 Launch the Functional Data Explorer Platform
Launch the Functional Data Explorer Platform
Launch the Functional Data Explorer platform by selecting Analyze > Specialized Modeling > Functional Data Explorer.
Figure 15.5 Functional Data Explorer Launch Window
For more information about the options in the Select Columns red triangle menu, see Column Filter Menu in Using JMP.
The Launch Window includes tabs for three different types of data formats.
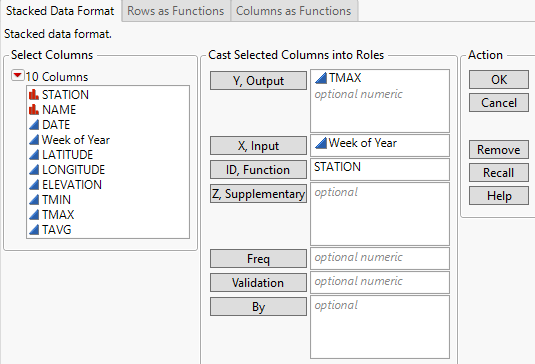
Stacked Data Format
In this data format, each row corresponds to a single observation. There are separate columns for the output, input, and ID variables.
Note: The Stacked Data Format is the only data format that enables you to specify multiple functional processes. If you assign more than one column to Y, Output in the Stacked Data Format tab, each Y variable is analyzed separately. A Fit Group report contains the individual reports for the Y variables.
Rows as Functions
In this data format, each row corresponds to the full output function for one level of the ID variable. Each column is a level of the input variable.
Caution: The Rows as Functions format assumes that your observations are equally spaced in the input domain unless the FDE X column property is used. The FDE X column property enables this data format to use input variables specified in the column names.
Columns as Functions
In this data format, each column corresponds to the entire output function for one level of the ID variable. Each row corresponds to a level of the input variable.
 Launch Window Options
Launch Window Options
Y, Output
Assigns the functional process, f(t). There must be at least two observed output values for each level of the ID variable.
X, Input
(Available for Stacked Data Format and Columns as Functions.) Assigns the input variable t. If no variable is specified for X, Input, the row number is used instead. Using the row number assumes that the observations are equally spaced in the input domain.
ID, Function
(Available for Stacked Data Format and Rows as Functions.) Assigns the ID variable to each function. If no ID variable is assigned in the Stacked Data Format tab, all observations are assumed to come from only one function.
Z, Supplementary
(Available for Stacked Data Format and Rows as Functions.) Assigns one or more supplementary variables. Supplementary variables are not used in any of the calculations in the Functional Data Explorer platform and including them does not affect the results. Supplementary variables are variables you might want to use in future analyses of the results from Functional Data Explorer. When you specify supplementary variables, they are included in a Supplementary column group in the tables that are created by the Save Data and Save Summaries options. These columns retain any column properties that were specified in the original data table.
Freq
(Available only for Stacked Data Format.) Assigns a column whose numeric values represent a frequency for each row in the analysis. The effect of a frequency column is to expand the data table, so that any row with integer frequency k is expanded to k identical rows.
Validation
Assigns an optional numeric column containing two distinct values. The smaller value defines the training set and the larger value defines the validation set. If there are more than two values, the smallest value defines the training set and all other values define the validation set.
Note: The Validation option enables you to hold out complete functions, not a sample of observations from each function. Therefore, all observations that have the same ID value must be classified as either test or validation. You cannot have observations with the same ID value in both sets. For more information about this type of validation column, see Grouped Validation Column in the Make Validation Column section.
If you click the Validation button with no columns selected in the Select Columns list, you can add a validation column to your data table. For more information about the Make Validation Column utility, see Make Validation Column.
By
Assigns a column that creates a report consisting of separate analyses for each level of the variable. If more than one By variable is assigned, a separate analysis is produced for each possible combination of the levels of the By variables.