frequency/percent values are not computed from output in the results data set. Instead, the subject counts for all relevant treatment and demography variables are computed, in order to support interactive computation of AE subject percent calculations based on user filtering and selection of treatment or demographic group categories.
Note: If you want to output static AE percent tables only, the Create Static Report( ) action button should be used.
) action button should be used.
The subject counts for each value of relevant demographic variables (Treatment, SEX, RACE, COUNTRY, SITEID, STUDYID (if not constant) are computed and then the reciprocal of the subject count is recorded in the DM or ADSL data set for merging into AE. This value can be used as a frequency weight for each subject that has a specific event to calculate the percent of subjects for that given demographic group that experience the AE.
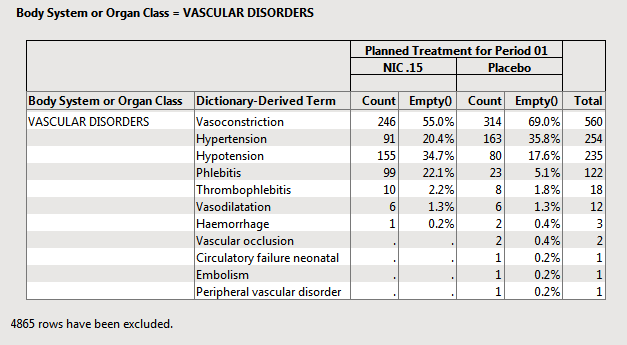
The following example uses the Nicardipine data included with JMP Clinical.
In this example:
| • | 455 subjects were on Placebo. |
| • | The reciprocal 1/455 = .00219. This value can be used for each subject that has an AE to compute the percentage. |
| • | 314 subject on placebo experience Vasoconstriction. |
| • | 314 x 1/455 = 314/455 = .6901 or 69.0% of subjects on placebo experienced Vasoconstriction. |
These reciprocal or frequency variables based on the demographic variable counts for each subject are computed and used when merged into the AE records table to compute percentages.
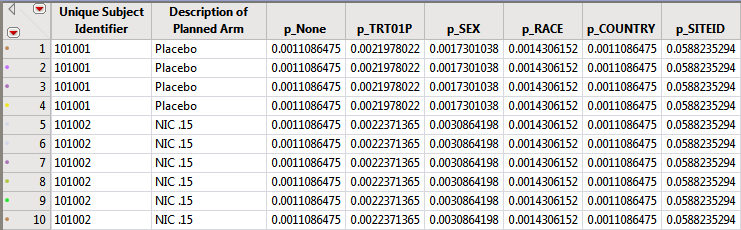
These columns are used in the distribution results dashboard to dynamically calculate percentages. Further examples are given when describing the dashboard results.
Note: If crossover is detected, these demographic counts represent the total subjects for treatment values summed across each period.
Merge AE and DM/ADSL
The (filtered) AE data and the (filtered) DM or ADSL table (with computed demographic frequencies) are merged by USUBJID (and treatment period if crossover is detected)
Optional Count Multiple Event Occurrence
The dialog contains an option to count multiple occurrences of events.

This option is turned OFF by default.
Percent calculations are performed only if this option is UNCHECKED so that when a unique event is counted only once per subject, you can interpret the frequency of AE counts as the percentage of subjects experiencing the event. The representative adverse event is chosen based on Seriousness (AESER if exists), Severity (AESEV), and computed study day (AESTDY or based on AESDTC)
Note: JMP Clinical assumes accordance with controlled terminology: "Y" to represent severe events, and "MILD", "MODERATE", "SEVERE" to select the serious, most severe event as representative.
For other events/interventions, the representative unique occurrence is chosen based on the first occurrence. The following help documentation for the Count multiple occurrences of an event per subject check box option describes the result of this option.
|
Box state: |
Result: |
|
Unchecked |
Compute counts based on the number of subjects that had a specific intervention. Each subject contributes only one time to the occurrence count of an intervention, regardless of how many times that specific intervention might have been applied to the subject. Note: Representative intervention occurrence per subject is selected by sorting the data and taking the first intervention occurring to a subject based on Study Day. |
|
Checked |
Compute counts based on the overall counts of interventions, including multiple occurrences per subject. |
Overall Subject Percent Occurrence for Each Event
This step is performed only when a unique occurrence of an event is counted (based on above check box option). This is total percent of subjects experiencing an event, calculated for each event.
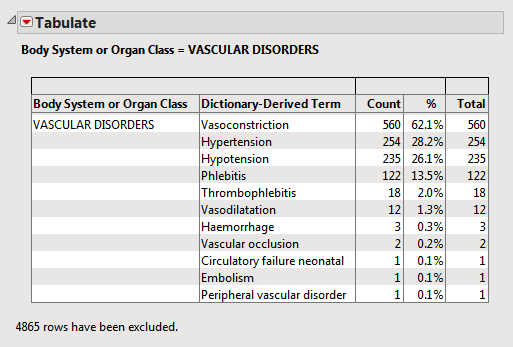
For example, in the Nicardipine data , 560 of the 902 subjects in the safety population experienced vasoconstriction.
| • | 560/902 = 0.621 or 62.1% of all subjects had a vasoconstriction event, regardless of treatment. |
After all of these steps have been completed, the STUDY_ae_xx.sas7bdat results table is used for the JMP results dashboard report.
Distribution Report Results
The distribution reports are designed to enable you to customize the specific view according to your individual needs. While there are too many options to fully describe, the several examples presented below highlight the variety of reports that can be generated.
In general, an AE/events/interventions report contain the following key components.
| • | A count (or percent) graph, optionally split by treatment/demographic groups |
| • | A count (and percent) table that reflects the numbers shown in the count plot. |
| • | Distributions of the event/intervention, descriptive variables about the event/intervention (for example, for AEs this could include Body System, Seriousness, Severity, Causality, Outcome, Action Taken, and so on), and demographic distributions of subjects experiencing the event/intervention |
| • | A Data Filter with several default variables to filter/subject the report view. |
| • | Multiple Variables that can be added/removed by the user to further customize the report |
| • | Additional Down panel options |
| • | Column Switchers: Choose the grouping variable used as the demographic comparison for the counts plot and table and a stacking variable to categorize events/interventions (especially useful with adverse events). |
| • | Profile Subjects: Generates Patient Profiles for subjects experiencing selected events. |
| • | Show Subjects: Subsets and opens ADSL (or DM, if ADSL is unavailable) for subjects experiencing selected events. A Table of USUBJIDs is also presented. |
| • | Create Subject Filter: Creates a data set of USUBJIDs for subjects experiencing selected events, which subsets all subsequently run reports to those selected individuals. The currently available filter data set can be applied by selecting the Subject Filter data set in any report dialog on the Filters tab. |
| • | Related CM (AE/Events Distribution only): For subjects experiencing selected events, this action button launches Interventions Distribution to summarize the distribution of concomitant medications (CM). |
| • | Demographic Counts: For subjects experiencing selected events, this action button generates a stacked Histogram to show subjects across study sites by Trial Time Windows. |
| • | Related Labs: For subjects experiencing selected events, this action button launches Findings Time Trends to summarize laboratory results (LB) across time. |
| • | Related Vitals: For subjects experiencing selected events, this action button launches Findings Time Trends to summarize vitals signs (VS) across time. |
| • | Related ECG: For subjects experiencing selected events, this action button launches Findings Time Trends to summarize ECG measurements (EG) across time. |
| • | Related AE (Interventions Distribution only): For subjects taking selected medications, this action button launches Adverse Events Distribution to summarize the distribution of adverse events (AE). |
| • | There are additional options to view analysis data set, reopen the dialog that generated the results, create a static PDF (or RTF) report of the results, and add/view notes tracked in the JMP Clinical system. |
The AE Distribution report described in this example is shown below:
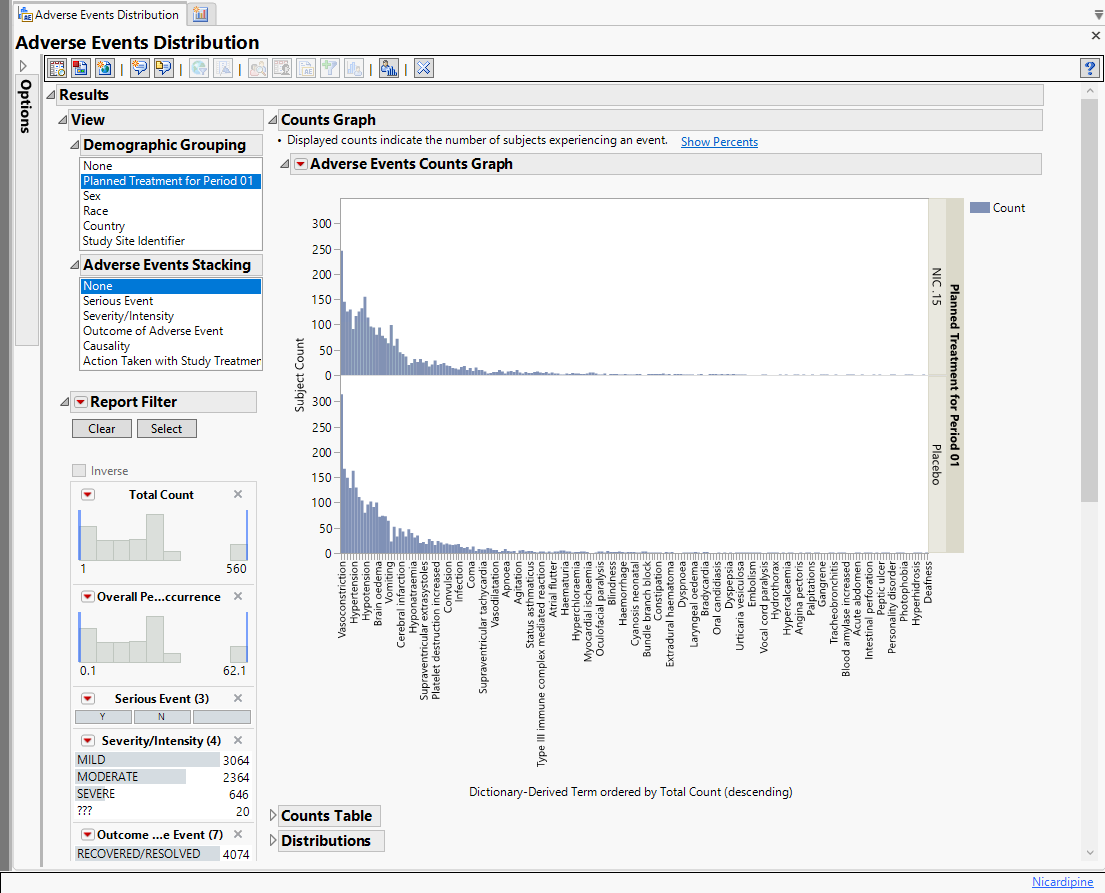
Example 1: AE Distribution Treatment Emergent Adverse Events That Occur in at Least 5% of Subjects in a Safety Population
| 8 | Open Adverse Events Distribution. |
| 8 | Find the filter option that enables you to set the overall percent occurrence (circled below): |
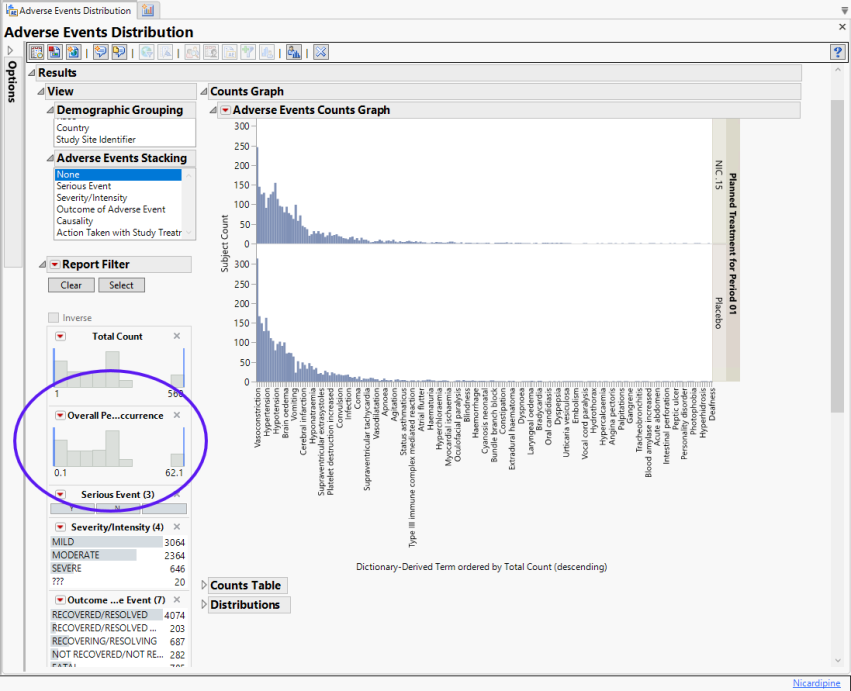
| 8 | Use your cursor to "grab" the lower limit and drag it to 5%. |
| 8 | Adjust the Adverse Event Stacking optionto display results by Severity/Intensity. |
The results of this analysis are based on summarizing adverse events by Dictionary-Derived Term (AEDECOD) with group organization as Body System or Organ Class (AEBODSYS). Variations of options for this are dependent on the available terms in the domain data set.
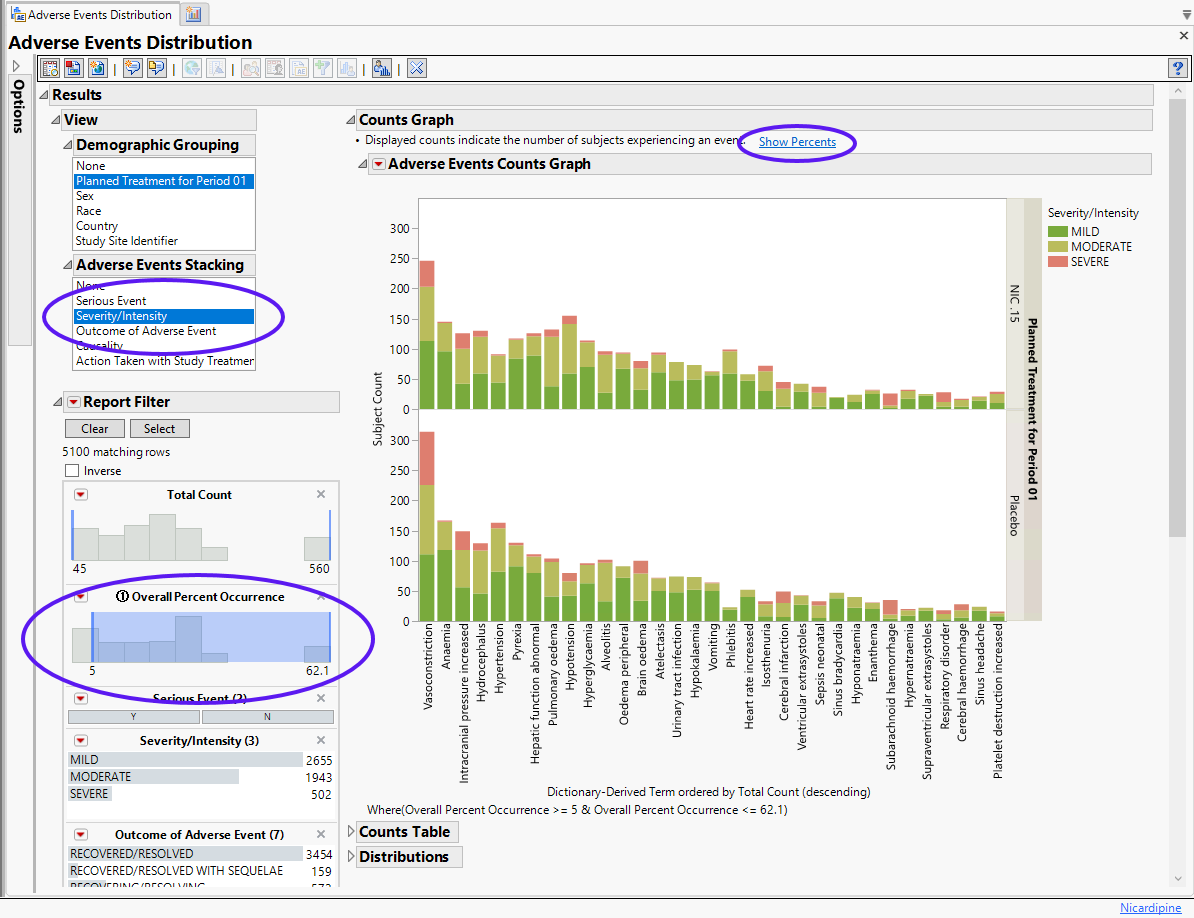
The counts (Y axis) represent the count of subjects that experienced the given event term (X axis); the counts are categorized as stacked bar charts for levels of Severity/Intensity (AESEV). This categorization is a result of choosing that variable from the AE Stacking action button.
When a unique occurrence is counted only for each subject/event, the percent of subjects experiencing an event within any of the available demographic grouping variables is calculated interactively by the report. The plot below was generated by clicking Show Percents (circled above).
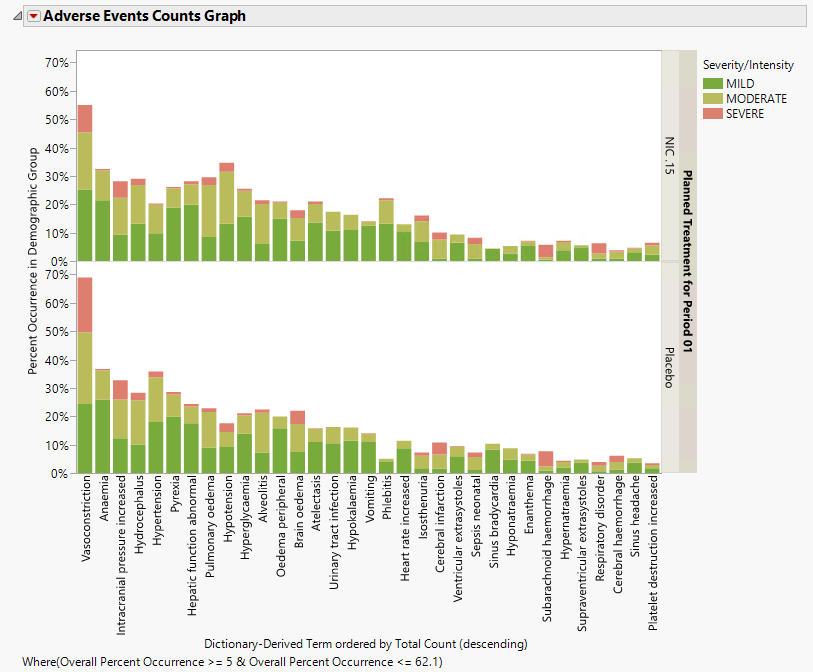
The counts table (shown below) reflects the same counts/percentages as shown in the counts plot in tabular form. The Grouping and Stacking column from the down panel drive the format and detail in this table. This flexibility enables you to create several tables for summarizing events from one report.
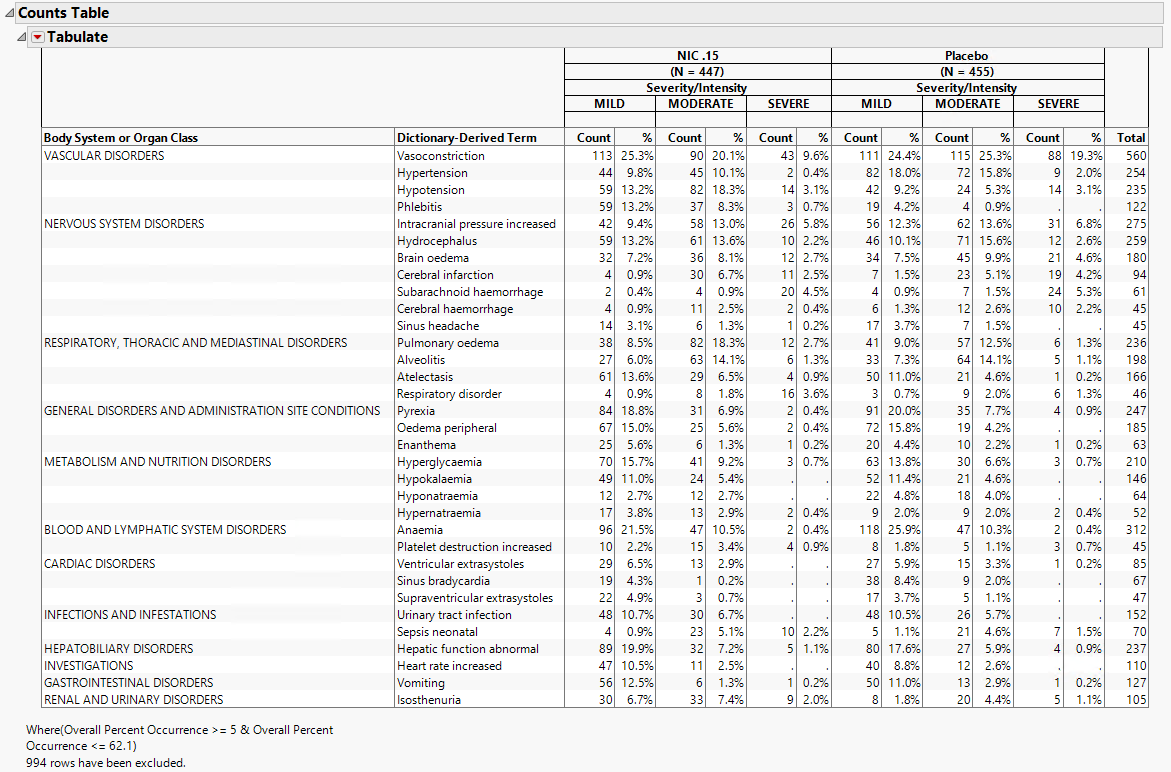
The output STUDY_aed_xx.sas7bdat data set used to generate these plots and tables contains a row for each subject experiencing each event (optionally by treatment period in a crossover scenario).
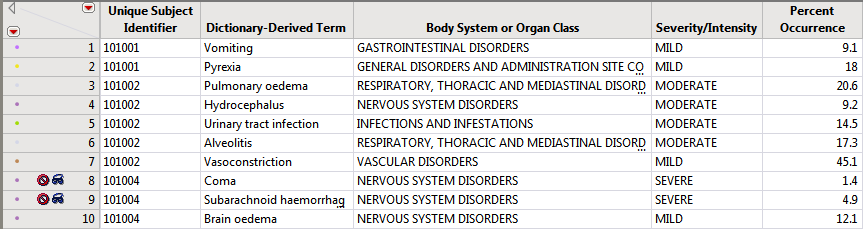
Rows that do not meet the Percent Occurrence Threshold specified on the dialog (5% in this example) are hidden and excluded from analysis. This filter can be interactively changed using the Report Filter option for Percent Occurrence (circled above).
Understanding Count and Percent Calculations
The percent calculations represent the count of subjects in a given demographic group experiencing a given event divided by the count of total subjects in that demographic group.
Algorithms
Count of subjects in demographic group (DMG) with event (AE)

where
Si is the ith subject,
Xi = g(Si. AE, DMG), and
N = Subject number
Note: Xi =1 if the ith subject Si is in the DMG (demographic group) and has an AE value on at least one occasion. If these conditions are not met, Xi has a value of 0.
Count of subjects in demographic group (DMG)

where
Si is the ith subject,
Yi = g(Si. DMG), and
N = Subject number
Note: Yi =1 if the ith subject Si is in the DMG (demographic group). If not, Yi has a value of 0.
Percent of subjects in demographic group (DMG) experiencing event (AE)

These subject percentages are computed dynamically by the JMP Clinical distribution report results and enable you to interactively choose:
| • | The demographic grouping comparison (and therefore reference population for percent calculation) variable to display in the graph and table, and |
| • | The domain-specific variable used to categorize the counts/percents. |
As you change the values of the Grouping and Stacking variables in the report, the structure and percent calculations of the graph and table are automatically updated. See the examples below:
Examples in AE Distribution Using Nicardipine Data (Treatment Emergent Events):
This study has 902 subjects in the safety analysis population with 455 on Placebo, 447 on NIC .15.
Example 1: Using the action buttons on the Output dashboard, select None for Demographic Grouping and None for AE Stacking and examine the Counts Table tab.

560/902 =.621 62.1% of subjects experienced (treatment emergent) vasoconstriction
Example 2: Using the action button on the Output dashboard, select Planned Treatment for Period 1 for Demographic Grouping and None for AE Stacking and examine the Counts Table tab. Note how the values change.

246/447 = .550 55.0% of subjects on NIC .15 experienced vasoconstriction
314/455 = .690 69.0% of subjects on Placebo experienced vasoconstriction
Example 3: Using the action button on the Output dashboard, select Planned Treatment for Period 1 for Demographic Grouping and Severity/Intensity for AE Stacking and examine the Counts Table tab. Note how the values change.

113/447 = 25.3% of subjects on NIC .15 experienced MILD vasoconstriction
90/447 = 20.1% of subjects on NIC .15 experienced MODERATE vasoconstriction
43/447 = 9.6% of subjects on NIC .15 experienced SEVERE vasoconstriction
111/455= 24.4% of subjects on Placebo experienced MILD vasoconstriction
115/455= 25.3% of subjects on Placebo experienced MODERATE vasoconstriction
88/455= 19.3% of subjects on Placebo experienced SEVERE vasoconstriction
Note: In the example, the demographic group column changes the percent calculations (also known as changes the value of the denominator used in the formula), while the stacking/categorization variable just partitions the counts and percentages.
The value of percent calculation comparison can be seen clearly in the two plots shown below. The first plot shows the AE Counts graph grouped by RACE and categorized by Serious Event.
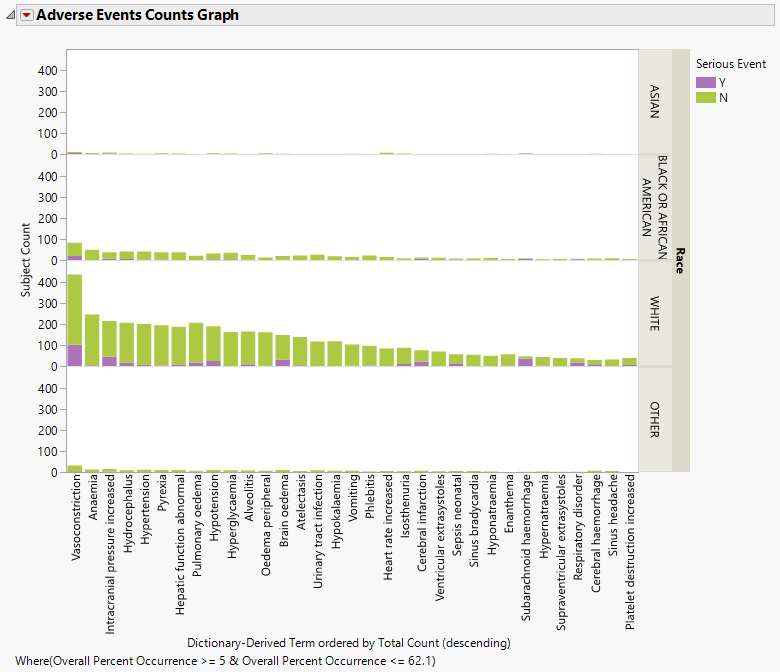
This plot can be misleading because of the large differences in the respective number of subjects in each RACE category. In this case, comparing the percentages might be more informative.
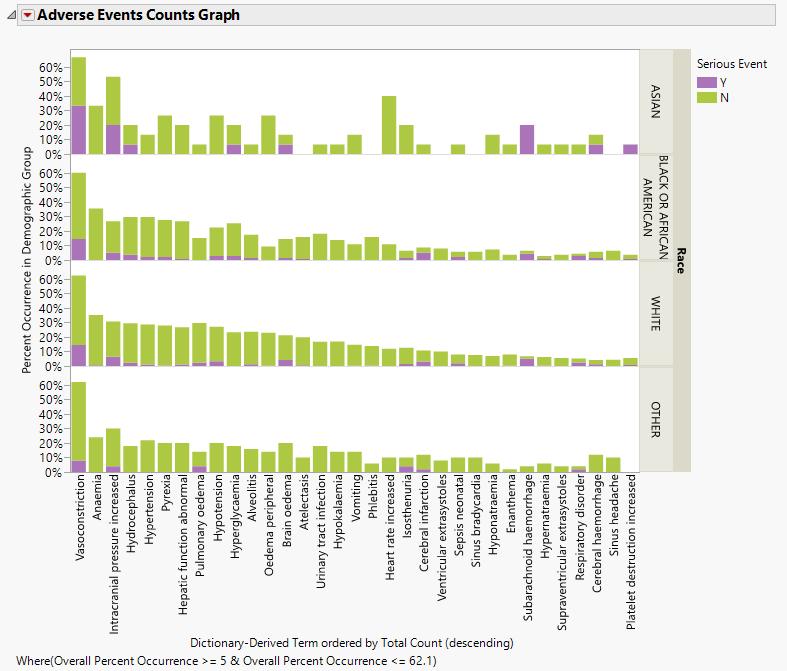
| 8 | Click Show Percents (located above the plot and circled below). |

The resulting plot (below) then is much more useful for making comparisons.
Percent Calculations When an Interactive Data Filter Is Applied.
When you use the Data Filter (located on the right side of the report) to filter the records that are shown, the change does NOT affect the demographic group denominator values that are used in the percent calculations. These denominators, as described previously, are derived in the SAS programming of the analysis based on the analysis population. The counts (the numerator in the percent formula) of subjects experiencing the event (and now meeting the data filter criteria) change values to reflect the use of the data filter.
In the following example, the default (Event Type = All) Adverse Events Distribution report was run for the Nicardipine sample data and the results were subsequently filtered for Serious Event = Y, as shown below:
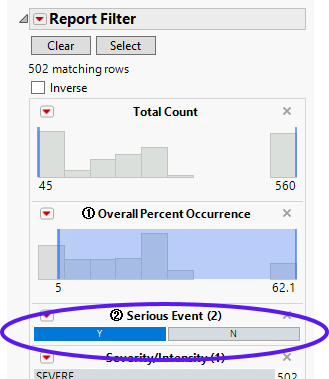
The results are shown below:

88/455 = 19.3% of subjects on Placebo experienced serious vasoconstriction.
If the Data Filter selection is based on a demographic variable, care must be taken to interpret the results.
In the following example, Sex = F has been selected in the data filter:
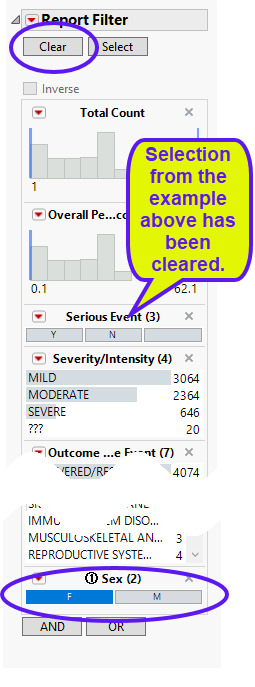
Note: You must click (circled above) to clear out prior filters before making a new selection.
The results are shown below:

206/455 = 45.3% of subjects on Placebo were females with vasoconstriction.
In this example, the 455 subjects on placebo make up the denominator of the percent calculation. The females showing vasoconstriction represent the subject count (or numerator) that had the event subject to any data filter specification (206 female subjects that had vasoconstriction).
Note: If you want to have such demographic filters reflected in the reference population, a pre-specified filter should be used up front, as described below.
Other Distribution Results
All distributions ( Adverse Events Distribution, Events Distribution, Interventions Distribution, and Findings Distribution) also include a set of distributions of relevant results variables in the report.
For the Findings Distribution report, these distributions are the initial view. The findings calculations follow the same workflow as described by the events computation, but are simpler because no percent calculations are performed. Most of the analyses are derived using the JMP reports.
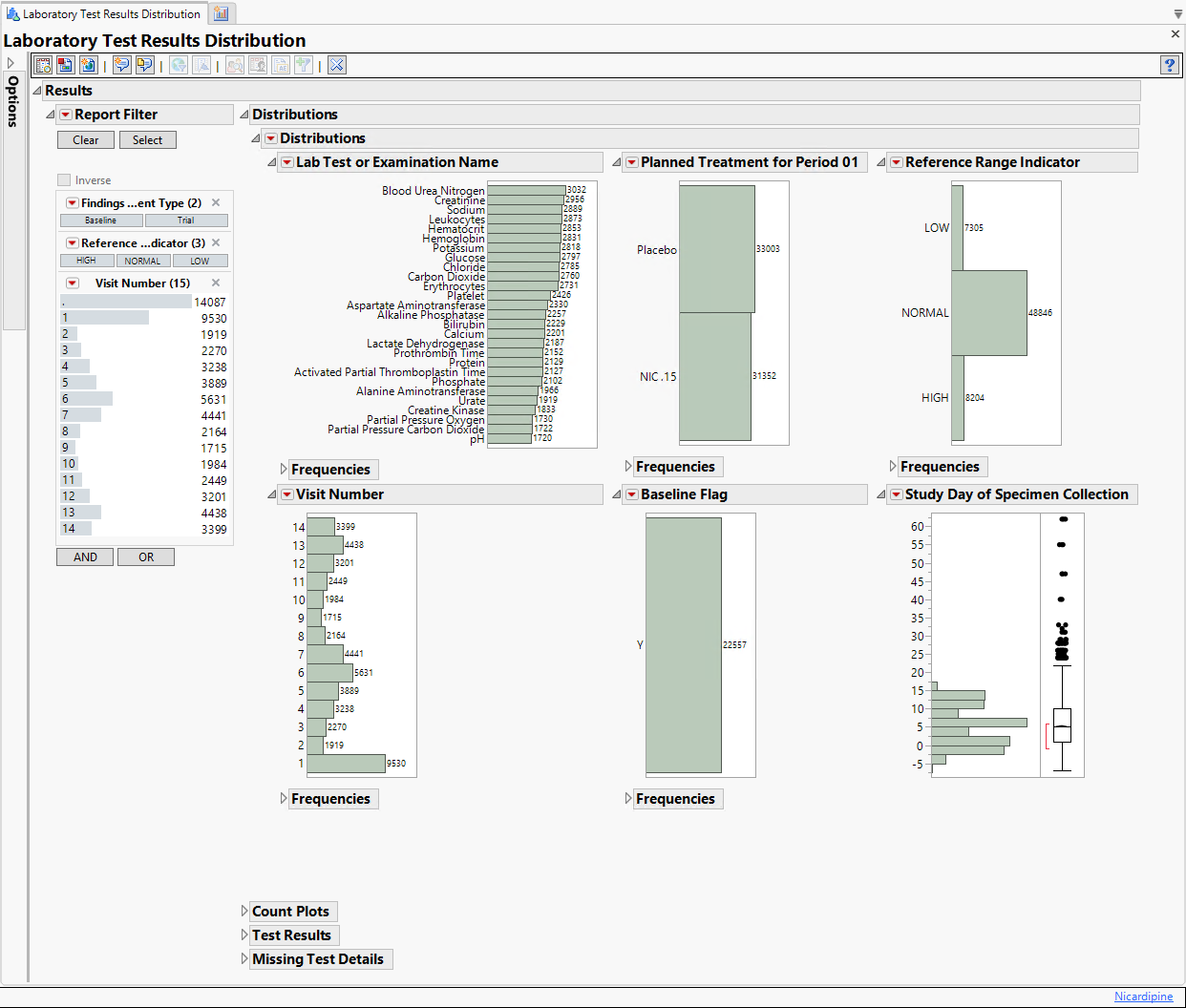
Findings Distributions Results
The Findings Distribution report might contain the following results:
| • | Distributions: Contains distributions of parameters from the specified Findings domain. |
| • | Count Plots: Contains graphs for each test to display measurement counts within categories of the Reference Range Indicator variable. This tab is displayed only if the xxNRIND variable is present in the Findings domain data (typically the LB domain). |
| • | Test Results: Contains One-way Analyses (ANOVA) for each test that has numeric measurement results (xxSTRESN values), Contingency Analyses for each Findings test that has character results (xxSTRESC values but missing xxSTRESN values), or both. |
| • | Missing Test Details: Contains tables displaying subject counts for tests that were either not recorded, or that were recorded but have missing measurement values (of xxSTRESN and/or xxSTRESC). If all subjects had nonmissing recorded test measurements for all tests, this tab is not shown. |
The Distribution tab is shown above. The other three tabs are shown below:
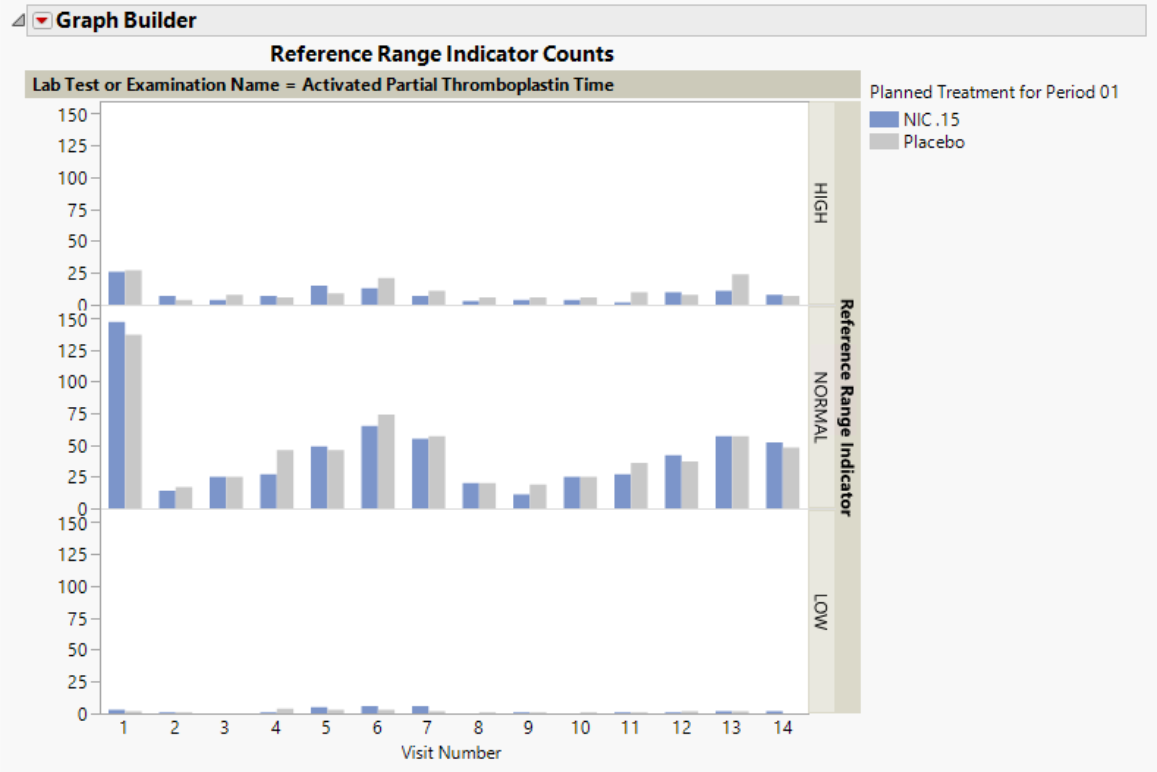
Count Plots: This plot shows counts of records from the Findings domain by Study Visits. The xxNRIND and either the VISIT or VISITNUM variables are required in the domain in order to produce these plots.
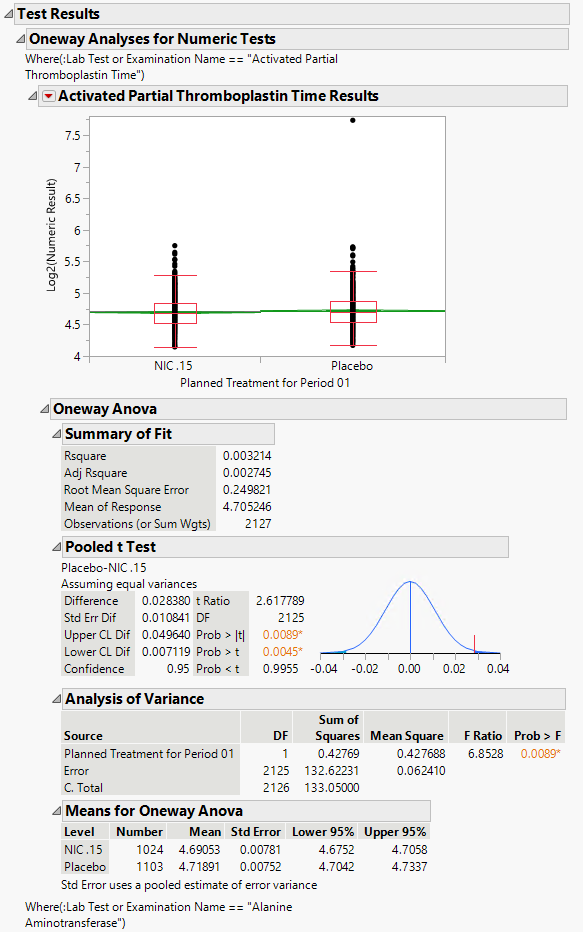
Test Results: This report section displays either an ANOVA (numeric tests) or a Contingency analysis (character findings) comparing findings measurement values across treatment or comparison variable for each test in the domain. In the example setting, there are no character test findings, so the contingency analysis is not shown here.
Missing Test Details; This tab tracks both missing tests and test records that contain missing values.
On this tab, there are possibly two tables that can be reported to track these types of missing test details.
| • | A Missing Tests Table. |
This table displays subject counts for which Findings tests were either not reported or not recorded. For example, the number of subjects for whom no record was taken for the ALT lab test in the LB domain is displayed in this table for the ALT test row.
| • | A Missing Tests Results Table. |
This table displays subject counts for any Findings test was that was recorded, but has a missing measurement value (missing an xxSTRESN value for numeric tests or missing an xxSTRESC for categorical tests). This table differs from the Missing Tests Table in that a record was reported for the test for that subject, but the measurement value was missing.
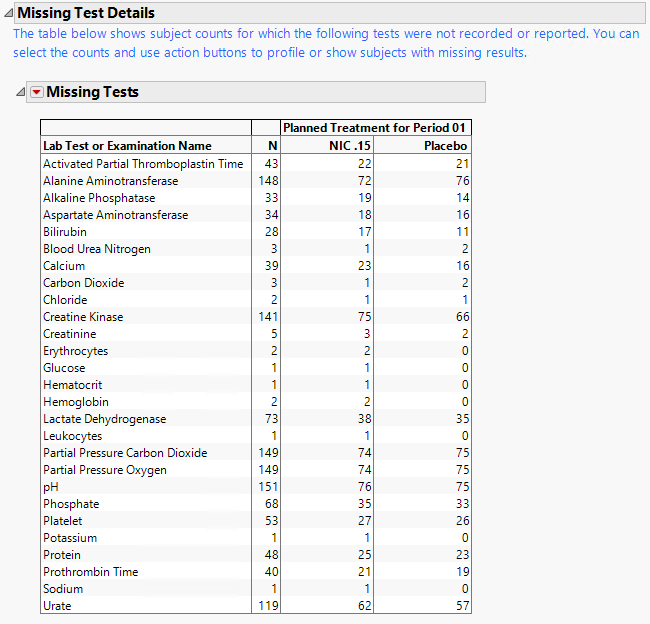
You can select the numbers in these tables and use action buttons to drill down to see profiles or lists of subjects that have missing records or missing measurement values. The Nicardipine results of counts of subjects for whom the tests were not recorded is shown.