 Solution Path
Solution Path
Note: The Solution Path report appears for all Estimation Methods except Maximum Likelihood and all Distributions except Quantile Regression.
The Solution Path report shows two plots:
• The Solution Path Plot displays values of the estimated parameters.
• The Validation Plot displays values of the validation statistic corresponding to the selected validation method.
The horizontal scaling for both plots is given in terms of the Magnitude of Scaled Parameter Estimates. This is the l1 norm, defined as the sum of the absolute values of the scaled parameter estimates for the model for the mean. (Estimates corresponding to the intercept, dispersion parameters, and zero-inflation parameters are excluded from the calculation of the l1 norm.) Note the following:
• Estimates with large values of the l1 norm are close to the MLE.
• Estimates with small values of the l1 norm are heavily penalized.
• The value of the tuning parameter increases as the l1 norm decreases.
 Current Model Indicator
Current Model Indicator
A solid vertical red line is placed in both plots at the value of the l1 norm for the solution displayed in the Parameter Estimates for Original Predictors report. You can drag the arrow at the top of the vertical red line in either plot to change the magnitude of the penalty, indicating a new current model. In the Validation Plot, you can also click anywhere in the plot to change the model. As you drag the vertical red line to indicate a new model, the results in the report update to reflect the currently selected model. A dashed vertical line remains at the best fit model. You can click the Reset Solution button next to the Validation Plot to return the vertical red line and corresponding results to the initial solution. For some validation methods, the Validation Plot provides zones that identify comparable models. See Comparable Model Zones.
Figure 6.5 Solution Path Report for Diabetes.jmp, Lasso with AICc Validation
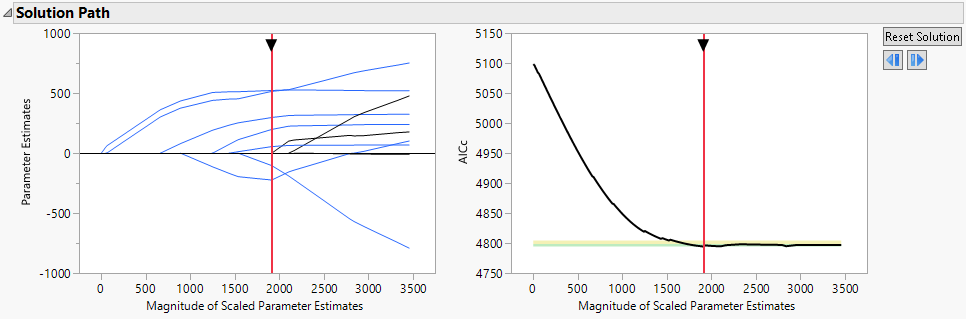
For more information about the Solution Path Plot, see Solution Path Plot. For more information about the Validation Plot, see Validation Plot.
 Solution Path Plot
Solution Path Plot
You can select paths in the Solution Path Plot to highlight the corresponding terms in the Parameter Estimates reports. This action also selects the corresponding columns in the data table. Selecting rows in either of the reports highlights the corresponding rows in the other report and the corresponding paths in the Solution Path Plot. Press Shift and click to select multiple paths or rows.
The Parameter Estimates are plotted using the vertical axis of the Solution Path Plot. These are the scaled parameter estimates. They are derived for a model expressed in terms of centered and scaled predictors (see Parameter Estimates for Centered and Scaled Predictors).
When the number of predictors is less than the number of observations, the Solution Path Plot usually shows the entire range of estimates from zero to the unpenalized fit given by the MLE. Otherwise, the plot extends to a magnitude that is close to the unpenalized solution. This occurs when the jump from the next-to-last grid point to the MLE solution is so large that the detail for solutions up to the next-to-last grid point is obscured. When this happens, as long as the MLE is not the final solution, the Solution Path Plot is rescaled so that the axis extends only to the next-to-last grid point.
 The Solution ID
The Solution ID
Internally, each solution in the Solution Path is assigned a Solution ID. When you adjust the tuning parameter to select a solution other than the one initially presented, the corresponding Solution ID appears in scripts created by the Save Script options. The Solution ID is the value N in the Set Solution ID( N ) command. Saving the Solution ID ensures that you can re-create your selected solution when you run the script.
 Validation Plot
Validation Plot
The Validation Plot shows plots of statistics that describe how well models fit across the values of the tuning parameter, or equivalently, across the values of the Magnitude of the Scaled Parameter Estimates. The statistics plotted depend on the selected Validation Method. For each Validation Method, Table 6.3 lists the statistic that is plotted. For all validation methods, smaller values are better. For the KFold and Leave-One-Out validation methods, and for a Validation Column with more than three values, the statistic that is plotted is the mean of the scaled negative log-likelihood values across the folds.
The Scaled -LogLikelihood in Table 6.3 is the negative log-likelihood divided by the number of observations in the set for which the negative log-likelihood is computed.
Validation Method | Validation Statistic | Tuning Parameter Regions |
|---|---|---|
KFold | Mean of the Scaled -LogLikelihood values across the K folds | Two |
Holdback | Scaled -LogLikelihood | None |
Leave-One-Out | Mean of the Scaled -LogLikelihood values across all folds | Two |
BIC | BIC for training data | Two |
AICc | AICc for training data | Two |
ERIC | ERIC for training data | Two |
Validation Column with two or three values | Scaled -LogLikelihood | None |
Validation Column with K > 3 values | Mean of the Scaled -LogLikelihood values across the K folds | Two |
 Comparable Model Zones
Comparable Model Zones
Although a model is estimated to be the best model, there can be uncertainty relative to this selection. Competing models might fit nearly as well and can contain useful information. For the AICc, BIC, KFold, and Leave-One-Out validation methods, and for a Validation Column with more than three values, the Validation Plot provides zones that identify competing models that might deserve consideration. Models that fall outside the zones are not recommended. See Burnham and Anderson (2004) and Burnham et al. (2011).
A zone is an interval of values of the validation statistics. The zones are plotted as green or yellow rectangles that span the entire horizontal axis. A model falls in a zone if the value of its validation statistic falls in the zone. You can drag the solid vertical red line to explore solutions within the zones. See Current Model Indicator.
Figure 6.6 shows a Validation Plot for Diabetes.jmp with the vertical axis expanded to show the two zones.
Figure 6.6 Validation Plot for Diabetes.jmp, Lasso with AICc Validation
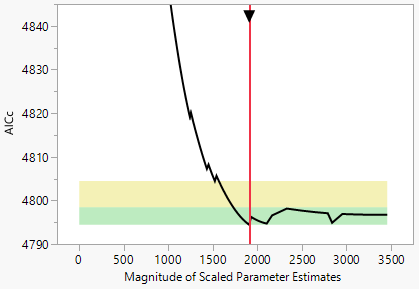
Zones for BIC, AICc, and ERIC Validation
For these validation methods, two regions are shown in the plot. Denote the validation BIC, AICc, and ERIC values for the best solutions by Vbest.
• The green zone identifies models for which there is strong evidence that a model is comparable to the best model. The green zone is the interval [Vbest, Vbest+4].
• The yellow zone identifies models for which there is weak evidence that a model is comparable to the best model. The yellow zone is the interval (Vbest+4, Vbest+10].
Zones for KFold Validation, Leave-One-Out Validation, and Validation Column with More Than Three Values
For these validation methods, two regions are shown in the plot. At the solution for the best model, the scaled negative log-likelihood functions are evaluated for each validation set. Denote the standard error of these values as LSE. Denote the scaled negative log-likelihood for the best solution by Lbest.
• The green zone identifies models for which there is strong evidence that a model is comparable to the best model. The green zone is the interval [Lbest, Lbest+LSE].
• The yellow zone identifies models for which there is weak evidence that a model is comparable to the best model. The yellow zone is the interval (Lbest+LSE, Lbest+2.5*LSE].