Launch the Discriminant Analysis Platform
Launch the Discriminant platform by selecting Analyze > Multivariate Methods > Discriminant.
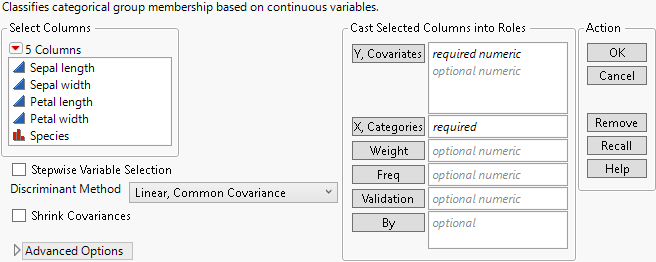
Figure 5.3 Discriminant Launch Window for Iris.jmp
For more information about the options in the Select Columns red triangle menu, see Column Filter Menu in Using JMP.
Note: The Validation button appears in JMP Pro only. In JMP, you can define a validation set using excluded rows. See Validation in JMP and JMP Pro.
Y, Covariates
Columns containing the continuous variables used to classify observations into categories.
X, Categories
A column containing the categories or groups into which observations are to be classified.
Weight
A column whose values assign a weight to each row for the analysis.
Freq
A column whose values assign a frequency to each row for the analysis. In general terms, the effect of a frequency column is to expand the data table, so that any row with integer frequency k is expanded to k rows. You can specify fractional frequencies.
 Validation
Validation
A numeric column containing two or three distinct values:
– If there are two values, the smaller value defines the training set and the larger value defines the validation set.
– If there are three values, these values define the training, validation, and test sets in order of increasing size.
– If there are more than three values, all but the smallest three are ignored.
If you click the Validation button with no columns selected in the Select Columns list, you can add a validation column to your data table. For more information about the Make Validation Column utility, see Make Validation Column in Predictive and Specialized Modeling.
By
Performs a separate analysis for each level of the specified column.
Stepwise Variable Selection
Performs stepwise variable selection using covariance analysis and p-values. See Stepwise Variable Selection.
If you have specified a validation set, statistics that have been calculated for the validation set appear.
Note: This option is not provided for the Wide Linear discriminant method.
Discriminant Method
Provides four methods for conducting discriminant analysis. See Discriminant Methods.
Shrink Covariances
Shrinks the off-diagonal entries of the pooled within-group covariance matrix and the within-group covariance matrices. See Shrink Covariances.
Advanced Options
Contains the following options:
Uncentered Canonical
Suppresses centering of canonical scores for compatibility with older versions of JMP.
Use Pseudoinverses
Uses Moore-Penrose pseudoinverses in the analysis when the covariance matrix is singular. The resulting scores involve all covariates. If left unchecked, the analysis drops covariates that are linear combinations of covariates that precede them in the list of Y, Covariates.
Cross Validate by Excluded Rows
Excluded rows will form a validation set for which statistics of fit are calculated.