 非線形モデルにおける検出力の事前計算
非線形モデルにおける検出力の事前計算|
1.
|
実験のカスタム計画を作成します。第 “計画の作成”を参照してください。
|
メモ: カスタム計画は、非線形な状況に最適とはいえませんが、この例では、単純化するために、「非線形計画」プラットフォームではなく「カスタム計画」プラットフォームを使用します。「非線形計画」プラットフォームで作成した計画のほうが直交計画より優れていることを示す例については、『実験計画(DOE)』の「非線形計画」章を参照してください。
|
2.
|
|
3.
|
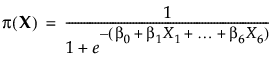
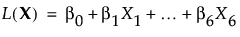
|
β0
|
|
|
β1
|
|
|
β2
|
|
|
β3
|
|
|
β4
|
|
|
β5
|
|
|
β6
|
線形予測子の切片は0なので、全因子が0に設定されている場合、部品が合格する確率は50%に等しくなります。i番目の因子における各水準に関連する確率は、その他の因子がすべて0である場合、次のようになります。
|
Xi = 1の場合の合格率
|
Xi = -1の場合の合格率
|
||
|---|---|---|---|
|
X1
|
|||
|
X2
|
|||
|
X3
|
|||
|
X4
|
|||
|
X5
|
|||
|
X6
|
 計画の作成
計画の作成
メモ: この節の手順を省略するには、 [ヘルプ]>[サンプルデータライブラリ]を選択し、「Design Experiment」フォルダの「Binomial Experiment.jmp」を開きます。「DOE シミュレート」 スクリプトの横にある緑色の三角形をクリックし、第 “[応答をシミュレート]の設定”に進んでください。
|
1.
|
[実験計画(DOE)]>[カスタム計画]を選択します。
|
|
2.
|
「因子」アウトラインで、「N個の因子を追加」の横のボックスに「6」と入力します。
|
|
3.
|
[因子の追加]>[連続変数]を選択します。
|
|
4.
|
[続行]をクリックします。
|
|
5.
|
「実験の回数」の「ユーザ定義」テキストボックスに「60」と入力します。
|
|
6.
|
「カスタム計画」の赤い三角ボタンをクリックし、メニューから[応答のシミュレート]を選択します。
|
|
7.
|
|
8.
|
|
9.
|
[計画の作成]をクリックします。
|
|
10.
|
[テーブルの作成]をクリックします。
|
図10.17 計画テーブル(一部)
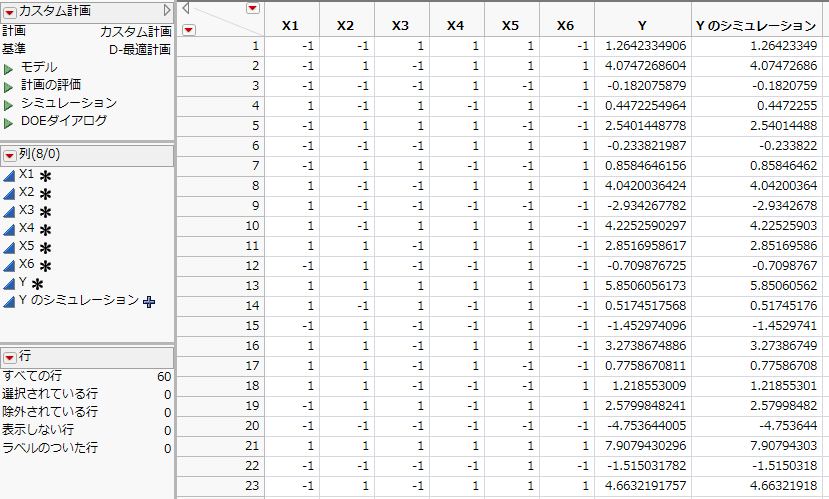
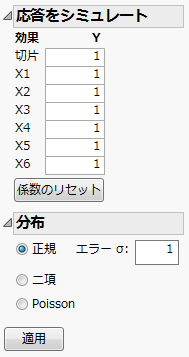
図10.18 「応答をシミュレート」ウィンドウ
|
–
|
「Y」列:「応答をシミュレート」ウィンドウの設定に従ってシミュレートされたデータ値。
|
|
–
|
「Yのシミュレーション」列:計算式が含まれており、その計算結果が表示されている。「応答をシミュレート」ウインドウでモデルを設定すると、そのモデルに従った乱数が生成されます。計算式を表示するには、「列」パネルで列名の右側にある+記号をクリックしてください。
|
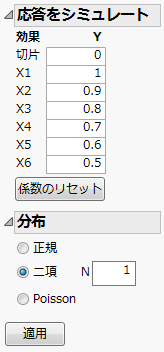
 [応答をシミュレート]の設定
[応答をシミュレート]の設定ここでは、二項分布に従う応答データをシミュレートします。成功率はロジスティックモデルに従うものとします。[応答をシミュレート]の詳細については、『実験計画(DOE)』の「カスタム計画」章を参照してください。
|
1.
|
|
–
|
「X1」は、デフォルト値の「1」を そのまま使います。
|
|
–
|
「X2」に「0.9」と入力します。
|
|
–
|
「X3」に「0.8」と入力します。
|
|
–
|
「X4」に「0.7」と入力します。
|
|
–
|
「X5」に「0.6」と入力します。
|
|
–
|
「X6」に「0.5」と入力します。
|
|
2.
|
「分布」アウトラインから[二項]を選択します。
|
「N」の値は「1」のままにしておきます。これは、それぞれの試行回数が1回だけであることを示します。
図10.19 設定後の「応答をシミュレート」ウィンドウ
|
3.
|
[適用]をクリックします。
|
|
4.
|
(オプション)「列」パネルで、「Yのシミュレーション」の右側にあ る+記号をクリックします。
|

|
5.
|
[キャンセル]をクリックします。
|
 一般化線形モデルのあてはめ
一般化線形モデルのあてはめ|
1.
|
データテーブルの「モデル」スクリプトの横の緑の三角ボタンをクリックします。
|
|
2.
|
|
3.
|
「Yのシミュレーション」をクリックし、[Y]ボタンをクリックします。
|
応答変数Yとして、二項分布に従う乱数の列が設定されます。
|
4.
|
「手法」のメニューから[一般化線形モデル]を選択します。
|
|
5.
|
[分布]メニューから[二項]を選択します。
|
|
6.
|
[実行]をクリックします。
|
 検出力の考察
検出力の考察第 “この例での計画”では、線形予測子および係数と、係数によって決められる確率を示しました。ここでは、それらの係数に対する検出力を求めます。
|
1.
|
図10.21 「シミュレーション」ウィンドウ
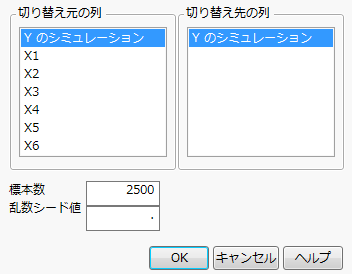
「切り替え元の列」の「Yのシミュレーション」は、モデルの推定に使用されたデータ値を含んでいます。「切り替え先の列」でも「Yのシミュレーション」を選択すると、切り替え元の「Yのシミュレーション」データ値を、「Yのシミュレーション」の計算式で指定されている乱数に置き換えて、シミュレーションが実行されます。
レポートで選択した「p値(Prob>ChiSq)」列は、「係数がゼロである」という帰無仮説に対する尤度比検定のp値です。「効果の検定」表にある、各効果に対するこの「p値(Prob>ChiSq)」をシミュレートしましょう。
|
2.
|
「標本数」に「500」と入力します。
|
|
3.
|
|
4.
|
[OK]をクリックします。
|
図10.22 「シミュレーション結果」テーブル(一部)

テーブルの最初の行は、観測されたデータから得られた「p値(Prob>ChiSq)」であり、除外の状態になっています。2行目以降の500行は、シミュレーションしたデータから計算された結果です。
|
5.
|
「検出力の分析」スクリプトを実行します。
|
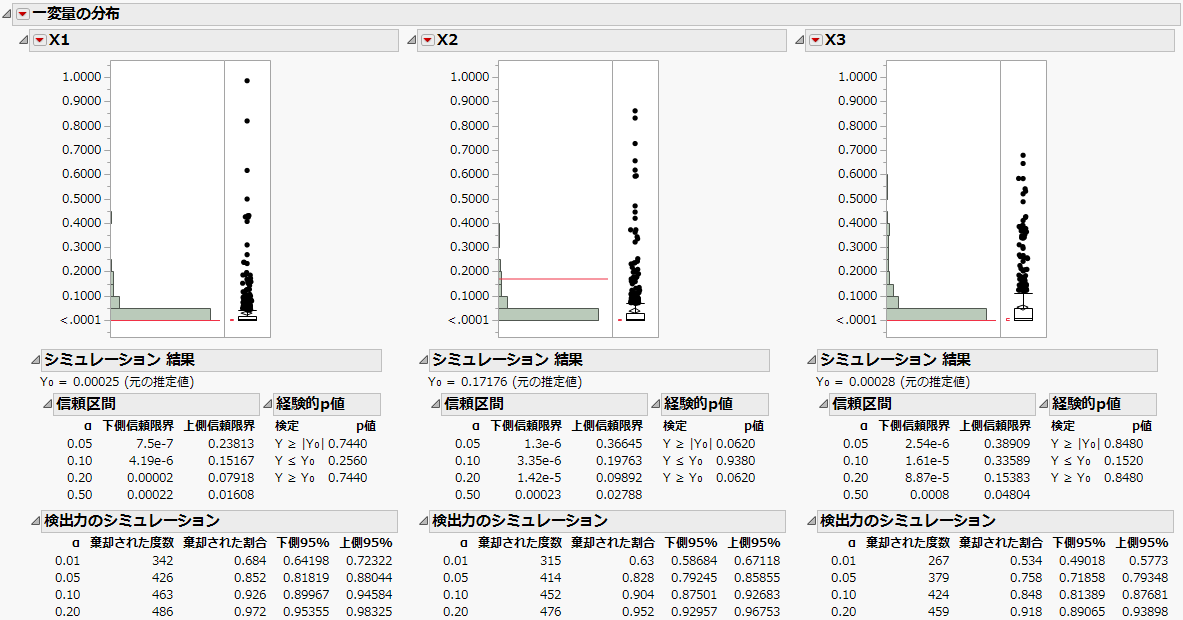
図10.23 一変量の分布(最初の3つの効果)
|
6.
|
「一変量の分布」の赤い三角ボタンをクリックし、[積み重ねて表示]を選択します。
|
|
7.
|
|
8.
|
図10.24 検出力(最初の3つの効果)
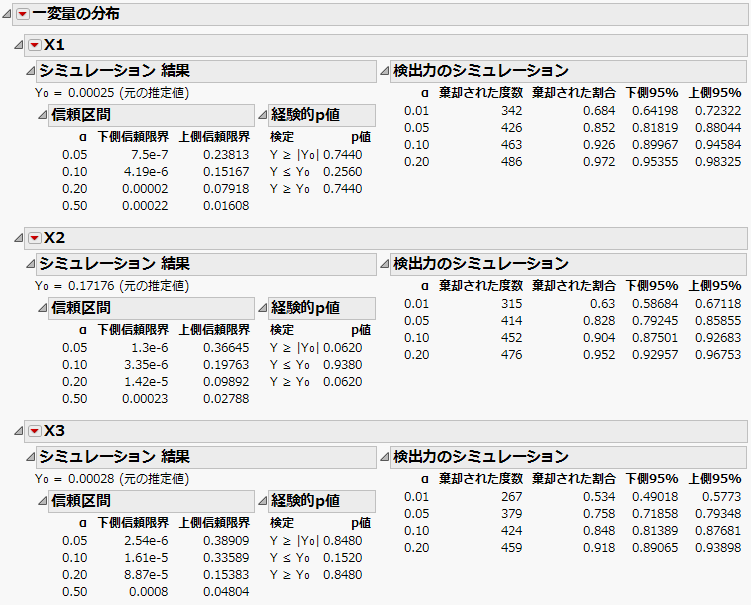
「検出力のシミュレーション」アウトラインの「棄却された割合」は、シミュレーションのうち、p値がαより小さくなったものの割合を示します。たとえば、係数が0.8、確率の差が38%である「X3」で、棄却された割合を見てみると、有意水準0.05の検定で379/500 = 0.758となっています。検出力のシミュレーション(有意水準0.05)シミュレーションで計算された、有意水準0.05の検定に対する検出力を、効果ごとに示したものです。「検出したい差」が小さくなるにつれ、検出力も小さくなっています。たとえば、「検出したい差」が24.5%(X6)における検出力は、約0.37にとどまっています。
|
シミュレーションで得られた検出力(α=0.05で棄却された割合)
|
||||
|---|---|---|---|---|
|
X1
|
||||
|
X2
|
||||
|
X3
|
||||
|
X4
|
||||
|
X5
|
||||
|
X6
|