Mixture
The Fit Mixture option adds the Mixture outline to the report where you can fit a mixture distribution to the data. For an example, see Fit Mixture Example.
The mixture distribution's probability function F(x) is defined as follows:
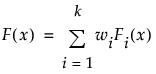
where Fi(x) is one of the supported distributions, k is the number of components in the mixture, and the wi are positive weights that sum to 1. The Fit Mixture option attempts to identify clusters of observations that are drawn from each of the component distributions, Fi(x). It estimates the parameters of the mixture and the probability that an observation is drawn from any given component.
Model Fit and Mixture Starting Value Methods
The fitting methodology is based on assumptions about the underlying clusters, called the Starting Value Method. Suppose that you designate k distributions. There are three Starting Value Methods:
• Single Cluster assumes that all observations are affected by all of the ingredient distributions to some extent. None of the densities stand out as affecting only a portion of the observations.
• Separable Clusters assumes that the ingredient distributions affect some observations more profoundly than others. For separable clusters, each of the k densities has an identifiable mode and defines a cluster.
• Overlapping Clusters assumes a situation that is intermediate between Single Cluster and Separable Clusters. Some densities stand out, but others jointly affect a portion of the observations. In this case, there are m clusters in the data, where m is less than k, the total number of densities.
The fitting process consists of these steps:
1. Clusters of observations are defined.
2. Assignment of clusters to densities is based on the Starting Value Method:
– For Separable Clusters, the highest likelihood assignment of clusters to the specified ingredient densities is determined by examining the possible permutations.
– For Overlapping Clusters, the highest likelihood assignment of clusters to the specified ingredient densities is determined by examining the possible permutations of clusters and combinations of observations.
Note: Suppose that you fit a model using a given Starting Value Method and then select another Starting Value Method. If a better fit based on the likelihood value cannot be achieved, no new model is added.
Mixture Control Panel
The control panel consists of these items:
Ingredient
Lists distributions that you can use as components of the fitted mixture distribution.
Quantity
Select the number of components in the mixture distribution that have the given distribution. The sum of the Quantity values is k, the number of densities in the mixture.
Starting Value Methods
Select a method that reflects your assumptions about the mixture. See Model Fit and Mixture Starting Value Methods.
Overlay
Shows the nonparametric estimates (Kaplan-Meier-Turnbull) for the uncensored data values. When you fit a mixture, the plot is updated to show the model and 95% level confidence bands. The confidence bands are not affected by the selection of Change Confidence Level in the Life Distribution red triangle menu. A Legend appears to the right of the plot.
Go
Click Go to fit the desired mixture. The Model List is updated with the model that you fit, and a report with the name of the mixture model is added.
Fit Mixture Reports
Model List
The Model List report lists the mixture distributions that you fit. The report provides the number of parameters, the number of actual observations, and the AICc, -2Loglikelihood, and BIC statistics for each mixture distribution. For more information about these statistics, see Likelihood, AICc, and BIC in Fitting Linear Models.
Note the following:
• Smaller values of each of these statistics indicate a better fit.
• The rows are sorted by AICc.
• The Comparison Criterion red triangle option does not affect the order of models in the Model List.
• The AICc, -2Loglikelihood, and BIC statistics also appear in the Model Comparisons table. This enables you to compare mixture distribution to other distributions for your data. See Model Comparisons.
Mixture Reports
The Model List report is followed by reports for each of the mixture distributions that you have fit. The title of each report describes the corresponding mixture using the specified ingredients and their quantities. The report lists the parameters, their estimates, standard errors, and 95% Wald confidence intervals. These intervals are not affected by the selection of Likelihood as the Confidence Interval Method in the launch window.
Parameter estimates are given for each distribution in the mixture. The Parameter column also includes parameters called Portion <i>, where i = 1, 2,..., k-1. These are estimates of the weights wi for the mixture. Since the weights sum to 1, the kth weight can be computed from the first k - 1 weights.
Density Overlay Plot
The Density Overlay plot shows estimates of the density functions for each of the components in the mixture. A legend to the right of the plot enables you to select which density functions appear.
Mixture Report Options
The red triangle menu contains the following options:
Remove
Removes the model report and the entry for the model in the Model List.
Show Profilers
Shows four types of profilers for the combined mixture distribution F. See Mixture Profiler Options for a description of their red triangle options.
– The Distribution Profiler shows cumulative failure probability as a function of time.
– The Quantile Profiler shows failure time as a function of cumulative probability.
– The Hazard Profiler shows the hazard rate as a function of time.
– The Density Profiler shows the density function for the distribution.
Save Predictions
For each mixture density, saves a column to the data table containing the probability that an observation belongs to that density. For the formulas used in the calculation, see Fit Mixture Save Predictions Formulas.
Mixture Profiler Options
The profilers for each mixture report contain the following red triangle options:
Confidence Intervals
The Distribution, Quantile, and Hazard profilers show 95% Wald-based confidence curves for the plotted functions. This option shows or hides the confidence curves. The confidence level is not affected when you select Change Confidence Level from the Life Distribution red triangle menu.
Note: To reduce computation time, the confidence intervals provided in the profilers are based on the Wald method, even if the Likelihood Confidence Interval Method is selected in the launch window.
Reset Factor Grid
Displays a window for each factor enabling you to enter a specific value for the factor’s current setting, to lock that setting, and to control aspects of the grid. See Reset Factor Grid in Profilers.
Factor Settings
Provides a menu that consists of options relating to profiler settings, scripts, and linking profilers. See Factor Settings in Profilers.