Les nuages de points et autres graphiques de ce genre peuvent vous aider à visualiser les relations entre les variables. Une fois les relations visualisées, l’étape suivante consiste à les analyser afin de les décrire numériquement. Cette description numérique de la relation entre les variables est qualifiée de modèle. Plus important encore, un modèle prévoit également la valeur moyenne d’une variable (Y) d’après la valeur d’une autre variable (X). La variable X est aussi appelée régresseur. On parle généralement de modèle de régression.
Les plates-formes Ajuster Y en fonction de X et Modèle linéaire de JMP permettent de créer des modèles de régression.
Remarque : Seules les principales plates-formes et options sont traitées ici. Pour plus d'informations sur l'ensemble des options des plates-formes, voir Basic Analysis, Essential Graphing et la documentation répertoriée dans À propos de ce chapitre.
Le Tableau 5.3 Types de relation présente les quatre principaux types de relations.
|
La régression logistique est un sujet plus poussé. Voir le chapitre Logistic Analysis dans Basic Analysis.
|
Cet exemple s'appuie sur la table de données Companies.jmp, qui contient des données financières sur 32 sociétés des industries pharmaceutique et informatique.
Tout d’abord, créez un nuage de points pour visualiser la relation entre le nombre d’employés et le chiffre d'affaires. Ce nuage de points a été créé au paragraphe “Create the Scatterplot” on page 102 in the “Visualize Your Data” chapter. La Figure 5.12 Nuage de points de Sales ($M) par rapport à # Employ illustre les résultats obtenus après masquage et exclusion d'une valeur aberrante (une société avec un effectif et un chiffre d'affaires très importants).
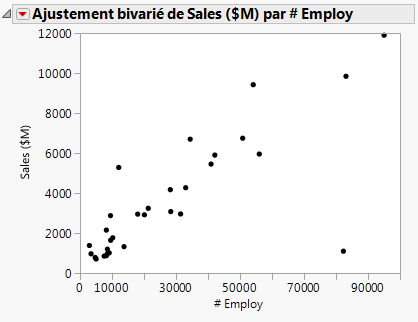
Pour prévoir un chiffre d'affaires d'après un nombre d’employés, vous devez ajuster un modèle de régression. Cliquez sur le triangle rouge Ajustement bivarié et sélectionnez Régression simple. Une droite de régression est ajoutée dans le nuage de points et des rapports sont ajoutés dans la fenêtre de rapport.
Figure 5.13 Droite de régression

|
•
|
la p-value <0.0001
|
|
•
|
La p-value du terme du modèle #Employ est petite. Cela permet d'établir qu'au niveau de significativité de 0,05 le coefficient est différent de zéro pour #Employ. Par conséquent, en incluant le nombre d’employés dans le modèle de prévision, il est possible d'augmenter de façon significative la capacité de prévision du chiffre d'affaires moyen en comparaison avec un modèle n'incluant pas le nombre d'employés.
|
|
2.
|
|
3.
|
Figure 5.14 Comparer les modèles

Les résultats de la Figure 5.14 Comparer les modèles permettent à l’analyste de tirer les conclusions suivantes :
Cet exemple s'appuie sur la table de données Companies.jmp, qui contient des données financières sur 32 sociétés des industries pharmaceutique et informatique.
|
1.
|
|
2.
|
Si la table d’échantillons de données Companies.jmp est toujours ouverte, il est possible que des lignes soient exclues ou masquées. Pour réinitialiser l'état de ces lignes — c'est-à-dire pour les inclure et les afficher toutes — choisissez Lignes > Effacer les états de ligne.
|
|
3.
|
|
4.
|
|
5.
|
|
6.
|
Cliquez sur OK.
|
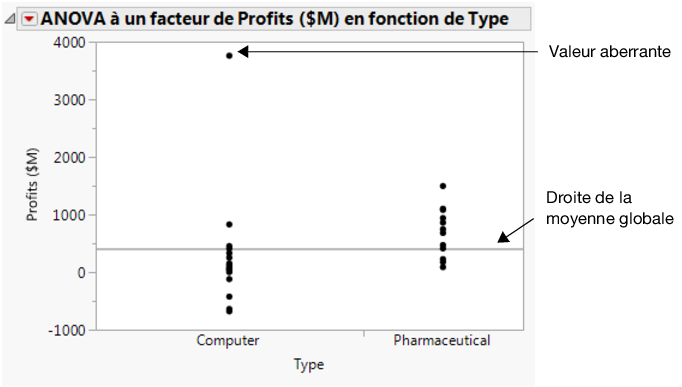
Figure 5.15 Bénéfices par type de société
|
2.
|
|
3.
|
|
4.
|
Pour recréer le graphique sans la valeur aberrante, cliquez sur ANOVA à un facteur de Profits ($M) en fonction de Type et sélectionnez Refaire > Refaire l'analyse. Vous pouvez fermer la fenêtre Nuage de points initiale.
|
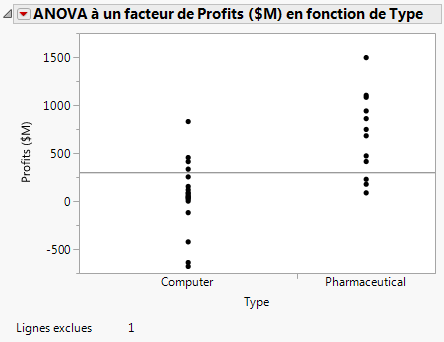
Figure 5.16 Graphique mis à jour
|
–
|
Options d’affichage > Droites des moyennes. (Pour ajouter les droites des moyennes dans le nuage de points.)
|
|
–
|
Moyennes et écarts-types. (Pour afficher un rapport sur les moyennes et les écarts-types.)
|
Figure 5.17 Droites des moyennes et rapport
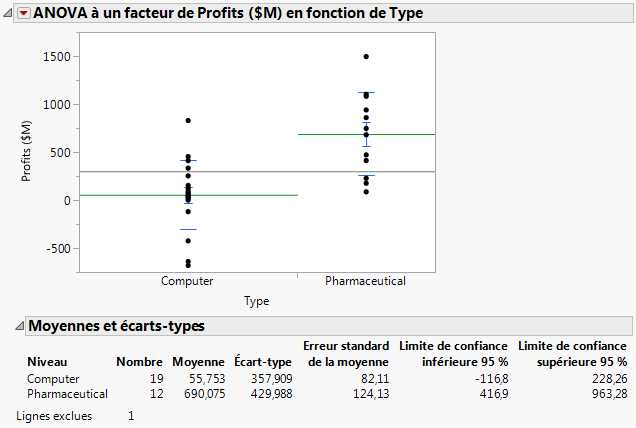
Pour répondre à ces questions, effectuez un test de Student sur deux échantillons. Un test de Student vous permet d'utiliser les données d'un échantillon pour tirer des conclusions sur une population plus vaste (dite « générale » ici).
Pour réaliser le test de Student, cliquez sur le triangle rouge ANOVA à un facteur et sélectionnez Moyennes/ANOVA/t groupé.
Figure 5.18 Résultats du test de Student

La p-value 0,0001 est inférieure au niveau de significativité de 0,05, ce qui indique la significativité statistique. Par conséquent, l’analyste financier peut conclure que la différence entre les bénéfices moyens de l'échantillon de données n'est pas due au hasard. Au sein de la population générale, les bénéfices moyens des sociétés pharmaceutiques sont bien différents de ceux des sociétés informatiques.
Utilisez les limites de l’intervalle de confiance pour définir précisément la différence de bénéfices entre les deux types de société. Examinez les valeurs Limite de confiance supérieure (95 %) de la différence et Limite de confiance inférieure (95 %) de la différence de la Figure 5.18 Résultats du test de Student. L'analyste financier conclut que le bénéfice moyen des laboratoires pharmaceutiques est supérieur de 343 à 926 millions de dollars à celui des sociétés informatiques.
Si les variables X et Y sont catégorielles, vous pouvez comparer les proportions des niveaux de la variable Y avec celles des niveaux de la variable X.
Cet exemple utilise également la table de données Companies.jmp. Au paragraphe Comparer les moyennes d'une variable, l'analyste financier a pu établir que les laboratoires pharmaceutiques affichaient, en moyenne, des bénéfices supérieurs à ceux des sociétés informatiques.
|
1.
|
|
2.
|
Si la table d’échantillons de données Companies.jmp est toujours ouverte, il est possible que des lignes soient exclues ou masquées. Pour réinitialiser l'état de ces lignes — c'est-à-dire pour les inclure et les afficher toutes — choisissez Lignes > Effacer les états de ligne.
|
|
3.
|
|
4.
|
|
5.
|
|
6.
|
Cliquez sur OK.
|
Figure 5.19 Taille des sociétés en fonction de leur type

Le tableau de contingence contient des informations qui ne s'appliquent pas à cet exemple. Cliquez sur le triangle rouge Tableau de contingence et désélectionnez % du total et % de colonnes pour retirer ces informations. La Figure 5.20 Tableau de contingence mis à jour affiche le tableau actualisé.
Figure 5.20 Tableau de contingence mis à jour
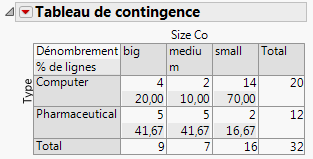
Pour répondre à cette question, utilisez la p-value du test de Pearson disponible dans le rapport Tests (Taille des sociétés en fonction de leur type). Puisque la p-value 0,011 est inférieure au niveau de significativité de 0,05, l’analyste financier conclut que :
Le paragraphe Comparer les moyennes d'une variable a permis de comparer les moyennes entre les différents niveaux d’une variable catégorielle. Pour comparer les moyennes entre les niveaux de deux variables ou plus, utilisez l’analyse de la variance (ou ANOVA).
|
•
|
Type (pharmaceutique ou informatique)
|
|
•
|
Taille (petite, moyenne, grande)
|
|
1.
|
|
2.
|
|
3.
|
|
4.
|
|
5.
|
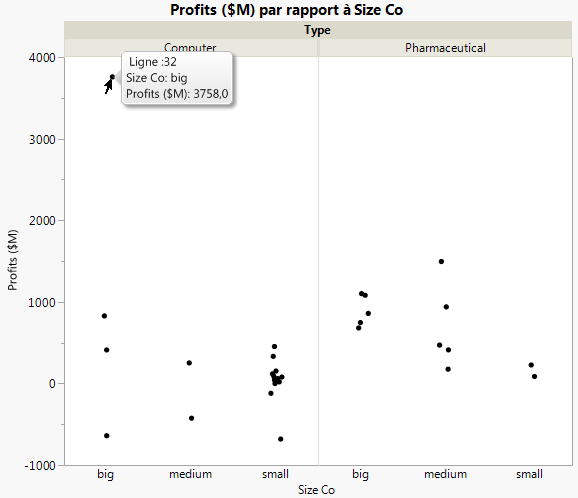
Figure 5.21 Graphique des bénéfices des sociétés
|
6.
|
Sélectionnez la valeur aberrante, puis cliquez avec le bouton droit et sélectionnez Lignes > Exclusion de lignes. Le point est supprimé et l’échelle du graphique est automatiquement modifiée.
|
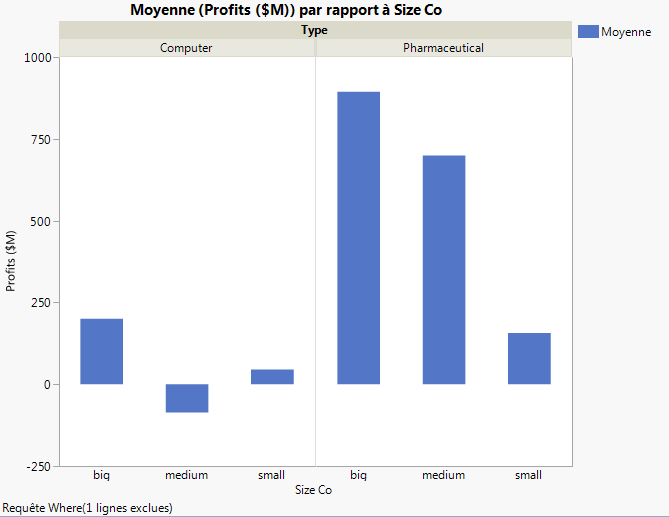
Figure 5.22 Graphique sans la valeur aberrante
|
1.
|
Retournez dans la table d’échantillons de données Companies.jmp dont un point est exclu. Voir Découvrir la relation.
|
|
2.
|
|
3.
|
|
4.
|
|
5.
|
|
6.
|
|
7.
|
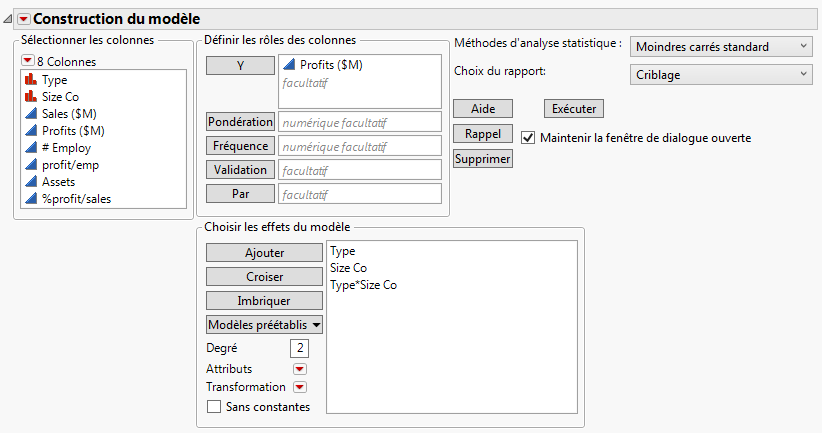
Sélectionnez l’option Maintenir la fenêtre de dialogue ouverte.
|
Figure 5.23 Fenêtre Modèle linéaire renseignée
|
8.
|
Cliquez sur Exécuter. La fenêtre de rapport affiche les résultats du modèle.
|
Pour savoir si les différences de bénéfices sont réelles ou le fruit du hasard, consultez le rapport Tests des effets.
Remarque : Pour plus d'informations sur tous les résultats du Modèle linéaire, voir le chapitre Model Specification dans Fitting Linear Models.
Le rapport Tests des effets (Figure 5.24 Rapport Tests des effets) fournit les résultats des tests statistiques. Un test a été effectué pour chaque effet du modèle de la fenêtre Modèle linéaire : Type, Size Co et Type*Size Co.
Figure 5.24 Rapport Tests des effets

Tout d’abord, examinez le test d'interaction du modèle : l'effet Type*Size Co. La Figure 5.22 Graphique sans la valeur aberrante indiquait que les laboratoires pharmaceutiques semblaient afficher des bénéfices différents selon leur taille. Cependant, le test des effets signale qu’il n’existe aucune interaction entre le type et la taille pour ce qui est des bénéfices. La p-value 0,218 est élevée (supérieure au niveau de significativité de 0,05). Par conséquent, supprimez cet effet et réexécutez le modèle.
|
2.
|
|
3.
|
Cliquez sur Exécuter.
|
Figure 5.25 Rapport Tests des effets mis à jour

La p-value de l’effet Size Co est élevée, ce qui signifie qu'il n'existe aucune différence basée sur la taille au sein de la population générale. La p-value de l’effet Type est petite, ce qui signifie que les différences observées dans les données entre les sociétés informatiques et pharmaceutiques ne sont pas le fait du hasard.
Dans le paragraphe Utiliser la régression avec un régresseur, vous avez appris à créer des modèles de régression simples, composés d’une variable de régression et d’une variable de réponse. La régression multiple permet de prévoir la variable de réponse moyenne à l’aide de deux variables de régression ou plus.
Cet exemple s'appuie sur la table de données Candy Bars.jmp, qui contient les informations nutritionnelles de barres chocolatées.
|
•
|
Utilisez la régression multiple pour prévoir la variable de réponse moyenne à l’aide de ces trois variables de régression.
|
1.
|
|
2.
|
|
3.
|
|
4.
|
|
5.
|
Cliquez sur OK.
|
Figure 5.26 Résultats de la matrice de nuages de points
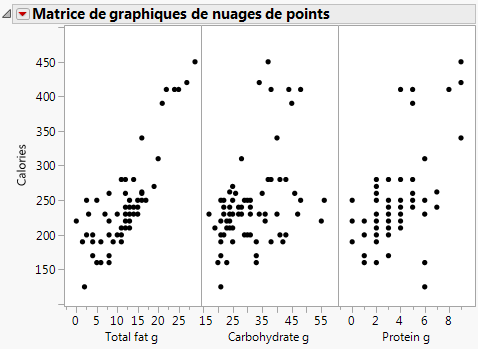
|
1.
|
|
2.
|
|
3.
|
|
4.
|
Dans le menu Choix du rapport, sélectionnez Criblage de l’effet.
|
Figure 5.27 Fenêtre Modèle linéaire
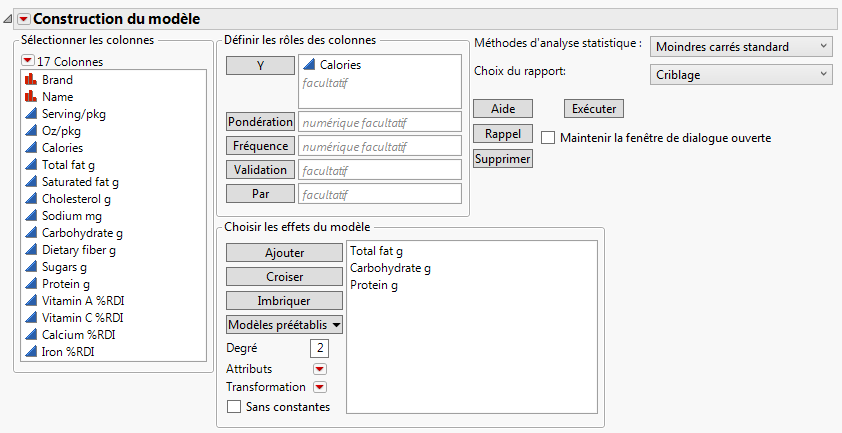
|
5.
|
Cliquez sur Exécuter.
|
Remarque : Pour plus d'informations sur tous les résultats du modèle, voir le chapitre Model Specification dans Fitting Linear Models.
Le graphique des valeurs observées en fonction des valeurs prévues affiche les calories réelles par rapport aux calories prévues. Comme les valeurs prévues sont proches des valeurs observées, les points du nuage tombent à proximité de la droite rouge (Figure 5.28 Graphique des valeurs observées en fonction des valeurs prévues). Les points étant tous très proches de la droite, vous pouvez en conclure que le modèle prévoit correctement les calories en fonction des facteurs choisis.
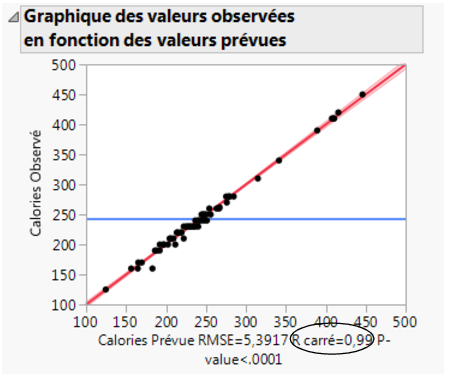
Vous pouvez également mesurer la précision du modèle par la valeur R carré (située sous le graphique dans la Figure 5.28 Graphique des valeurs observées en fonction des valeurs prévues). Elle mesure le pourcentage de variabilité des calories, comme expliqué par le modèle. Une valeur proche de 1 signifie que la prévision du modèle est correcte. Dans cet exemple, la valeur de R carré est de 0,99.
|
•
|
La p-value de chaque paramètre
|
Figure 5.29 Rapport Estimation des paramètres

Dans cet exemple, les p-values sont toutes très petites (>0.0001). Cela indique que les trois effets (lipides, glucides et protéines) contribuent significativement à la prévision des calories.
Utilisez le profileur de prévision pour étudier l'impact des modifications apportées aux facteurs sur les valeurs prévues. Les droites du profil montrent la puissance de l'impact des modifications de facteur sur les calories. La droite de Total fat g est la plus inclinée, ce qui signifie que ce sont les modifications apportées aux lipides totaux qui ont le plus d'impact sur les calories.
Figure 5.30 Profileur de prévision


Remarque : Pour plus d'informations sur le Profileur de prévision, voir le chapitre Profiler dans Profilers.