Canonical Plot and Canonical Structure
The Canonical Plot is a biplot that describes the canonical correlation structure of the variables.
Canonical Structure
Each of the levels of the X, Categories column defines an indicator variable. A canonical correlation is performed between the set of indicator variables representing the categories and the covariates. Linear combinations of the covariates, called canonical variables, are derived. These canonical variables attempt to summarize the between-category variation.
The first canonical variable is the linear combination of the covariates that maximizes the multiple correlation between the category indicator variables and the covariates. The second canonical variable is a linear combination uncorrelated with the first canonical variable that maximizes the multiples correlation with the categories. If the X, Categories column has k levels, then k - 1 canonical variables are obtained.
Canonical Plot
Figure 5.9 shows the Canonical Plot for a linear discriminant analysis of the data table Iris.jmp. The points have been colored by Species.
Figure 5.9 Canonical Plot for Iris.jmp
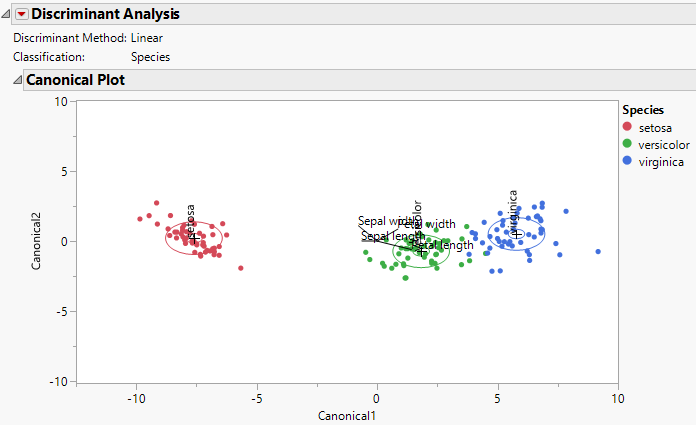
The biplot axes are the first two canonical variables. These define the two dimensions that provide maximum separation among the groups. Each canonical variable is a linear combination of the covariates. (See Canonical Structure.) The biplot shows how each observation is represented in terms of canonical variables and how each covariate contributes to the canonical variables.
• The observations and the multivariate means of each group are represented as points on the biplot. They are expressed in terms of the first two canonical variables.
– The point corresponding to each multivariate mean is denoted by a plus (“+”) marker.
– A 95% confidence level ellipse is plotted for each mean. If two groups differ significantly, the confidence ellipses tend not to intersect.
– An ellipse denoting a 50% contour is plotted for each group. This depicts a region in the space of the first two canonical variables that contains approximately 50% of the observations, assuming normality.
• The set of rays that appears in the plot represents the covariates.
– For each canonical variable, the coefficients of the covariates in the linear combination can be interpreted as weights.
– To facilitate comparisons among the weights, the covariates are standardized so that each has mean 0 and standard deviation 1. The coefficients for the standardized covariates are called the canonical weights. The larger the canonical weight of a covariate, the greater its association with the canonical variable.
– The length and direction of each ray in the biplot indicates the degree of association of the corresponding covariate with the first two canonical variables. The length of the rays is a multiple of the canonical weights.
– The rays emanate from the point (0,0), which represents the grand mean of the data in terms of the canonical variables.
– You can obtain the values of the weight coefficients by selecting Canonical Options > Show Canonical Details from the Discriminant Analysis red triangle menu. At the bottom of the Canonical Details report, click Standardized Scoring Coefficients. See Standardized Scoring Coefficients.
Modifying the Canonical Plot
Additional options enable you to modify the biplot:
• Show or hide the 95% confidence ellipses by selecting Canonical Options > Show Means CL Ellipses from the Discriminant Analysis red triangle menu.
• Show or hide the rays by selecting Canonical Options > Show Biplot Rays from the Discriminant Analysis red triangle menu.
• Drag the center of the biplot rays to other places in the graph. Specify their position and scaling by selecting Canonical Options > Biplot Ray Position from the Discriminant Analysis red triangle menu. The default Radius Scaling shown in the Canonical Plot is 1.5, unless an adjustment is needed to make the rays visible.
• Show or hide the 50% contours by selecting Canonical Options > Show Normal 50% Contours from the Discriminant Analysis red triangle menu.
• Color code the points to match the ellipses by selecting Canonical Options > Color Points from the Discriminant Analysis red triangle menu.
Classification into Three or More Categories
For the Iris.jmp data, there are three Species, so there are only two canonical variables. The plot in Figure 5.9 shows good separation of the three groups using the two canonical variables.
The rays in the plot indicate the following:
• Petal length is positively associated with Canonical1 and negatively associated with Canonical2. It carries more weight in defining Canonical1 than Canonical2.
• Petal width is positively associated with both Canonical1 and Canonical2. It carries about the same weight in defining both canonical variates.
• Sepal width is negatively associated with Canonical1 and positively associated with Canonical2. It carries more weight in defining Canonical2 than Canonical1.
• Sepal length is negatively weighted in terms of defining Canonical1 and very weakly associated in defining Canonical2.
Classification into Two Categories
When the classification variable has only two levels, the points are plotted against the single canonical variable, denoted by Canonical1 in the plot. The canonical weights for each covariate relate to Canonical1 only. The rays are shown with a vertical component only in order to separate them. Project the rays onto the Canonical1 axis to compare their relative association with the single canonical variable.
Figure 5.10 shows a Canonical Plot for the sample data table Fitness.jmp. The seven continuous variates are used to classify an individual into the categories M (male) or F (female). Since the classification variable has only two categories, there is only one canonical variable.
Figure 5.10 Canonical Plot for Fitness.jmp
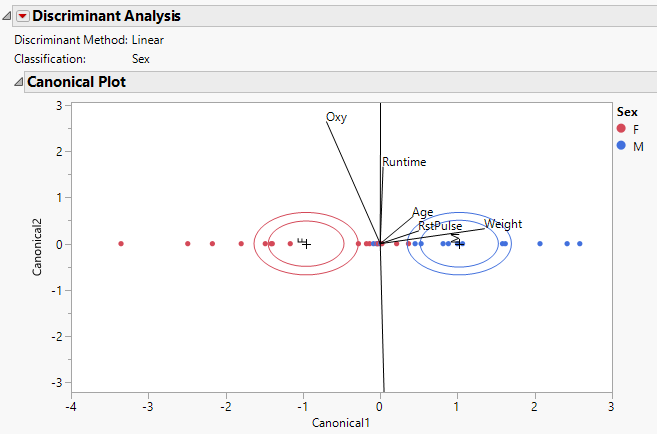
The points in the Canonical Plot have been colored by Sex. Note that the two groups are well separated by their values on Canonical1.
Although the rays corresponding to the seven covariates have a vertical component, in this case you must interpret the rays only in terms of their projection onto the Canonical1 axis. You note the following:
• MaxPulse, Runtime, and RunPulse have little association with Canonical1.
• Weight, RstPulse, and Age are positively associated with Canonical1. Weight has the highest degree of association. The covariates RstPulse and Age have a similar, but smaller, degree of association.
• Oxy is negatively associated with Canonical1.