Publication date: 07/30/2020
K Means Cluster
Group Observations Using Distances
Use the K Means Cluster platform to group observations that share similar values across a number of variables. Use the k-means method with larger data tables, ranging from approximately 200 to 100,000 observations.
The K Means Cluster platform constructs a specified number of clusters using an iterative algorithm that partitions the observations. The method, called k-means, partitions observations into clusters so as to minimize distances to cluster centroids. You must specify the number of clusters, k, in advance. However, you can compare the results of different values of k to select an optimal number of clusters for your data.
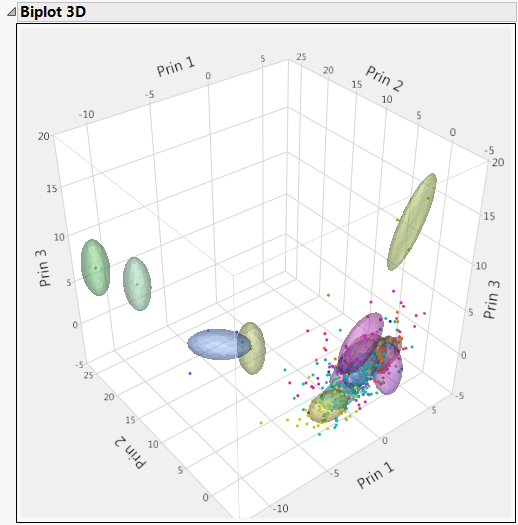
Figure 13.1 3D Biplot
Contents
Overview of the K Means Cluster Platform
Overview of Platforms for Clustering Observations
Example of K Means Cluster
Launch the K Means Cluster Platform
Iterative Clustering Report
Iterative Clustering Options
Iterative Clustering Control Panel
K Means Report
Cluster Comparison Report
K Means Report
K Means Report Options
Self Organizing Map
Self Organizing Map Control Panel
Self Organizing Map Report
Description of SOM Algorithm
Additional Example of K Means Cluster Platform
Example of a Self-Organizing Map
Want more information? Have questions? Get answers in the JMP User Community (community.jmp.com).