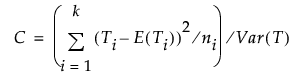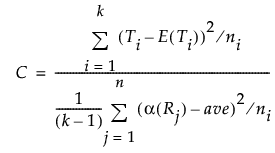Xの水準。kは水準の総数。
Xの第k水準における標本サイズ。
Rj
j番目の観測値の中間順位。中間順位は、同順位がない場合には、通常の順位です。同順位があった場合は、それらの同順位のものの順位の平均(中間値)です。
ブロック変数の水準。Bはブロックの総数。
Rbi
関数αは、以下のようにスコアを定義します。
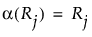
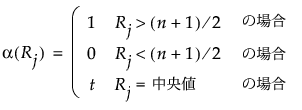
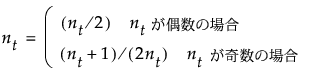
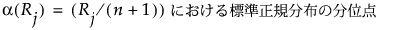
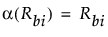
正規近似に基づく検定は、Xの水準が2つの場合にのみ行われます。この節で使用される表記については、第 “表記”を参照してください。「2標本検定(正規近似)」レポートに表示される統計量の定義は、以下のとおりです。
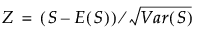
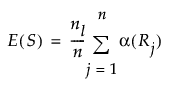
全観測値の平均スコアをaveとすると、 Sの分散は次の計算式で求められます。
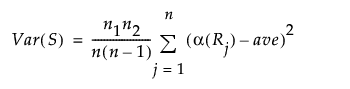
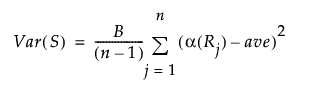
この節で使用される表記については、第 “表記”を参照してください。カイ2乗検定の統計量の計算には、次の値が使用されます。
Ti
Xのi番目の水準のスコアの合計。
i番目の水準の合計スコアの期待値。水準間に差はないという帰無仮説のもとで、次の式で表されます。
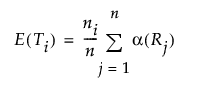
全観測値の平均スコアをaveとすると、 Tの分散は次の計算式で求められます。
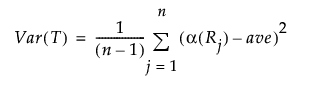
検定統計量は次の式で求められます。この統計量は、自由度k - 1のカイ2乗分布に漸近的に従います。